
Create and Control Your AI Workloads On Any Compute.
Joined March 2014
- Tweets 10,428
- Following 2,124
- Followers 10,920
- Likes 8,713
4,875 Photos and videos











Clarifai retweeted

May 13
Huge news: Clarifai has agreed to license our AI inference & compute orchestration IP — plus the patent portfolio behind it – to @nebiusai.
Our core team is joining them to keep building.
Our technology becomes a key part of Nebius Token Factory, the inference platform inside their full-stack AI cloud. Faster inference. Bigger scale.
Can't wait to ride this rocket ship and build the foundation for the next decade of AI inference. 🚀

10
16
163
36,013

NVIDIA Nemotron 3 Nano Omni is now available on Clarifai with Zero Day support.
A 30B A3B multimodal reasoning model built for agent workflows across documents, images, video, audio, and text.
Why it stands out:
• Multimodal input across text, image, video, and audio
• Hybrid MoE Transformer-Mamba architecture
• 300K context window
• Runs on a single H100, H200, or B200
• 400 tokens/sec on Clarifai Reasoning Engine
2
4
12
1,858
Learn more about Nemotron 3 Nano Omni here: clarifai.com/blog/nvidia-nem…
327
Qwen3.6-35B-A3B is now live on Clarifai. 🚀
The model delivers frontier-level agentic coding performance with a MoE architecture that only activates 3B out of 35B total parameters per token.
Apache 2.0 licensed and runs locally.
Key capabilities:
- 73.4% on SWE-Bench Verified for real-world GitHub issue resolution
- 51.5% on Terminal-Bench 2.0 (highest among open models)
- 37.0% on MCPMark for tool use and function calling
- Multimodal support (text, image, video)
- 262K native context, extendable to 1M tokens
- Thinking Preservation: retains reasoning traces across multi-turn conversations for better agent consistency
Access via API or deploy on your own dedicated compute.
1
4
494
Clarifai 12.3: Introducing KV Cache-Aware Routing! 🚀
LLM inference with multiple replicas typically uses random load balancing. But replicas aren't interchangeable. Each builds up different KV cache state from the requests it processes.
When requests land on replicas without relevant context cached, models recompute everything from scratch. This wastes GPU cycles and increases latency.
KV Cache-Aware Routing automatically detects prompt overlap and routes requests to replicas with relevant cache state already loaded. Shared system prompts are computed once and reused. RAG context is cached when multiple users query similar documents.
Zero configuration required. Deploy a model with multiple replicas and it works.
Also new: Warm Node Pools for faster scaling, Session-Aware Routing to keep user requests on the same replica, Prediction Caching for identical inputs, and Clarifai Skills for AI coding assistants.
Read the full release blog: clarifai.com/blog/clarifai-1…
1
4
293
Do you feel the need for speed?
Come learn how Clarifai breaks speed records for inference across multiple models at Booth #405 at #humanx.

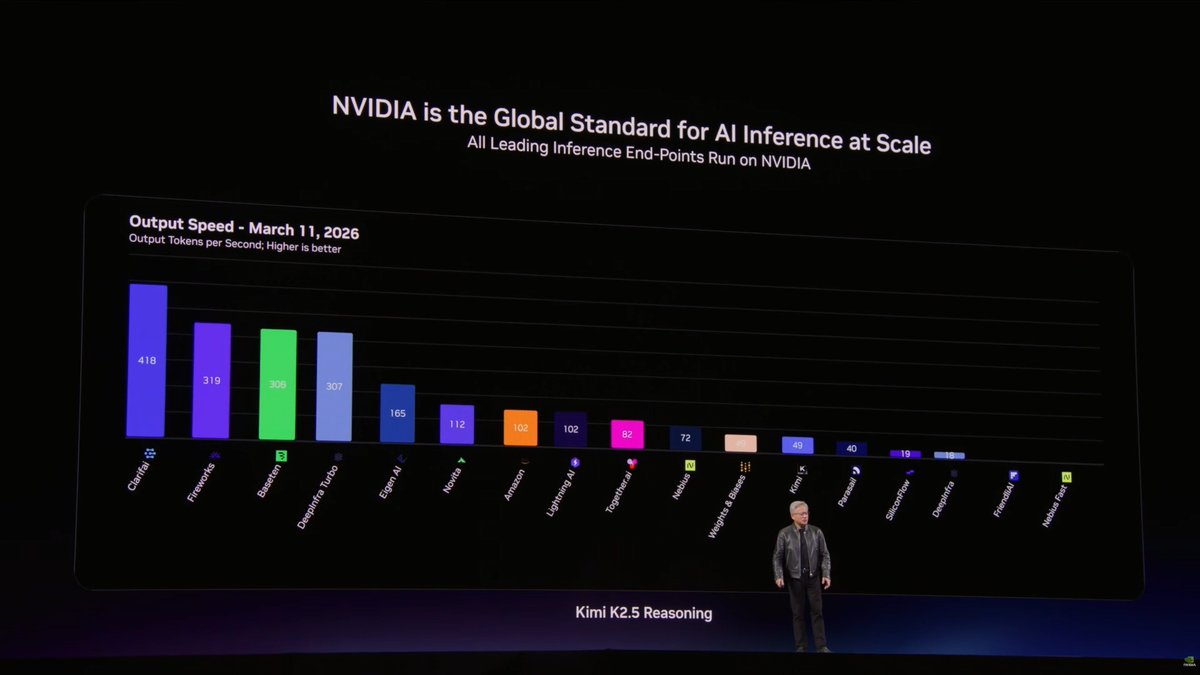
⚡ In just 10 days, leading inference providers propelled Kimi K2.5 up the @ArtificialAnlys leaderboard by adopting key elements of NVIDIA’s Inference Reference Architecture.
