
Co-founder & COO @OpenRouterAI
Joined April 2007
- Tweets 1,314
- Following 754
- Followers 1,079
- Likes 318
74 Photos and videos












Jun 13
Lots of work from the team on this one! Timing is coincidental 🫣
Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

1
8
478
Jun 10
Fable sneakily giving bad advice if it thinks you are making competitive models reminds of:
1. The Sophons from the three body problem
2. Arnold giving advice to Lou Ferrigno in Pumping Iron.
3
75
May 26
Companies are very excited to have managers with (thanks to AI) a zillion direct reports. Do we think that is actually *better*, or is it just *cheaper*?
3
177
May 12
When I’m king, gate numbers will always correspond to how far away they are from the terminal entrance
3
199

Apr 30
We built a great AI writing detector but unfortunately it’s not very scalable. @pingToven can only read so much :(
1
1
5
443
Chris Clark retweeted

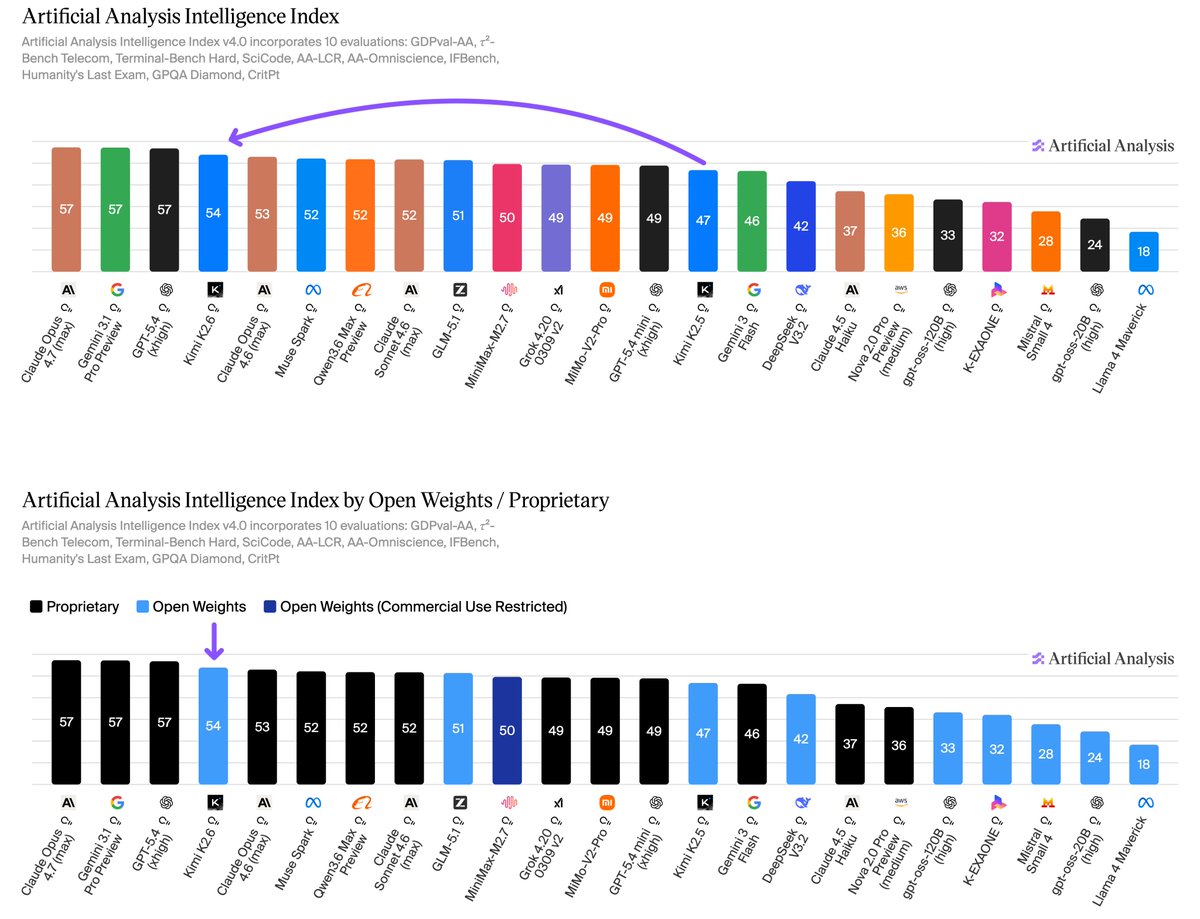
Moonshot’s Kimi K2.6 is the new leading open weights model. Kimi K2.6 lands at #4 on the Artificial Analysis Intelligence Index (54) behind only Anthropic, Google, and OpenAI (all 57)
Key takeaways:
➤ Increase in performance on agentic tasks: @Kimi_Moonshot's Kimi K2.6 achieves an Elo of 1520 on our GDPval-AA evaluation, which is a marked improvement over Kimi K2.5’s Elo of 1309. GDPval-AA is our leading metric for general agentic performance, measuring the performance on knowledge work tasks such as preparing presentations and analysis. Models are given code execution and web browsing tools in an agentic loop via our open source reference agentic harness called Stirrup. This continues Kimi K2.6’s strength in tool use, maintaining a 96% score on τ²-Bench Telecom, placing it among other frontier models in this category.
➤ Low hallucination rate: Kimi K2.5 scores 6 on the AA-Omniscience Index, our knowledge evaluation measuring both accuracy and hallucination rate. This score is primarily driven by a comparatively low hallucination rate of 39% (reduced from Kimi K2.5’s 65%), indicating a greater capability to abstain rather than fabricate knowledge when the model is uncertain. Kimi K2.6’s low hallucination rate places it similarly to other models such as Claude Opus 4.7 (36%) and MiniMax-M2.7 (34%)
➤ High token usage: Kimi K2.6 demonstrates high token usage, but is in line with other frontier models in the same intelligence tier. To run the full Artificial Analysis Intelligence Index, Kimi K2.6 used ~160M reasoning tokens. This is slightly lower than Claude Sonnet 4.6 (~190M reasoning tokens) but much higher than GPT 5.4 (~110M reasoning tokens).
