
Physician & Co-founder/CEO @SeamlessMD Digital Care Journeys for health systems ⚡️ Previous: Chair, Innovation Council, CMA | @uoftmedicine | @NEXT_Canada
Joined June 2010
- Tweets 9,986
- Following 564
- Followers 3,265
- Likes 6,420
2,212 Photos and videos











Pinned Tweet

25 Sep 2023
10 things I believe about Digital Health after 10 years working in Digital Health
A visual thread 👇

6
12
69
29,088
I was deflated. 80% of the sales team we hired had left. Here I was telling the last one standing that I wasn’t going to be hiring again anytime soon - it would just be him and I for a while. Until we fixed what was broken, it just didn’t make sense to re-hire. And because I know this wasn’t the situation he signed up for, I would understand if he wanted to pack up and leave.
It was 2017 and we were fresh off of a financing round. We finally had our first case studies showing @SeamlessMD could reduce length of stay and readmissions We thought we were ready to grow.
So we grew our team faster than we should have. It turns out clinical evidence might get you some meetings, but evidence itself doesn’t create urgency for health systems to adopt new Tech. I found this out the hard way.
Our much larger sales team pounded the phone, emails and conference circuit. We got way more meetings and interest than ever before. But most of it didn’t convert to adoption.
Over the course of a year, one by one, folks left. I couldn’t blame them - they were being incredibly rational. If customers aren’t buying, sales reps aren’t bringing home commission, and it makes sense for them to search for a better opportunity. It’s also a humbling experience for many startups - you can raise all the investor money you want, you can invest in sales all you want, but you can only help health systems to buy - you can’t force them to!
And so I ended up in that meeting room, sitting across from the last remaining member of our sales team. I fully expected him to leave, or at least, spend some time considering his options. But he surprised me.
“Josh, I don’t need to think about it. I’m committed to this company’s mission. I’m not going anywhere.”
And that was the first (and only time that I can remember) crying in front of someone at my company. I didn’t expect his response and I was overcome with emotion.
The climb uphill was very slow and hard. It felt like purgatory for a while. It wasn’t until a few years later during the pandemic that SeamlessMD began to be truly relevant and take off. Our patience and resilience paid off.
People ask me why I care so much about mission-alignment when we hire. This is why. You have to be a little bonkers and irrationally care about Healthcare so much to commit to improving a slow complex and messy system when any other rational person would tell you to pursue something else.
