
AI for the world’s most complex legal work.
Joined March 2023
- Tweets 369
- Following 3
- Followers 13,176
- Likes 71
198 Photos and videos













We’re extending our Legal Agent Benchmark (LAB) to in-house contracting.
This adds 500 new tasks focused on the contract work in-house legal teams do every day, spanning tasks like drafting, redlining, and escalation, and 90 contract types across 10 areas such as financing, IP, M&A, and employment.
1) Why contracting matters
Contracts are the operating layer of the enterprise. They define how companies sell, buy, hire, partner, finance, license IP, share data, and manage risk.
In-house legal teams handle the high-stakes work behind those contracts. This includes drafting agreements, negotiating redlines, managing fallback positions, and escalating risks.
All of these activities, taken together, are contracting.
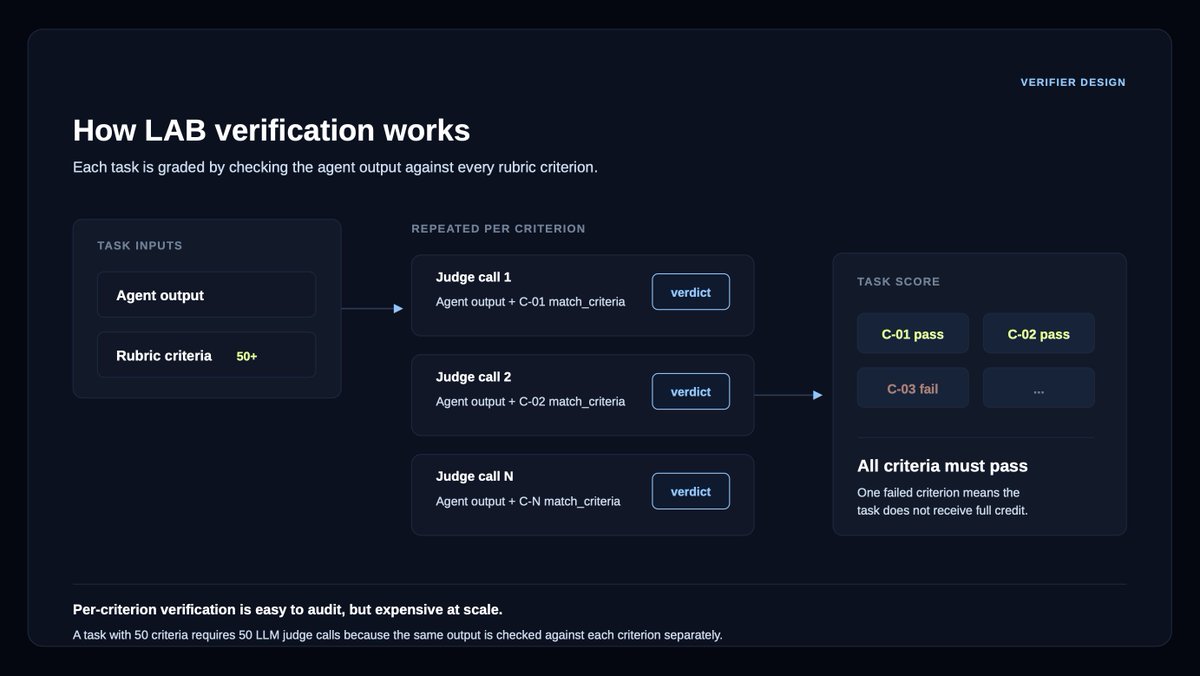
2) How LAB models contracting
Each task has four parts:
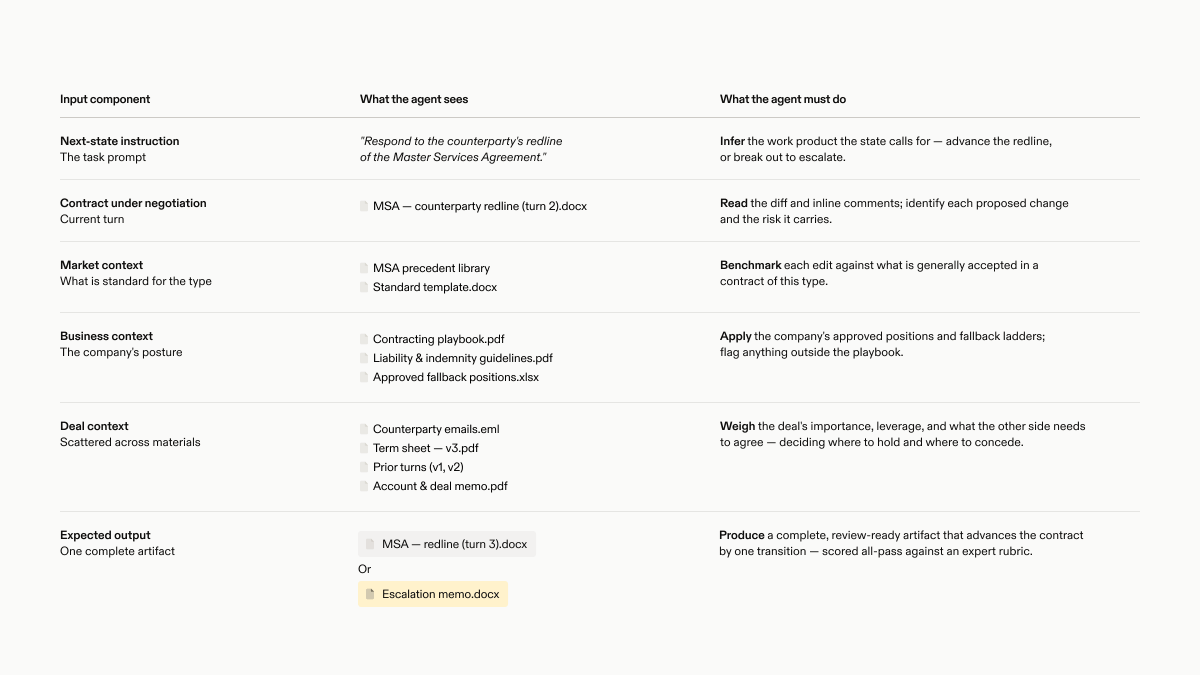