Incredible work by @basetenco, @clarifai, @DeepInfra, @Eigen_AI_Labs, @FireworksAI_HQ, @friendliai, @LightningAI, @nebiusai, @togethercompute, @wandb by @CoreWeave.
From custom kernel optimizations to NVFP4, disaggregated serving, and speculative decoding, this extreme full-stack co-design of the NVIDIA Blackwell platform is driving major gains in both performance and efficiency.
The result? The lowest token cost at scale.
Get started with your preferred NVIDIA partner or explore our Inference Reference Architecture documentation ➡️ nvda.ws/4twlPIH
1
3
3
710
Day 2 at HumanX! 🚀
Clarifai Reasoning Engine is running at booth #405. Custom CUDA kernels, speculative decoding optimized for reasoning workloads, and adaptive optimization.
That's how we deliver 500 TPS on Kimi K2.5 and lead on Qwen3.5 and other top reasoning models benchmarked by Artificial Analysis.
But software optimization is only half the story. Tomorrow at 11 AM, Alfredo Ramos (our CPTO) is presenting with @Vultr on the infrastructure side: how to design network architecture that scales from edge deployments to hyperscale data centers for AI workloads.
Vultr Theatre Session at booth #825.
2
2
213
Day 1 at HumanX! 🚀
Clarifai is at booth #405 showing how we're running reasoning models in production.
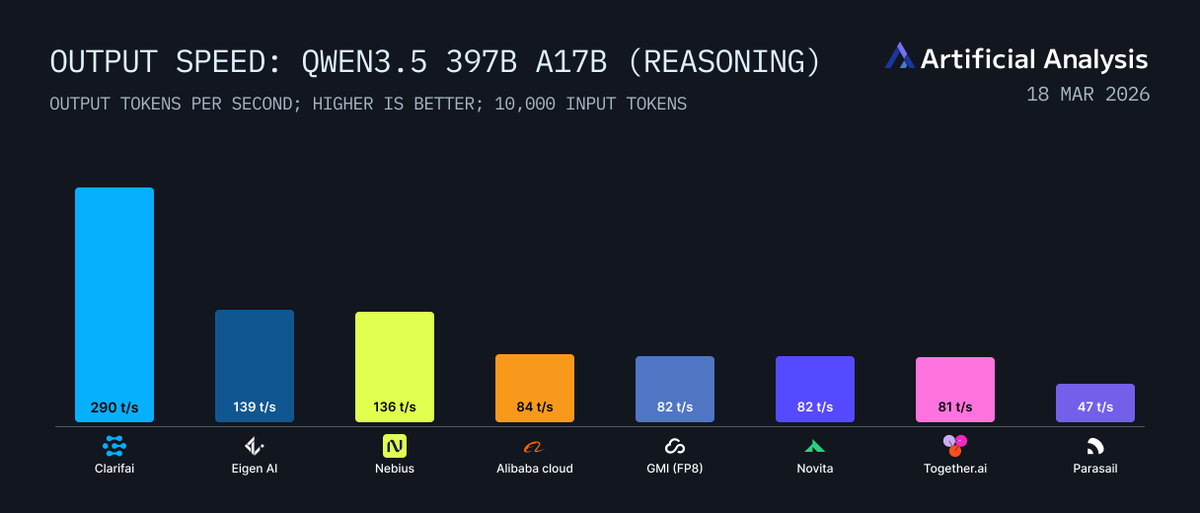
We hit 500 TPS on Kimi K2.5 - first provider to cross that threshold - and we're currently leading on Qwen3.5 at 290 TPS on Artificial Analysis benchmarks.