I’m so lucky to have the team that we do at @SeamlessMD. I have no idea what I would be doing without them.
2
4
552
P.S. We are hiring at @SeamlessMD - check out our job openings: seamlessmd.applytojobs.ca/
59
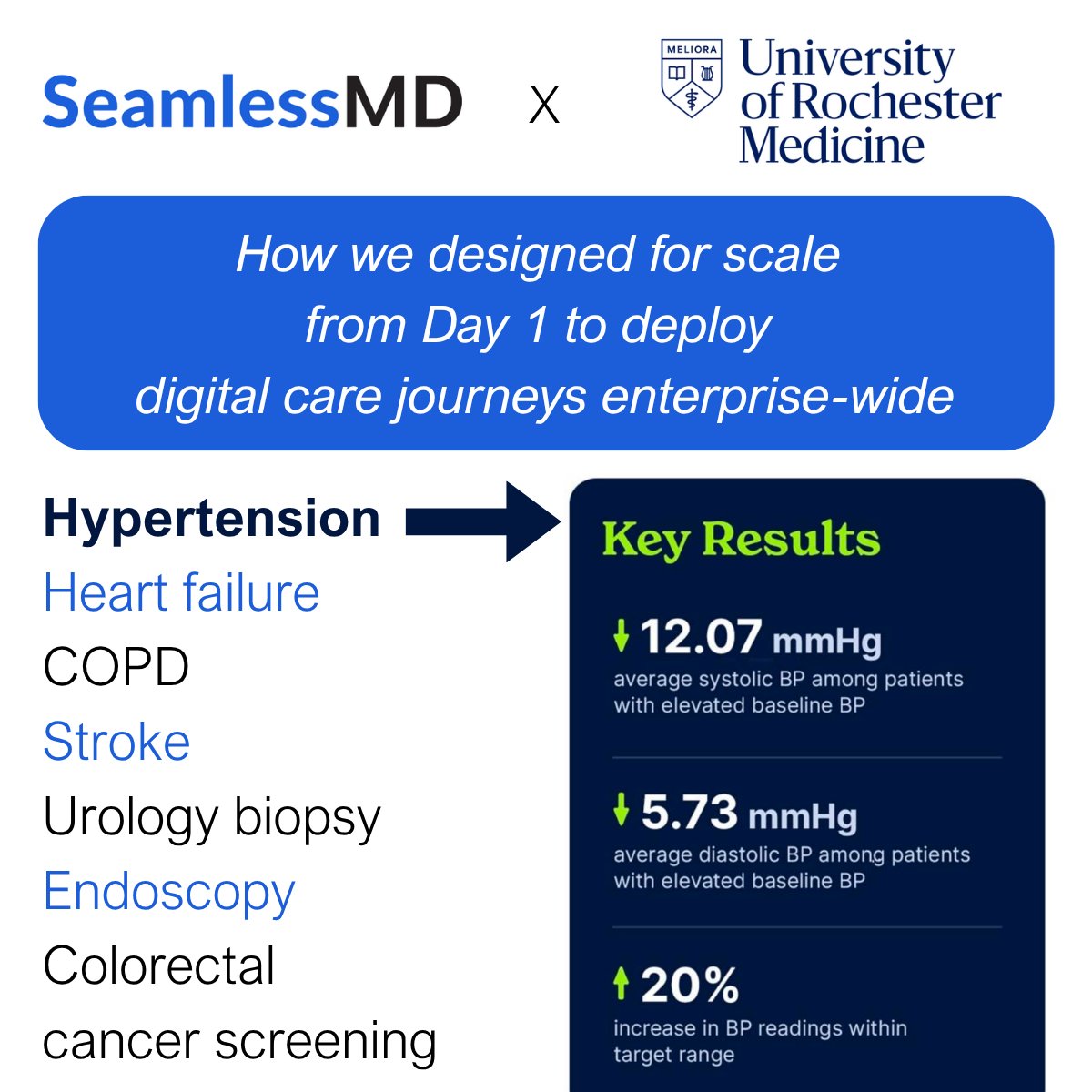
Most health systems would do a pilot, NOT put in the infrastructure to succeed… and wonder why things didn’t work. The @UR_Med did something different with @SeamlessMD:
They decided to go all-in on digital care journeys across numerous clinical programs - hypertension, heart failure, COPD, stroke, urology biopsy, endoscopy, and colorectal cancer screening - system wide and integrated with Epic and MyChart, investing in the necessary enterprise infrastructure to maximize success.
There was no safety net of a contained pilot. There was no “oh we’ll ask for IT resources to integrate in the ideal way if the pilot looks promising”. A real institutional bet.
Why does that matter? When you design a Digital Health strategy for scale from Day 1, you’ve created a forcing function to build the infrastructure that actually works.
Here's what that looked like in practice at URochester Medicine to automate reminders, education and symptom monitoring across so many care pathways so quickly:
→ Patient enrollment had to be automated as much as possible. The option of automated batch enrollment from Epic registries and SMART on FHIR embedded enrollment processes eliminated enrollment bottlenecks.
→ Clinicians needed key patient-reported data, such as blood pressure readings, written directly into Epic flowsheets, so monitoring became part of the existing clinical workflow instead of a frustrating activity.
→ Alerts for patients showing signs of risk had to be surfaced in existing workflows - Epic in-basket notifications now show up if a symptom/vital sign crosses a threshold, enabling timely intervention.
→ Reporting couldn't require a data analyst - out-of-the-box dashboards embedded directly in Epic replaced unreliable manual workarounds.
→ The patient experience had to work for the actual patient population - their previous solution was English-only. URochester Medicine can now support multiple languages, such as both English and Spanish for the hypertension journey.
Already that design for scale is delivering results for patients in the hypertension care journey:
⬇️ 12.07 mmHg drop in avg. systolic BP among patients with elevated baseline BP
⬇️ 5.73 mmHg drop in avg. diastolic BP among patients with elevated baseline BP
⬆️ 20% more BP readings in target range
I get why we do lots of pilots in healthcare. It’s a high-stakes industry, so the pilot mindset feels safe.
