
PyData meetups in London for data-loving pythonistas. Powered by @emlynclay, @ianozsvald, @john_sandall
Joined April 2014
- Tweets 4,492
- Following 257
- Followers 5,431
- Likes 2,689
505 Photos and videos















Pinned Tweet

4 Feb 2025
We're back dear Pythonisatas 🐍 Bigger and better this year.
😎 For the regulars - Tickets are live ! Book now 👉 lnkd.in/eub647sh
🤔 For the curious first-timers, here's what we do👇
(1/4🧵)

1
3
7
1,049
PyData London retweeted

27 May 2025
Looking forward to the @pydatalondon conference in a couple of weeks, in a great new venue! If you get a chance do stop by the @DataKindUK stand to say hi and discover how we bring together skilled volunteers to help charities make the most of their data!
pydata.org/london2025
1
1
285
PyData London retweeted

31 Mar 2025
I will be talking about evaluating AI systems in my talk tomorrow for @pydatalondon , "Death by RMSE: A Cautionary Tale of Metrics Gone Wild"
"You’ve trained the model. The eval metrics look great. But somehow, it doesn't change anything — the KPIs are static, the business impact isn’t there, and you’re left wondering: DID WE OPTIMISE FOR THE WRONG THING?"
meetup.com/pydata-london-mee…
31 Mar 2025

Quite pleased to see the emphasis on evaluating and not just delivering AI pilots, and comparing that to what *actually happens now* - we should be working to understand exactly where and how AI works in government, not whether or not it's perfect.
4
2
4
542
4 Mar 2025
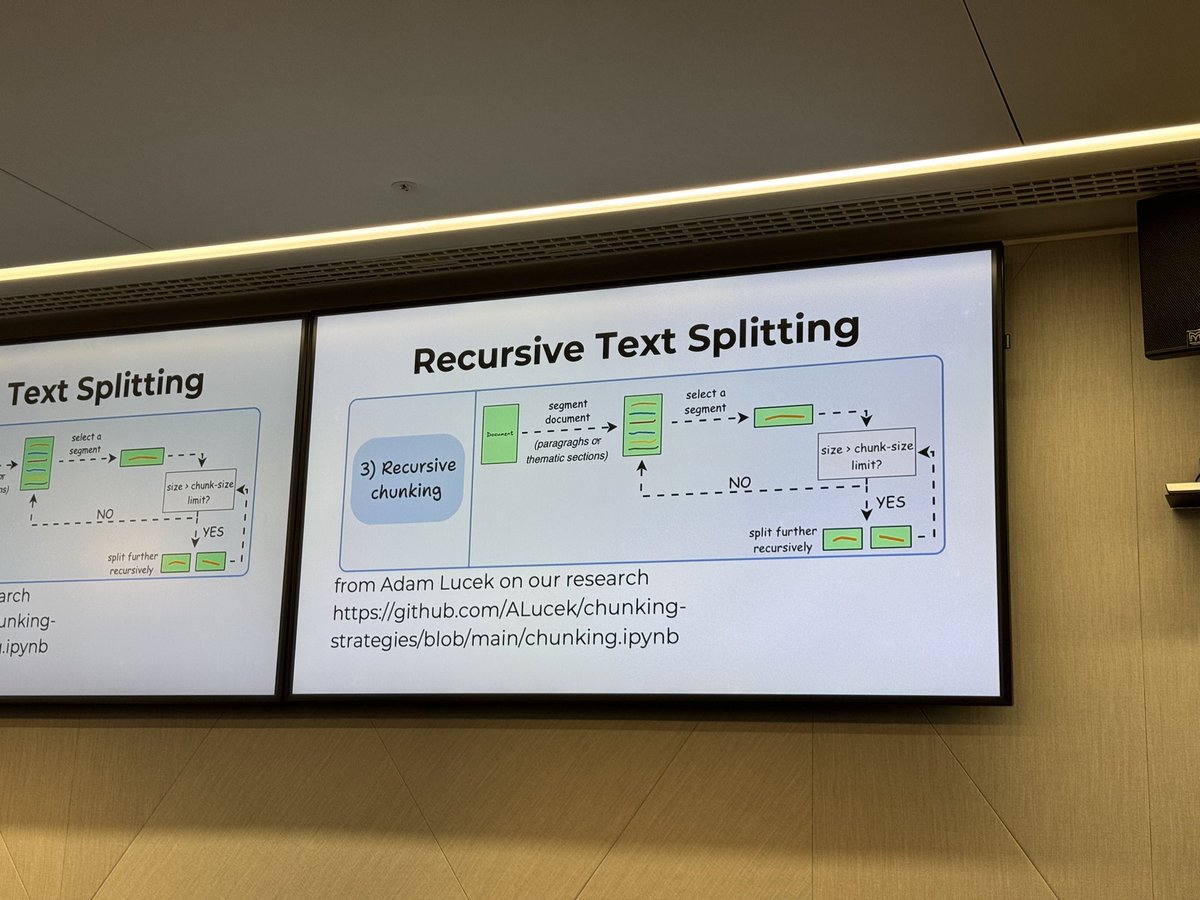
PyData London #94 kicks off with talks on
1️⃣ Advanced RAG chunking techniques from Brandon Abreu Smith (ex-Chroma SWE who literally wrote the paper on RAG chunking eval)
2️⃣ How to deploy self-hosted LLM apps in your workplace from @DmitriEvseev