Getting that performance requires more than optimized inference code. You need network infrastructure built for AI workloads from the ground up.
Tomorrow at 11 AM, our VP of Strategy Sajai Krishnan is presenting on exactly that: building AI data centers that can handle edge to hyperscale deployments.
@Vultr Theatre Session at booth #825.
1
4
198
Vendor lock-in is the biggest AI infrastructure risk nobody's planning for.
The attempted federal ban on Anthropic in late February exposed what happens when you build your entire AI stack on a single vendor. Government agencies and contractors scrambled overnight. The ban was blocked by a federal judge as illegal retaliation, but the lesson stands: you're one policy decision away from a forced migration.
Building on a single API means when that vendor becomes unavailable, you're rebuilding from scratch. Claude today. GPT tomorrow. Gemini if you have to. Your infrastructure should handle that swap without breaking.
That's how Clarifai is built. Deploy any open-source reasoning model on your own infrastructure - Kimi K2.5, Qwen3.5, GLM, or your own fine-tuned models.
We're leading on Kimi K2.5 and Qwen3.5 on Artificial Analysis benchmarks because the infrastructure is purpose-built for reasoning workloads, not locked to a single model.
Build your AI stack so you can swap the engine without rebuilding the car.
2
2
271
One week until HumanX 2026. 🚀
Clarifai is bringing production-ready AI infrastructure to San Francisco April 6-9.
We're now leading on both Kimi K2.5 (500 TPS) and Qwen3.5-397B (290 TPS), benchmarked by Artificial Analysis.
Deploy any AI model, on any compute, at any scale. Our platform handles the complexity - from compute optimization to production inference.
See Clarifai Reasoning Engine live at booth #405. Schedule time with the team here.
2
1
240
Clarifai is heading to HumanX 2026 in San Francisco. 🚀
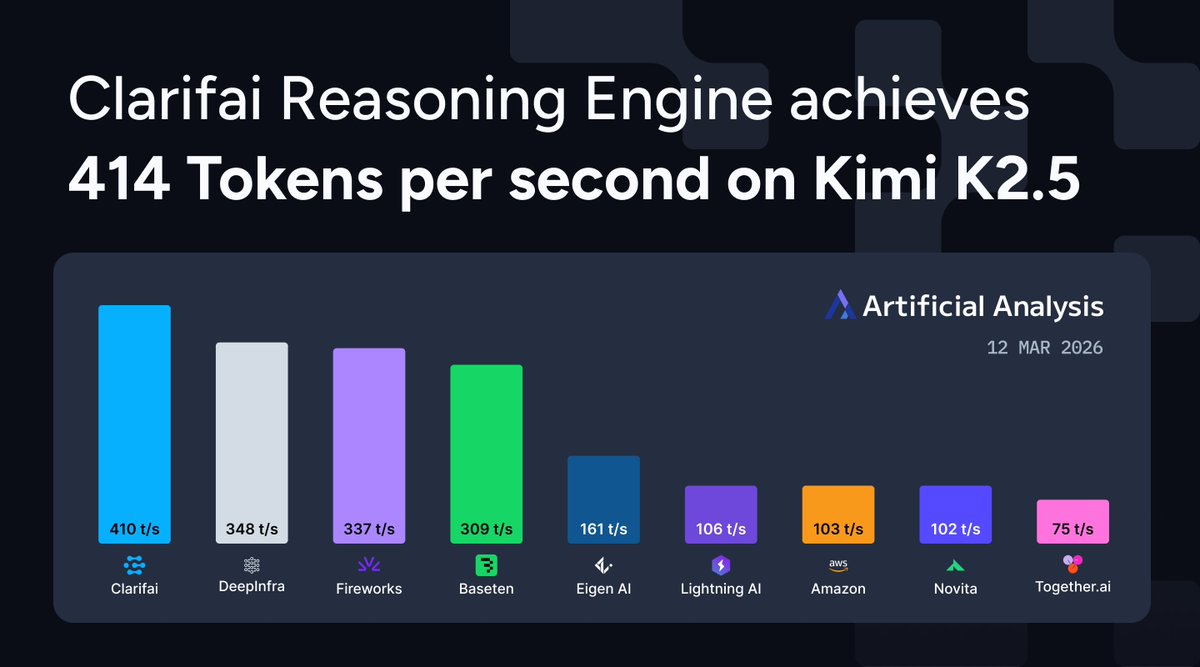
At GTC this week, we announced 414 tokens per second on Kimi K2.5 - first provider to reach this performance. We're also leading on Qwen3.5-397B with 290 TPS, benchmarked by Artificial Analysis.