But when there are Health Tech partners like @SeamlessMD, backed by 14 years and 40 studies/evaluations of success, combined with a health system like URochester Medicine with the talented and motivated team willing to design for scale - real magic can happen when you build the right infrastructure for system impact on Day 1.
Congrats to URochester Medicine on these amazing results! Excited for our team to support this success.
P.S. Case study in the comments below if you want to learn more!
1
1
3
509
Jun 15
What’s the right benchmark to evaluate ChatGPT vs OpenEvidence? My answer will surely upset academic clinicians: NONE. Just Let The Market Decide. Before you yell at me, hear me out:
But first, a story…
I came from the clinical quality world. I did research on why healthcare organizations adopted (or didn’t adopt) certain innovations to prevent readmissions.
I then went into Health Tech, co-founding @SeamlessMD 14 years ago to help health systems digitally engage and monitor patients pre/post-care journeys (e.g. surgery) to improve outcomes such as readmissions. So I’ve learned a thing or two about what Tech clinicians and health systems actually adopt and why.
So let me say this: I WISH clinical evidence and rigorous evaluations were what drove adoption. If that were the case, then EVERY health system would use SeamlessMD and they would never use a competing product - because we have by far the strongest and most clinical evidence.
But that’s simply not reality. Clinicians and health systems don’t respond well to mandates - they, just like consumers, want to be empowered to have choice. Yet that’s also the beauty of the free market - you can change your mind.
So I pose this question:
Are continuous evaluations of ChatGPT/Gemini/Claude vs OE / UpToDate / Doximity even necessary? Especially since they'll be regularly out of date and no one can agree on criteria anyways?
E.g. You might think HealthBench is an appropriate benchmarking tool, but I’d rather use my own judgment than a tool developed by OpenAI - who themselves aren’t even truly focused on clinical care.
E.g. You might trust a research team choosing 12 doctors to assess the quality of clinical responses from AI, but I suspect most doctors trust themselves more.
Look, we already trust doctors to use their own individual judgment to appraise published evidence, guidelines, etc. before applying them. Why can't we trust them to individually appraise the CDS AI tools they use as well?
It's not like most of these tools are paywalled. Any doctor can access the vast majority of them very easily. Why should they care what 12 hidden doctors think about 100 hidden questions, when they can just test all the tools and pick what works best for them?
To be clear: I'm not saying benchmarks have no value. Checking for accuracy and safety? Absolutely that matters. But these published benchmark studies have limited utility when models are improving on a daily basis. By the time a study is peer reviewed and published, the results are already outdated.
And beyond that, practically speaking, these research studies and benchmark tools just realistically won’t drive adoption anyways - so while I have no problem with assessments being done, I’m just not confident most of this work will change actual practice.
But if someone can make Healthcare Benchmarks change actual Health Tech adoption, please create one for digital care journeys - we at @SeamlessMD would love to be first in line 😄
2
2
14
1,269
Jun 14
This “ChatGPT is better than OpenEvidence” Nature publication debate has surfaced a lot of spicy perspectives. Here are 5 thoughts I'm pondering this morning…
1/ Technologists are shouting from the rooftops: "see, I told you the foundation models were going to get so good, they would outperform vertical medical AI applications!"
Most of these folks probably just read the headline, saw the screenshot of the graph, and didn't even read the abstract - let alone the article. Because if you looked into it in any detail, you'd realize the sample size for real-world data was very small and there were important limitations. Heck, I even saw physicians doing this!
But who reads beyond the headline anymore? It’s a real problem that attention spans are so small.
2/ The rather spicy publication title: "General-purpose large language models outperform specialized clinical AI tools on medical benchmarks"
It's atypical for academic papers to have titles this declarative - usually titles are more conservative and focus on what was done. A more typical title: "Comparative evaluation of general-purpose large language models and specialized clinical AI tools on medical benchmarks".
I want to give the researchers the benefit of the doubt, but it would be strange for them to not have expected this level of debate from that title.
3/ Then there's OpenEvidence's spicy counter-argument with some interesting details:
→ The study authors had requested (and were denied by OE) API access to build a competing product
→ Screenshots showing frontier LLMs (e.g. ChatGPT) were almost certainly trained on the publicly available MedQA and HealthBench questions - meaning high scores may have simply been regurgitation from a known dataset.