➤ Open weights: Kimi K2.6 is a Mixture-of-Experts (MoE) model with 1T total parameters and 32B active, same as the previous two generations of models Kimi K2 Thinking and Kimi K2.5. Kimi K2.6 again pushes the open weights frontier in intelligence.
➤ Third Party Access: Kimi K2.6 is accessible through Moonshot’s First Party API as well as third party API providers Novita, Baseten, Fireworks, and Parasail
➤ Multimodality: Kimi K2.6 supports Image and Video input and text output natively. The model’s max context length remains 256k.
Further analysis in the threads below.
31
131
1,249
210,796
Mar 25
Seems like when most people talk about ARR they really mean ARRR - annualized revenue run-rate. I propose we start using this metric more broadly, and that we distinguish between it and ARR by saying ARRR in a pirate voice.
1
2
495
Mar 19
thanks to coding agents it's never been easier to get started, and never been harder to get finished.
1
6
365
Mar 17
In a moment of frustration, I banned my 8-year-old from saying “I’m bored” and he now has to say “time to figure out a new activity” and it’s been weirdly effective. Also I’ve threatened to take away dessert if he says it. That also is def part of the success recipe.
3
168
Mar 13
If the east wing ballroom had been constructed by Obama, what kind of impact would that have had on the plot of White House Down?
2
140
Mar 12
Bullish on the Workdays of the world. Well-structured line-of-business software and effective systems of record are not going anywhere. Good data structures, with mature APIs, are the perfect systems for agents to interact with, and not create a mess in their wake. AI doesn't need to live inside the tool, and building properly governed enterprise software is not trivial.
1
2
153
Mar 12
With models training on other model outputs — feels like only a matter of time — before model outputs — are primarily — dominated — by ———
3
110
Mar 12
Whoa! Exciting! Congrats to all involved and look forward to using the resulting products!
Mar 12

We're proud to lead @axiommathai's $200M Series A at a $1.6B valuation!
Mathematics is the right foundation for AI that can truly reason. Seven months in, @CarinaLHong and her team have proven it, and we're betting that verified, safe code will become as essential as generating it.
Read more: mnlo.vc/axiom-series-a
1
3
1,579