1
4
513
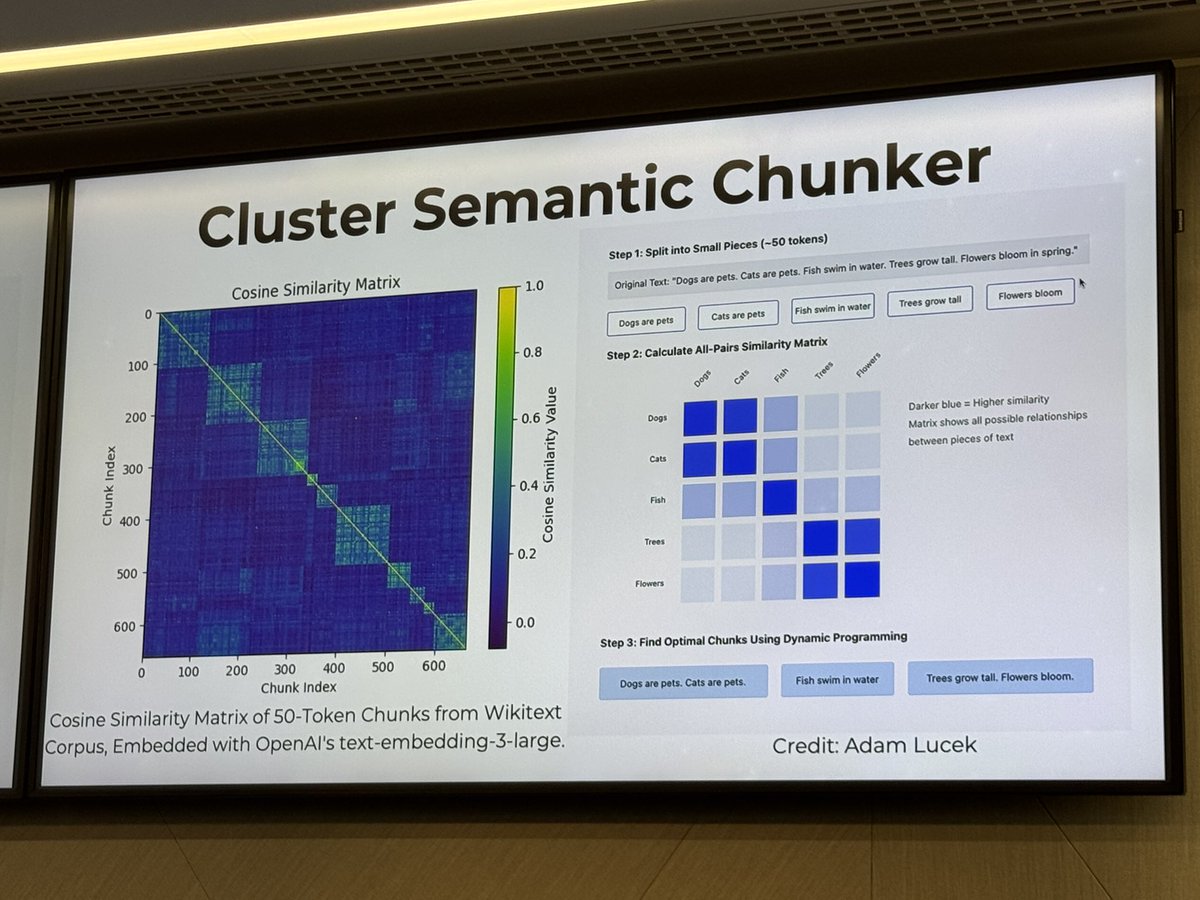
4 Mar 2025
RAG is not all you need! There’s a lot of options here to optimise your RAG’s information retrieval
Repo here: github.com/brandonstarxel/ch…