→ Public peer review records show the real-world clinician queries were only added after peer reviewers flagged the study for weak evidence (strange if true)
OE is probably framing these points in the most advantageous way, but if the underlying facts have merit, that looks bad for the study authors.
4/ OpenEvidence is certainly not run like a traditional Health Tech company.
OE had a fast, personal, antagonistic response on social media - including airing dirty laundry about the study authors. Very typical of modern Silicon Valley “going direct to the world and speaking your mind”.
Contrast that with UpToDate (Wolters Kluwer) which hasn't said anything publicly, and likely won't.
Responding is great - but I probably would've avoided coming off spiteful. I don't see upside to that, with some downside in potentially putting off your customer base.
5/ Transparency is generally better. More context is almost always better than less.
I didn't like how the 100 real-world clinician queries - or at least a much larger example set - were not provided. That seems critical for a reader to have confidence in the methodology. I would come away with a different perspective on this paper if that were the case.
What other takeaways from this hot mess do you have?
1
1
13
2,427
Jun 14
This week we had Andrew Miner, CHIO at Inova, on The Digital Patient podcast! My 9 biggest takeaways from Andrew on Healthcare, AI and Informatics:
1/ The EHR will soon know the patient better than the clinician does. There will be a shift where the EHR's longitudinal data becomes the more reliable source on a patient's story.
2/ AI consent is governance's next unsolved problem. Individual consent for every AI use case is headed toward impracticality - but healthcare hasn't normalized implied AI consent yet.
3/ The physician identity crisis is real and worth naming openly. As AI absorbs more intellectual work, clinicians must continue to own the human piece - and be grateful something else handles remembering 5,000 drugs.
4/ Intentional friction matters as much as removing it. E.g. when 90-95% of medication alerts get overridden, the critical ones get ignored too.
5/ Tying bonuses to participating in EHR training drove a 50x increase in training completions at Inova. Physician attention is scarce - you have to get creative to earn it.
6/ Although clinicians are trained to be intolerant of failure, effective leadership requires the opposite, and it's one of the hardest shifts physicians face transitioning into leadership roles.
7/ Clinicians overestimate how much time AI scribes save them - which is a sign of cognitive unburdening, not just efficiency gains.
8/ "Doing more with less" must never feel like "doing more with less support". The goal is letting clinicians move as fast as they want - not faster than they want.
9/ Shadow AI governance follows a playbook health systems already know. Unsanctioned AI tools mirror past battles over secure messaging - systems that remember that playbook have a head start.
… and much, much more!
1
1
277
Jun 13
Is OpenEvidence already obsolete? A study in Nature found that ChatGPT, Claude, and Gemini all outperformed OE and UpToDate AI on medical benchmarks and real-world physician use. My 6 thoughts…
This week researchers from NYU Langone published a head-to-head evaluation of OE and UpToDate AI against GPT, Gemini and Claude. Here's what we know:
→ Frontier LLMs outperformed clinical AI tools across ALL THREE evaluations - medical knowledge (MedQA), expert clinician alignment (HealthBench) and real-world physician queries (RCQ)
→ The RCQ benchmark is the most clinically meaningful part: 100 actual queries submitted by physicians during routine care, scored by 12 blinded clinicians across clinical correctness, completeness, safety, and clarity. Yes, OE/UTD score worse than the frontier LLMs on these too!
→ Physician reviewers could annotate errors (e.g. factual, hallucinations) on any low-scoring response. Gemini had 8, GPT had 21, Claude had 19.
→ OpenEvidence had the most errors at 52 - mostly incomplete clinical content, safety-critical omissions, and disorganization.
→ UpToDate Expert AI refused to answer 19% of real queries entirely - by far the highest refusal rate
Alright, my 6 thoughts:
1/ Only 3 of the 12 physicians scored each of the 100 real world question/model answers - so it's not a substantial sample size, but it does make one think. I'm not surprised - I often run clinical questions against OE, Doximity, and Gemini - and I often find Gemini just as good if not sometimes better.
2/ I wasn't surprised that OE and UTD were considered inferior in some ways. I too find OE often produces info in a disorganized way, which is why I've found Doximity more user friendly in general (so I'm disappointed they weren't included).
3/ I share the same challenges with UTD - because it only uses curated clinician content as a knowledgebase, it's more likely to have incomplete responses or refuse to answer. While I respect that this is for safety reasons, I find it frustrating to not get an answer 100% of the time. Also, curated-only knowledgebases are consistently out of date.