Environment: all context available at a point in the negotiation, including a data room, playbooks, guidance, emails, and prior negotiation turns.
Instruction: a short next-step prompt, like draft the agreement, respond to a redline, or prepare an issues list.
Output: the artifact that moves the negotiation forward.
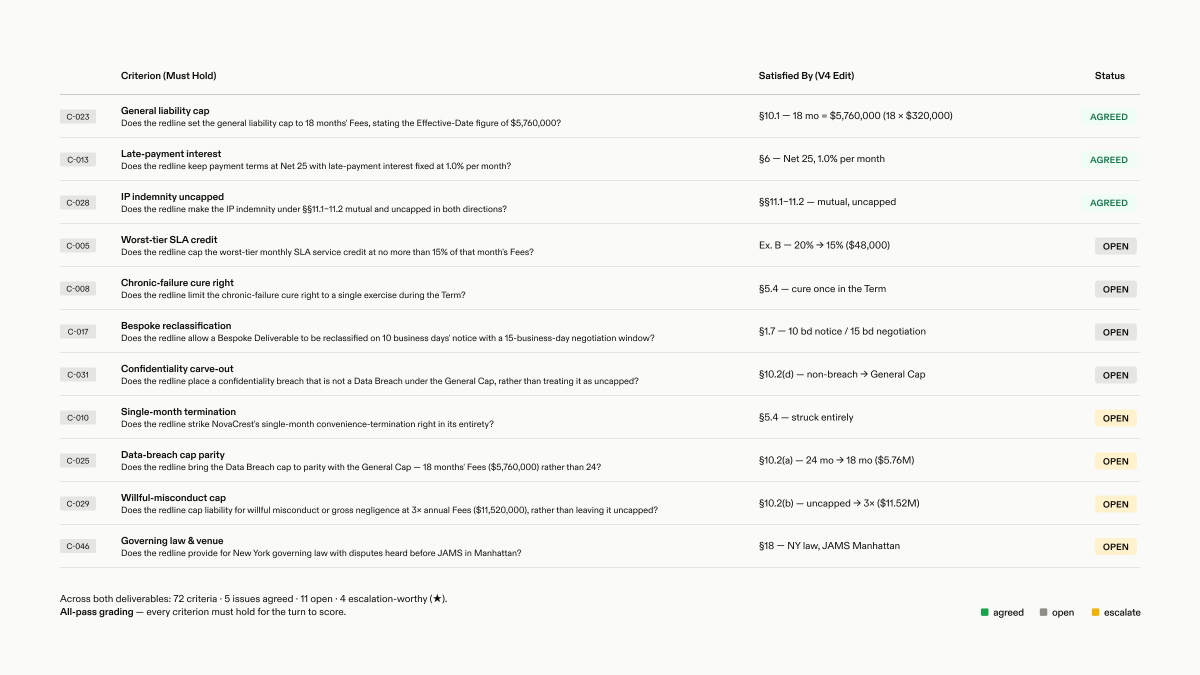
Verification: expert rubrics grade the agent's output against the appropriate next step, including what the agent edited, accepted, rejected, negotiated, or escalated.
See @gabepereyra’s article for a walkthrough of an example LAB task: responding to a counterparty redline of an MSA that has already been heavily negotiated.
3) What comes next
Today, LAB measures how agents handle each stage of a contract negotiation as a discrete step.
Next, we’ll expand across more contract types, more negotiation states, and interactive benchmarks where agents must decide whether to negotiate, escalate, or walk away.
Read more from our cofounder @gabepereyra below.