1
229
24 Feb 2025
🚨 FINAL CALL 🚨
Register as a speaker for PyData London 2025 👉pydata.org/london2025/cfp
@PyDataCambridge
@pydatacardiff
@PyDataSoton
@pydatanyc
@PydataLancaster
@PyDataGlobal
@PyDataMCR
1
207
23 Feb 2025
🚨 Last chance - few speaker slots left for PyData London 2025 🚨
Register now 👉 pydata.org/london2025/cfp
@PyDataCambridge
@pydatacardiff
@PyDataSoton
@pydatanyc
@PydataLancaster
@PyDataGlobal
@PyDataMCR
1
1
235
22 Feb 2025
🚨 Last chance - few speaker slots left for PyData London 2025 🚨
Register now 👉 pydata.org/london2025/cfp
@PyDataCambridge
@pydatacardiff
@PyDataSoton
@pydatanyc
@PydataLancaster
@PyDataGlobal
@PyDataMCR
1
2
241
21 Feb 2025
🚨 Last chance - few speaker slots left for PyData London 2025📷 Register now 📷pydata.org/london2025/cfp
@PyDataCambridge
@pydatacardiff
@PyDataSoton
@pydatanyc
@PydataLancaster
@PyDataGlobal
@PyDataMCR
140
20 Feb 2025
🚨 Last chance - few speaker slots left for PyData London 2025🚨
Register now 👉 pydata.org/london2025/cfp
@PyDataCambridge
@pydatacardiff
@PyDataSoton
@pydatanyc
@PydataLancaster
@PyDataGlobal
@PyDataMCR
133
18 Feb 2025
🚨 6 days left ! Register as a speaker for PyData London 2025 📷 pydata.org/london2025/cfp
@PyDataCambridge
@pydatacardiff
@PyDataSoton
@pydatanyc
@PydataLancaster
@PyDataGlobal
@PyDataMCR
2
142
17 Feb 2025
🚨 7 days left ! Register as a speaker for PyData London 2025 📷 pydata.org/london2025/cfp
@PyDataCambridge
@pydatacardiff
@PyDataSoton
@pydatanyc
@PydataLancaster
@PyDataGlobal
@PyDataMCR
151
16 Feb 2025
🚨 8 days left ! Register as a speaker for PyData London 2025 📷 pydata.org/london2025/cfp
@PyDataCambridge
@pydatacardiff
@PyDataSoton
@pydatanyc
@PydataLancaster
@PyDataGlobal
@PyDataMCR
2
2
221
14 Feb 2025
🚨 10 days left ! Register as a speaker for PyData London 2025 📷 pydata.org/london2025/cfp
@PyDataCambridge @pydatacardiff @PyDataSoton @pydatanyc @PydataLancaster @PyDataGlobal @PyDataMCR
1
2
208
13 Feb 2025
🚨 11 days left ! Register as a speaker for PyData London 2025 📷 pydata.org/london2025/cfp
150
12 Feb 2025
🚨 12 days left ! Register as a speaker for PyData London 2025 📷 pydata.org/london2025/cfp
2
1
221
11 Feb 2025
🚨 13 days left ! Register as a speaker for PyData London 2025 📷 pydata.org/london2025/cfp
1
1
159
10 Feb 2025
🚨 14 days left ! Register as a speaker for PyData London 2025 📷 pydata.org/london2025/cfp

1
1
146
9 Feb 2025
🚨 15 days left ! Register as a speaker for PyData London 2025 📷 pydata.org/london2025/cfp

1
2
170