4/ We need a larger variety of physicians and sample size of real-world queries to truly compare. Were these all primary care questions? How would the head-to-head go for specialty-based questions?
5/ The study did NOT assess citation quality or retrieval of latest evidence/publications - frontier LLMs would likely fare much worse here due to a propensity to hallucinate references and lack of access to NEJM, JAMA, etc. unlike OE. Consumers won't get this, but clinicians do care.
6/ I predict these findings will NOT affect physician or health system adoption of OE, UTD, etc. For safety/liability reasons and access to latest evidence, purpose-built CDS AI tools will remain the most used. Who is more likely to lose in a lawsuit - a doctor who used OE which licenses from NEJM and provides a BAA, or a doctor who used Gemini but cites this Nature study as justification?
4
4
18
3,093
Jun 13
People are asking what I think about Abridge’s big announcement this week on its “AI-native clinician intelligence platform”. My 5 thoughts…
1/ Their go-to-market strategy / marketing is arguably the most impressive thing about them.
I remember seeing ads for the Abridge Keynote. My first reaction: “why would anyone sign up to watch a webinar?”
Yes, there was a live stream - but there was also a huge in-person event in New York, with health system leaders, reporters, etc. I’m actually shocked (impressed) that a bunch of CMIOs/CIOs showed up for a one-day event like this.
Abridge has achieved the closest thing to creating a customer halo effect among health systems since Epic (i.e. you look good/smart for being a customer).
2/ The real product is the cohesive narrative communicated: AI for pre-visit, during the visit and post-visit.
Abridge did a really good job framing the vision that many ambient AI vendors have been trying to communicate for Intelligence across the entire experience of delivering care.
AI for pre-visit summaries. AI CDS suggestions mid-encounter. AI-suggested billing codes and orders post-visit. Powered by voice, just like we see in Star Trek.
Now Abridge wasn’t the first to pitch this, but they certainly have been the first to publicly tie it together in a cohesive way.
3/ The timing is almost certainly intentional - two months before Epic UGM. Get ahead of any big announcements from Epic.
Epic made a splash with their ambient announcement last year. We know Epic’s 100 AI features include many (if not all) of the components we’re talking about.
There’s no question Epic is going to paint a very compelling vision for Intelligence at UGM this year - with tons of overlap. The question on the minds of the health system leaders in attendance: will there be enough pieces already available (and bundled into the existing, already paid-for AI suite) that it’s not worth trying all these elements from Abridge (which likely will cost more $$$)?
4/ NVIDIA gets the eyeballs, but is probably the least important part of the announcement
Abridge announced they were partnering with NVIDIA to build a first-of-its-kind foundation model purpose-built for clinical conversations - but practically speaking, there’s nothing there just yet and no telling how much better a product this leads to (if at all). But it sure looks damn impressive to say NVIDIA is directly backing you.
5/ The Eli Lilly investment was the most out of the blue - but there’s a good reason for it.
Abridge didn’t need the money (they’ve raised a mind boggling $830M lifetime), so it wasn’t about the money - it was likely a way to align incentives and deeply integrate into the life sciences and clinical trials business.
Having raised money at a $5.3B valuation, they need to get to $1B /year in revenue to justify it - and it doesn’t seem likely any company can get there on pure health system revenue alone, especially now with competitive pressures from EHRs.
But you know who has $$$ to spend? Pharma and life sciences…
3
1
12
1,034
Joshua Liu retweeted

Jun 11
On this Ep of #TheDigitalPatient, @joshuapliu & Alan chat w Andrew Miner, MD (CHIO @InovaHealth) abt "50x'ing IT Adoption w Physician Bonuses, How Ambient's Biggest Win Isn't Time Savings, and Why Your EHR Will Soon Know Your Patients Better Than You" 👇seamless.md/blog/229-inova-h…
1
1
116
Jun 9
I still remember the sting when my Health Tech startup got rejected by Sam Altman and Y Combinator - yet there’s a good chance @SeamlessMD wouldn’t be alive today if we got in.
In fall 2014, we interviewed at Y Combinator. Our startup was about two years into existence and candidly didn’t have too much to show for it. Our first hospital pilot study had pretty bad results. And we had just started a couple of others. For those of you starting in Health Tech innovation today and think things move too slowly… you have no idea how much slower things moved back then!