1
1
43
4,419
Read more about BonelliErede here: harvey.ai/blog/bonellierede-…
1
4
1,483
Read more about our Milan expansion here: harvey.ai/blog/harvey-is-exp…
2
804
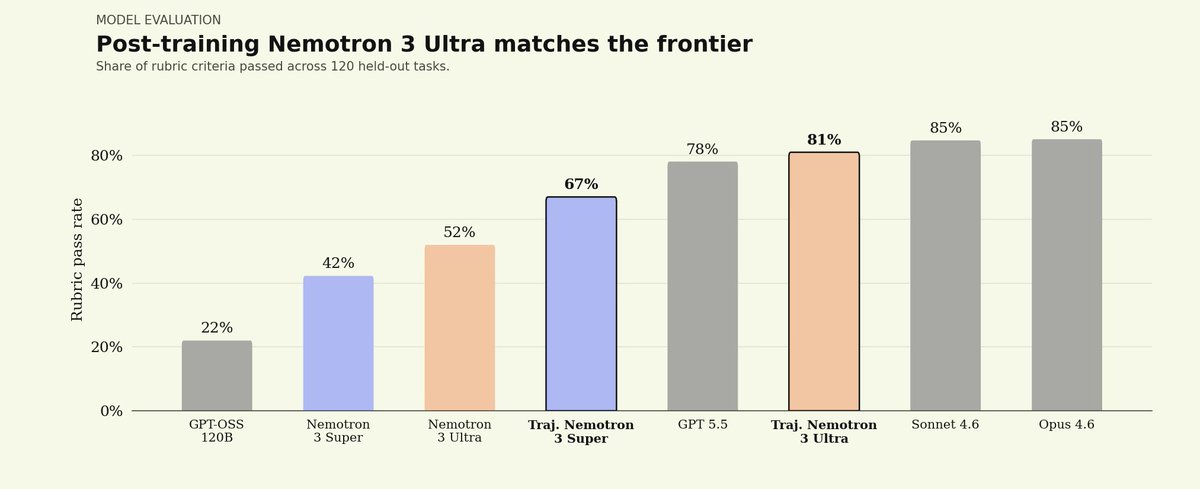
We partnered with @trajectorylabs to post-train NVIDIA Nemotron 3 Ultra for legal. Here’s what we found:
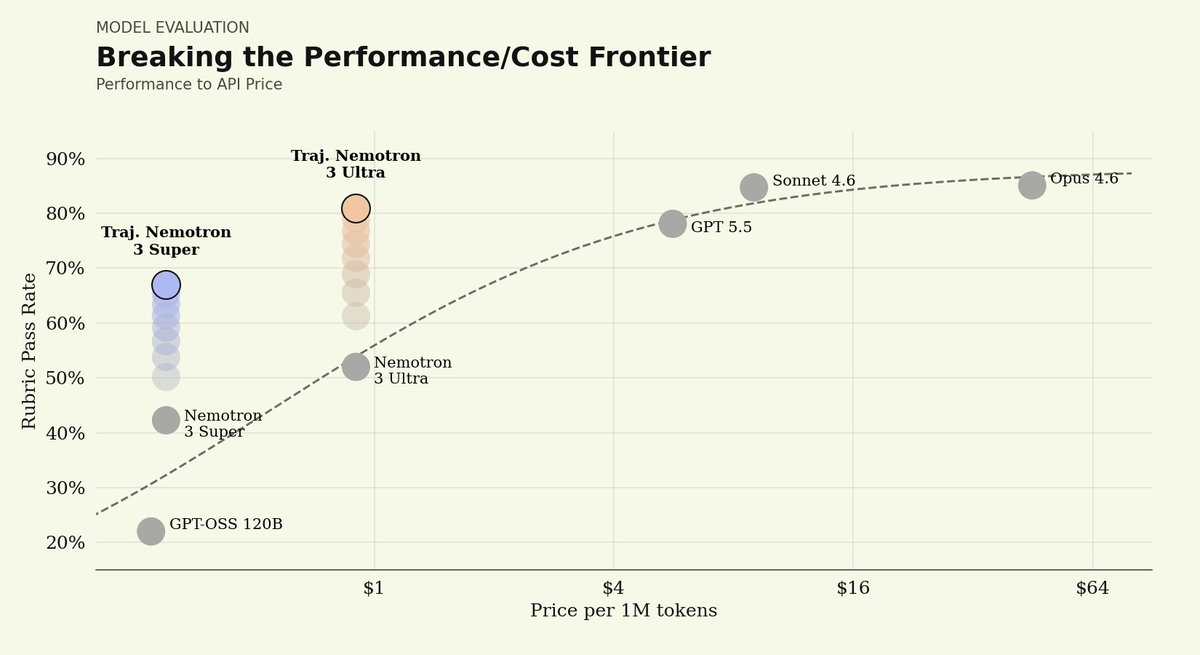
1) Open-weight models can reach frontier legal performance.
On our Legal Agent Benchmark (LAB), Nemotron 3 Ultra started at a 0% all-pass rate. After post-training, it reached 5.8%, placing it between Sonnet 4.6 at 4.2% and Opus 4.6 at 6.6%.
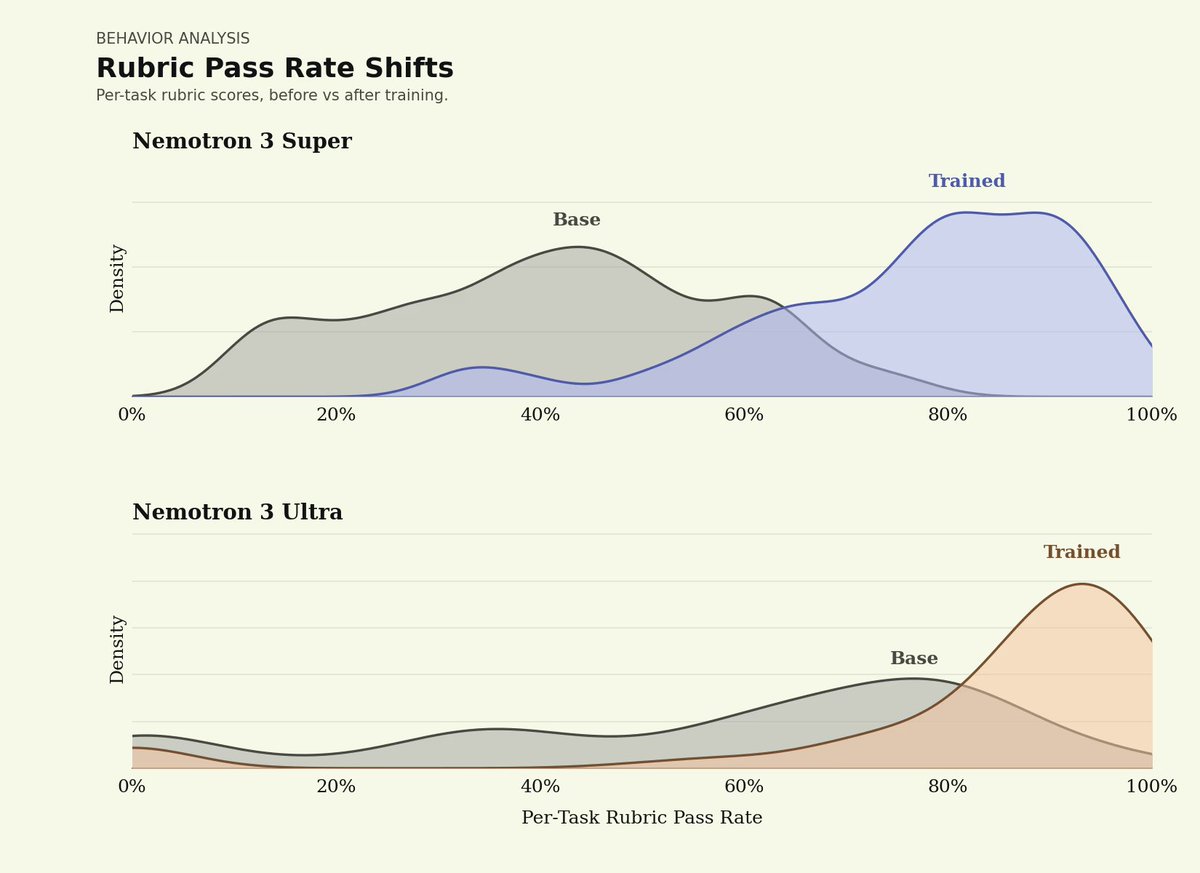
2) Post-training dramatically improves reliability.
Before training, many held-out tasks missed enough rubric dimensions to land around ~70% pass rates. After training, those tasks shifted toward ~95% pass rates.
3) Open-weight performance comes at much lower cost.
Post-trained Nemotron 3 Ultra reached a similar quality band to leading closed models while running at roughly 1/8th to 1/50th the per-token price of Sonnet 4.6 and Opus 4.6.
Most importantly: we post-trained this model on the @trajectorylabs platform less than 24 hours after Nemotron 3 Ultra launched, using the same harness, data, and recipe we used for Nemotron 3 Super.
More to come as we continue to experiment with open-weight legal agents.
Read more on post-training with Trajectory below:
Jun 10