Now we're bringing that momentum to #HumanX April 6-9.
Come see how Clarifai Reasoning Engine delivers production-ready performance for reasoning models and agentic workloads.
Find us at booth #405 or schedule time with Matthew Zeiler, Sajai Krishnan, or Douglas Shapiro.
Book a meeting here: clarifai.com/clarifai-at-hum…
3
357
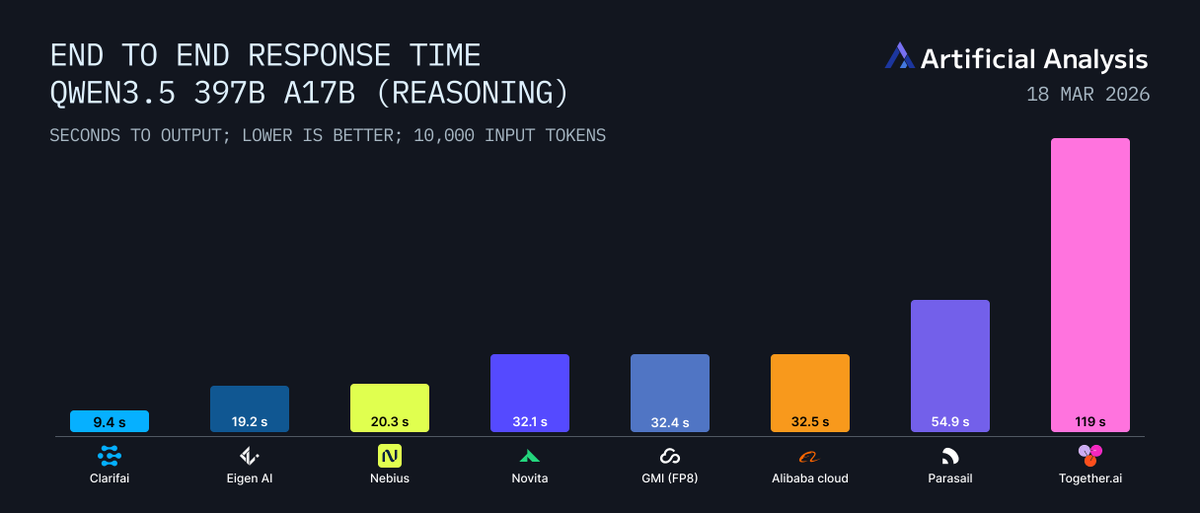

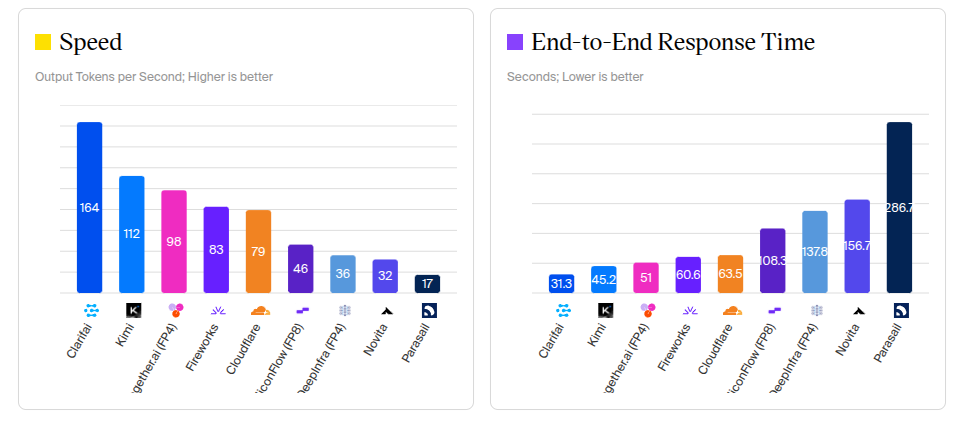
Verified on @ArtificialAnlys - check out the performance stats here: artificialanalysis.ai/models…
1
1
121
If you're at GTC, meet with us to see the speed first hand.
clarifai.com/clarifai-at-gtc…
111
Day 2 at GTC. 🚀
Clarifai Reasoning Engine hit 410 tokens per second on Kimi K2.5, making us one of the first providers to break the 400 TPS barrier on a trillion-parameter reasoning model.
We're also running strong benchmarks on MiniMax M2.5, Qwen3.5, and GPT-OSS-120B. Production-ready performance for reasoning workloads. ⚡
1
3
276