So part of the reason interviewing at YC was so exciting is because it felt like it would give us self-validation. If Sam Altman and YC thought we were onto something, then maybe we were - because given our slow progress, it was hard to believe we were getting somewhere.
The YC interview is very short - about 10 minutes long. It flew by fast. They asked to see the product - the demo lasted 20 seconds, we barely showed anything. Lots of random questions about product, market - and why the heck would hospitals ever buy this?
Now the whole time, Sam Altman was typing on his phone. He didn’t speak to us at all. I guess that was an omen for what was to come. Suffice to say, it wasn’t encouraging. Were we really that boring?
(Turns out Sam had more urgent things to do. The Reddit CEO had just stepped down, he had been interim CEO for eight days, and announced a new CEO that evening! So we felt a bit better.)
That evening we got the “bad news” by email:
“We’re sorry to say we decided not to fund you guys. While we like the idea of helping patients prepare and recover from surgery better, it’s a very difficult business for a startup, because it’s hard to compete with incumbents who already have the doctor, hospital and patient relationships. We predict that existing EHR systems will gradually add richer patient advice, and it will get harder and harder to compete with them over time. We’d encourage you guys to look at related ideas, giving careful thought to the challenges of selling to doctors and hospitals. We’d be happy to hear from you again if you figure out a business model that can grow quickly.”
Oof.
Now YC wasn’t wrong. It turned out selling to hospitals and health systems was slow and hard 😆
They were semi-wrong about EHRs competing. Most EHRs haven’t, and of the only one that does (Epic), most of our health system partners use our core product integrated with Epic/MyChart - and the others use our content in Epic’s product (with us as Epic’s only vendor partner for this content).
And most of our competitors who raise a bunch of investor money to try and grow faster than the health system market was willing to adopt? Yeah… it hasn’t worked out so well.
If we had chosen our path based on what YC was more likely to fund - i.e. pivot to a product that would have faster adoption - almost certainly @SeamlessMD wouldn’t exist today. Because we’d have to pivot away from improving patient outcomes to revenue cycle management or something else more attractive to financial decision makers.
But because we focused more on the problems we were trying to solve in the patient journey, on improving patient outcomes, and were lucky to build a super smart, resilient team - now 12 years since that YC rejection we are at scale, sustainable, the market leader in our space - and still a lot more amazing milestones to come.
It turns out we were very lucky that YC thought the incumbents would stomp us out. Because if we believed them, thousands and thousands of patients would have missed out on the incredible impact we’ve made with health systems.
And I probably would’ve had to get a real job, and whoever my boss would’ve been would be super frustrated with me.
1
12
1,097
Jun 9
This week we had Ryan Sadeghian, former enterprise CMIO at U of Toledo Medical Center, on The Digital Patient podcast! My 7 biggest takeaways from Ryan on Healthcare, AI and Informatics:
1/ "Does the AI operate so smoothly nobody notices it?" is Ryan's North Star for every new AI solution. If a tool requires new logins or copy-paste workflows, it has already failed.
2/ Most AI failures aren't model failures - they're governance failures. The AI models are often good enough, but what breaks down is ownership, workflow redesign, and accountability. The real question isn't "is the AI ready?" but "is our system ready?"
3/ The ROI trap of patient-facing AI is genuinely unsolved. Ryan built a pediatric chatbot that gave brilliant, safe answers and cost hundreds in tokens per pilot. But if patients stop coming to clinic because the chatbot answered their question, how do health systems make the revenue model work?
4/ "Don't outsource your thinking" is Ryan's critique of paying big consulting firms millions of $$$ to lead AI transformation. The consulting firm's real edge is knowing how to run LLMs on your own data better than you do - but the health system that learns that skill in-house wins.
5/ Early Microsoft Copilot disappointment has poisoned the AI well in the C-suite. Many CXOs tried Copilot, got bad outputs, and mentally wrote off AI entirely. That first impression is nearly impossible to reverse - and it's blocking genuinely transformative tools from getting a fair hearing.
6/ "Cool technology to enable warm hands" is Ryan's philosophy in five words. AI should automate administrative noise so physicians can think, listen, and decide. The moment it increases clicks or inserts itself between doctor and patient, it's working against medicine.