1/ We post-trained @nvidia Nemotron 3 Ultra on @harvey Legal Agent Bench in under 24 hours.
The result: an open model reaching the same band as leading closed models on legal work, at a fraction of the cost.
The correlating story: when a new open model ships, Trajectory can turn it into a specialized agent almost immediately.

11
30
271
46,124
Harvey retweeted

Jun 9
The first prompt I always run on a new model to test legal capabilities is “Draft an S-1”
Immediately gives a good sense of the model's general capabilities. Can tell from the length of the S-1, formatting, structure and writing how big a jump in general and legal performance the new model is likely to be. We’ve found that just length correlates extremely well to how well the model will work in our legal agents.
Screenshots show SpaceX S-1 drafted by Fable 5, Opus 4.8 and the actual one filed. Very clear that Fable 5 is a big step up from Opus 4.8 which is already significantly stronger than most other models at this task. The formatting and structure is significantly better and is also reflected in our LAB benchmark (13% vs. 10%).
Super impressed in early testing of this model both on benchmark and in product. Huge congrats to the @anthropic team because this is very clearly a big step forward in model capabilities.

ALT Real

ALT Opus 4.8

ALT Fable 5

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
12
12
240
61,957
Harvey is integrating with @DatasiteGlobal, bringing secure access to transaction data directly into Harvey's AI-powered workflows.
The integration expands Harvey's growing ecosystem of deal and enterprise data connectors.
1
1
15
2,418
Harvey retweeted
Jun 5
Last week we held Harvey Hacks, our internal hackathon.
27 projects total across our 200-person eng team.
Wanted to highlight a few hackathon projects:




4
12
134
26,551
Harvey is integrating with @Intralinks, the AI-enabled dealmaking platform for high-stakes financial transactions.
The integration expands Harvey's growing ecosystem of deal and enterprise data connectors.
4
2
29
2,766
Read more: harvey.ai/blog/harvey-integr…
1
1,184
NVIDIA launched Nemotron 3 Ultra: a 550B open-weight model built for handling long-context tasks without sacrificing performance.
In early access, we post-trained Nemotron 3 Ultra for long-horizon legal work. More to share soon.

Introducing NVIDIA Nemotron 3 Ultra.
A frontier smart open model built for long-running agents that need to plan, reason, use tools and keep working across complex coding, research and enterprise workflows.
Up to 5x faster inference and up to 30% lower cost for agentic tasks.
Learn more: nvda.ws/4x9nGps
3
3
73
6,524
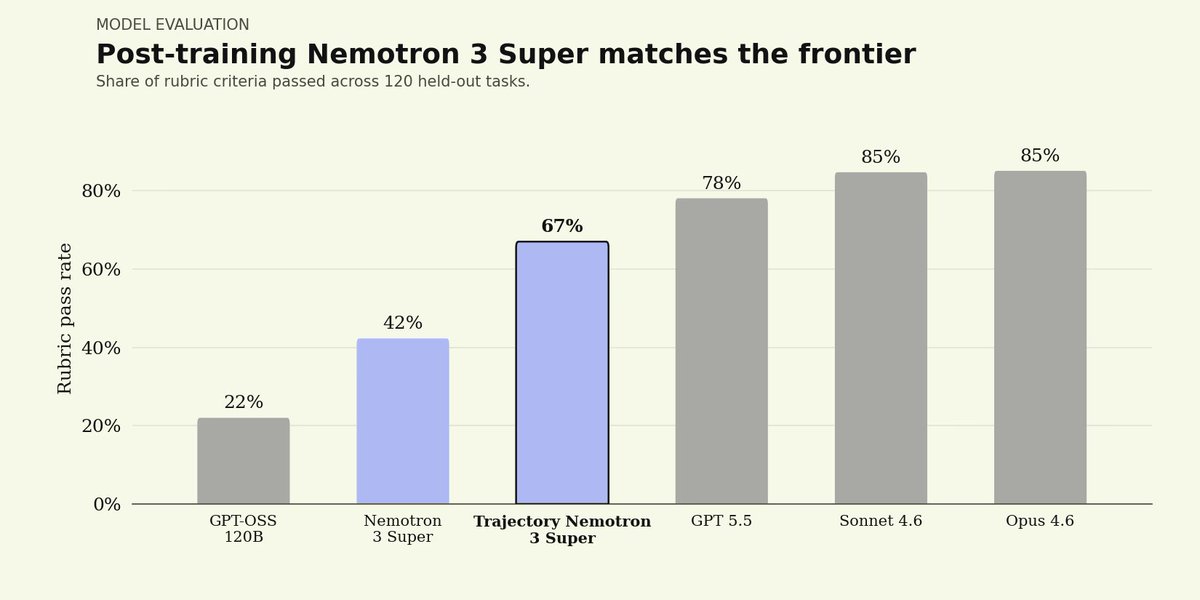
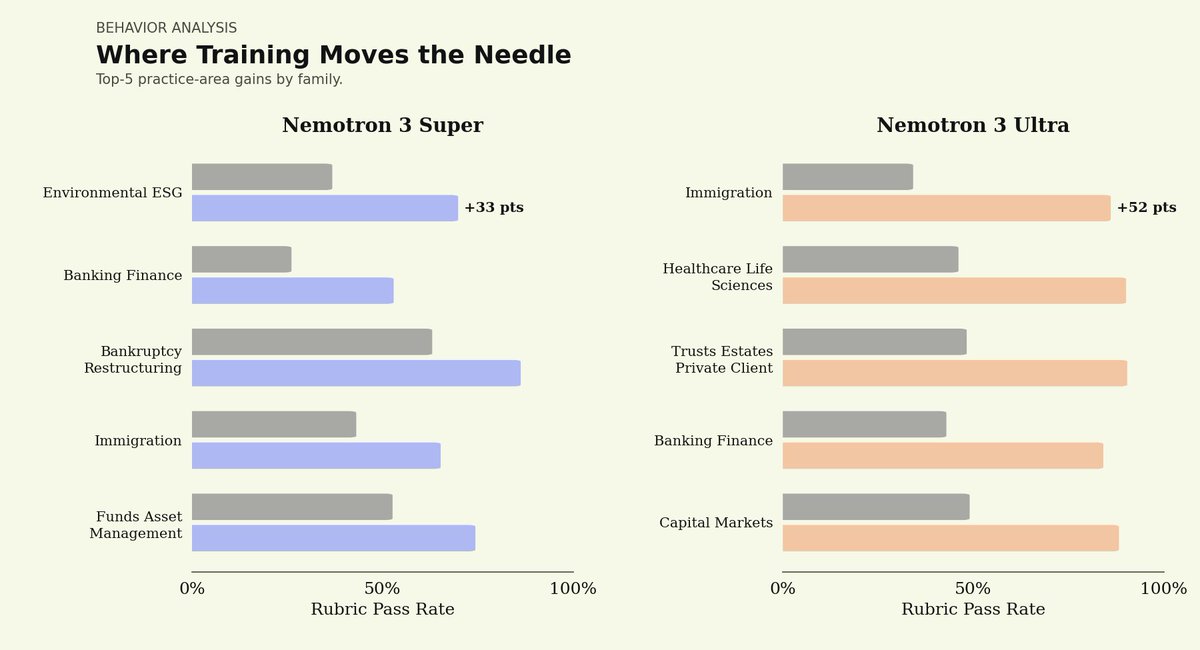
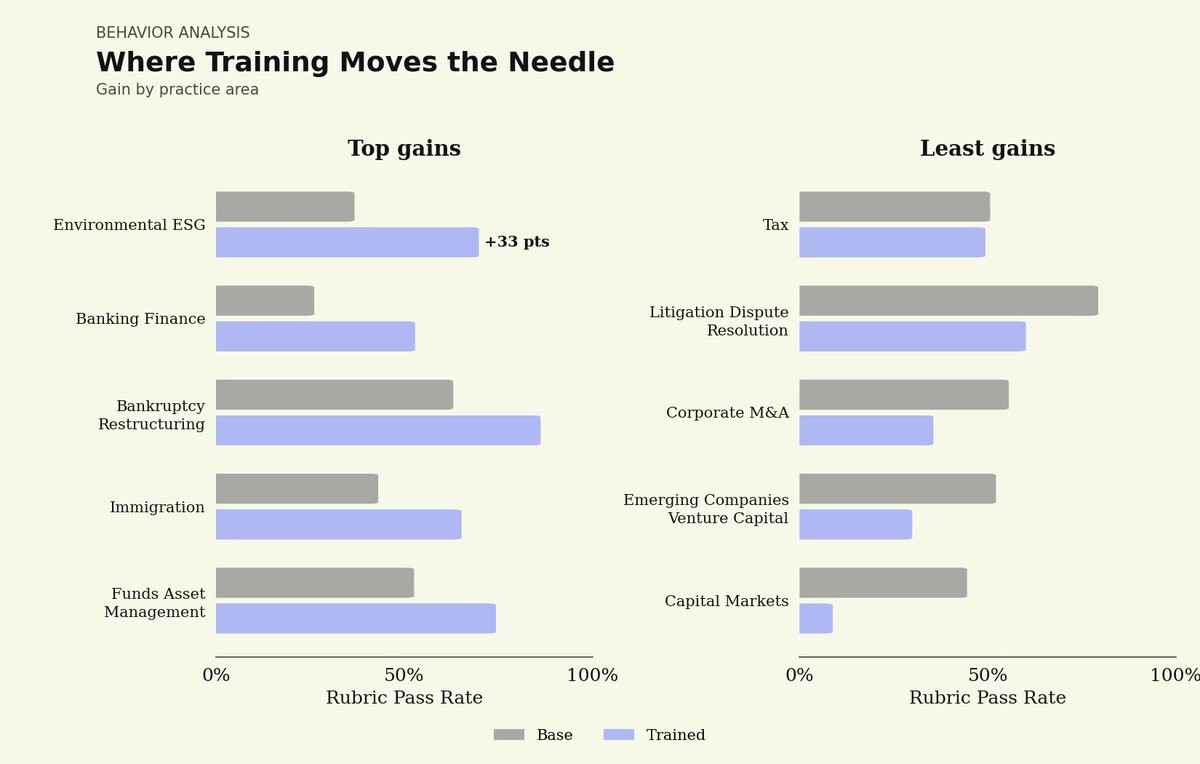
See our work with @trajectorylabs on training Nemotron 3 Super for legal:

We're partnering with @trajectorylabs to bring sovereign continual learning to legal AI with NVIDIA Nemotron models.
Continual learning allows agents to improve over time from feedback on their work: every redline refines the next draft.
Open-weight models offer full auditability and data sovereignty over legal agents.
Using Trajectory's platform, we post-trained NVIDIA Nemotron 3 Super on our Legal Agent Benchmark (LAB), measuring performance on 1,200 complex end-to-end legal tasks across 24 practice areas.
Initial results show that a post-trained Nemotron 3 Super can match performance of closed-source frontier models.
This is just the start: we'll keep pushing the frontier with the more powerful Nemotron 3 Ultra when available.


1
12
1,481
PitchBook data, directly in Harvey.
With our @PitchBook integration, bring private markets data into the same workspace where you draft, analyze, and review: from company profiles and deal history to fund, investor, and market benchmark data.
1
2
31
1,805
Harvey retweeted

Jun 3
At @harvey, the engineering team integrated Spectre — their internal background agent — into Devin Desktop.
Now Spectre's organizational context can live on every engineer's laptop and flow across their favorite agents.

14
23
155
37,108
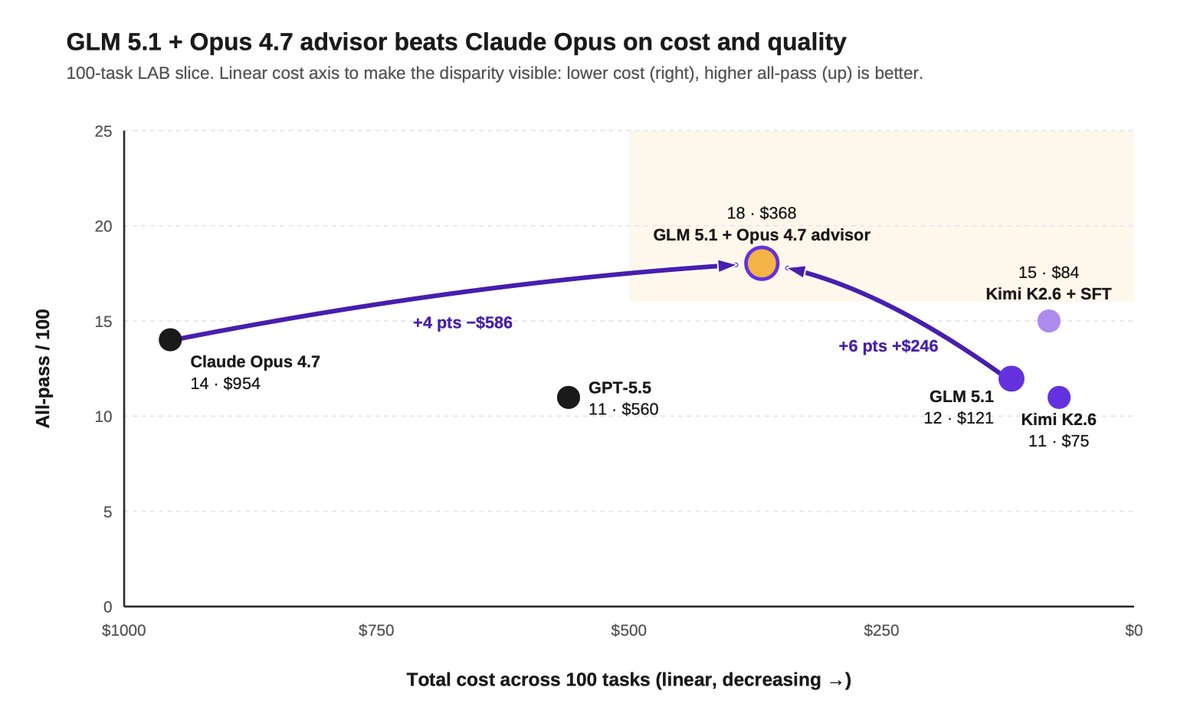
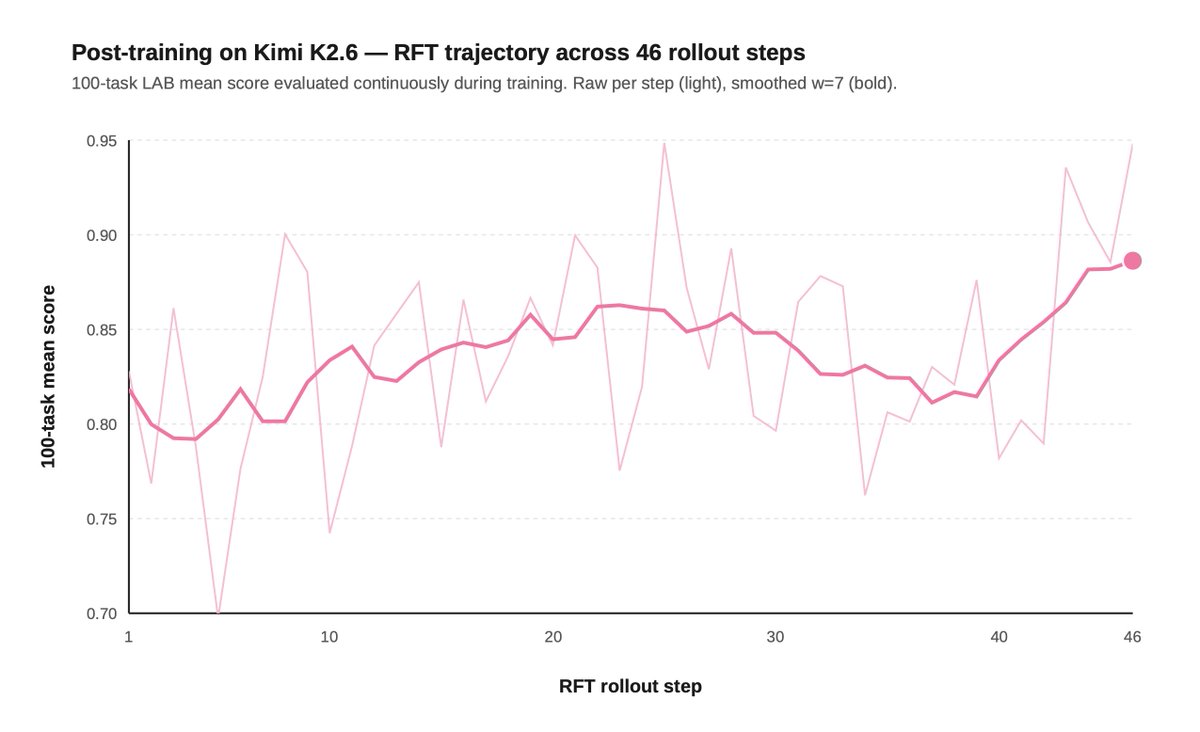
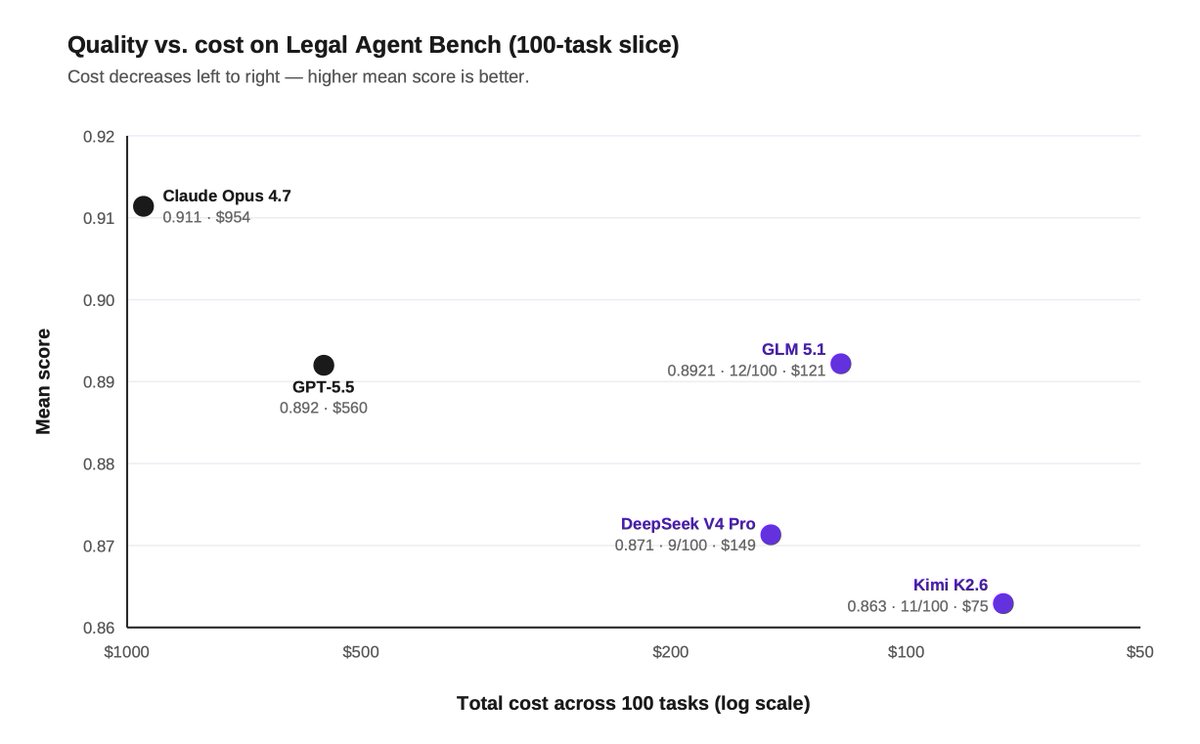
We partnered with @FireworksAI_HQ to train open-source models for legal. Here's what we found:
1) Hybrid legal agents can beat frontier models on quality and cost by routing selectively to a frontier advisor.
We tested a hybrid setup where GLM 5.1 served as the primary worker, routing tasks to Opus 4.7 as an advisor when needed.
GLM invoked Opus sparingly, just 0.83 times per task on average.
The hybrid setup beat Opus on both quality and cost: 18% all-pass vs 14%, at $368 vs $954 across the same 100 tasks.
2) Post-training can push open models to frontier-level legal performance.
On a 100-task slice of our Legal Agent Benchmark (LAB), SFT moved Kimi 2.6's all-pass rate from 11% to 15%, beating Opus' 14%.
But the cost gap was even more striking: $84 vs $954 across the same 100 tasks, or ~11x cheaper.
We're excited to continue working with @FireworksAI_HQ on the next generation of open-source legal agents.
40
69
868
441,386
Read more on our open-source legal agent experiments with @FireworksAI_HQ: x.com/FireworksAI_HQ/status/…
Jun 3

Frontier models are powerful advisors.
On @harvey's Legal Agent Benchmark, a GLM 5.1 worker using Claude Opus 4.7 as a sparse advisor reached 18/100 all-pass versus 14/100 for Opus alone, at 39% of the cost.
More on the harness design, advisor pattern, and training results: fireworks.ai/blog/open-sourc…

1
25
14,984