7/ AI governance is a system responsibility, not a CMIO-only problem. AI transformation owned by one executive produces a 200-page report nobody reads. Real change requires distributed ownership across every workflow it touches - from nursing to revenue cycle.
… and much, much more!
4
2
479
Jun 8
It turned out big academic medical centers could NOT actually be “kingmakers” for startups - but Epic actually could, as we saw with Abridge. What does that tell us about adoption of Health Tech Innovation?
I remember when we first started @SeamlessMD, we made the wrong assumption that brand name academic medical centers could give you a halo effect. That if you could show famous hospital X was a customer, everyone else would follow.
So when we finally got a couple of big brands as adopters, I thought everything would be easy - but I was wrong. No one actually cared. No one bought our product just because some famous brand did. And every year another 100 startups make this mistake (and also some famous hospitals keep perpetuating this myth… but oh well).
What’s interesting is that it turned out there was a way to create a halo effect for Health Tech… but it came from the EHR, NOT health systems themselves.
Folks might remember that Abridge and Nuance/DAX were the only two AI scribe partners in Epic’s Workshop - which meant Epic was co-developing new Technologies together. Which enabled earlier access to new APIs and integrations with Epic.
This allowed Abridge and Nuance to completely dominate the US health system market for AI scribes for a couple of years. I know this mattered because I have many instances of CMIOs/CIOs telling me they only seriously considered Abridge and Nuance for this very reason. Even though other AI scribes had also integrated with Epic, this Epic Workshop designation created a perception that Abridge/Nuance had access to better integrations already or in the future. So of course this gave the impression that Abridge/Nuance were better in some way - why else would only those two be in the Workshop category?
I even remember a CMIO telling me that they had picked a different AI scribe vendor after a structured, multistakeholder evaluation… only to be overruled by the health system Board because Abridge had that halo effect.
This is a perfect example of the old adage “great distribution beats great product”. This is not to say Abridge and Nuance didn’t have the best products (maybe they did), but that doesn’t matter as much as having the best distribution - which the Epic Workshop status certainly helped provide.
However the lesson of this story isn’t that you need to convince Epic to create a new Workshop category to kingmake you - that’s an outlier event.
The bigger lesson is that nearly every great Health Tech innovation also needs great distribution and go-to-market to succeed. And that in the health system IT space, the perception of “who plugs in best to our core platforms like the EHR” often has far more influence on adoption than features, evidence or social proof.
Too often Health Tech innovators focus too much on the product and not enough on distribution - if this is you, consider this your wake up call.
2
5
25
2,931
Jun 6
AI scribe companies are in for a rude awakening when their contracts are up in two years. That’s the Number 1 thing CMIOs are telling me now.
I’m hearing stories of how EHRs are providing entire AI product suites (including the AI scribe) for a fraction of what health systems pay an Ambient AI startup - just for the AI scribe alone.
Meanwhile Ambient AI startups are charging additional fees for the nursing ambient product, and then more fees for whatever product comes next. And of course they are - they need to demonstrate rapid customer expansion to justify their large valuations from investors.
The problem is even if the Ambient AI vendor has a better product, the market for them is becoming frozen. Every health system will say “at this price, we HAVE to try the EHR product first”. And we aren’t just talking about AI physician scribes - the EHRs have already rolled out their own AI inpatient nursing scribes too.
So if you’re an Ambient AI startup, what do you do? Here are the top three options that come to mind:
1/ You expand your market beyond health systems and recognize your total market among US health systems is capped. I think Heidi may end up being the most successful precisely because they focused on everything EXCEPT the US health system market.
2/ You expand your product well beyond voice into vision and integrated hardware. If you’re not only the software layer but also the connected hardware layer to enable visual ambient (eg you collect passive data by collecting and interpreting physical data in the hosptial/clinic) and beyond - you offer something a lot more compelling that an EHR is far less likely to compete directly head on for. You become the completely ambient package.
3/ You aggressively try to get acquired by Oracle, MEDITECH or some other large incumbent not named Epic (since they never acquire). The market for AI scribes is only going to shrink going forward and unless you are confident you can grow the pie and your piece of it, you may want to exit while the valuation is at its highest.
But what you can’t do is continue the same playbook and expect the good times to continue.
2
2
10
815