
Joined April 2025
- Tweets 336
- Following 12
- Followers 10,746
- Likes 137
72 Photos and videos
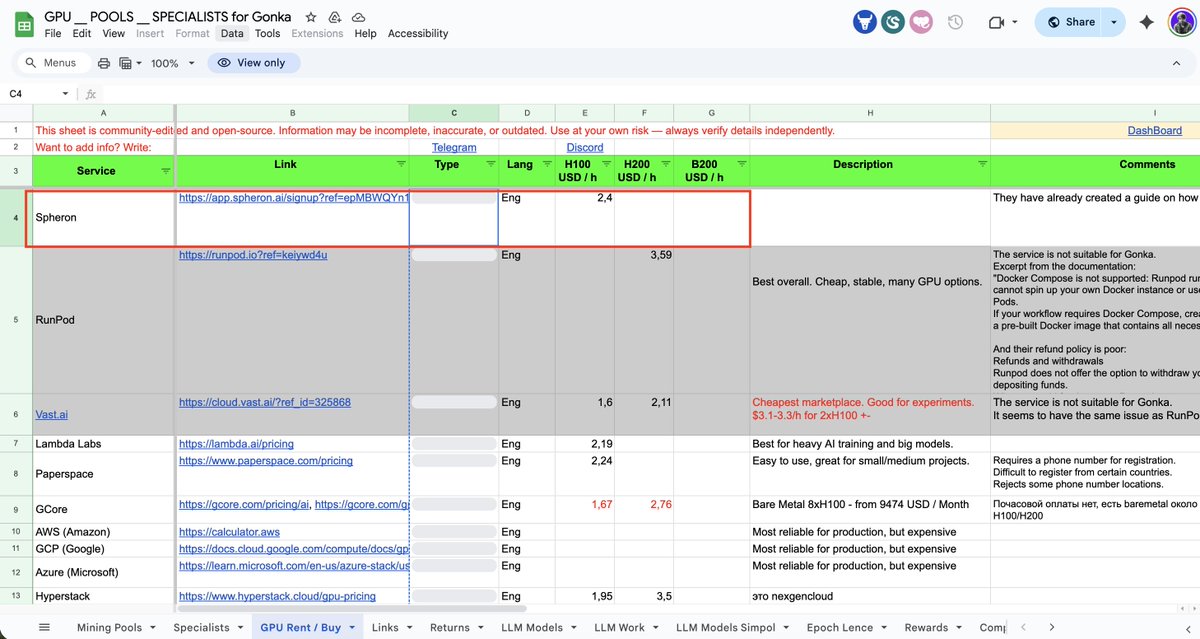














Pinned Tweet

7 Jul 2025
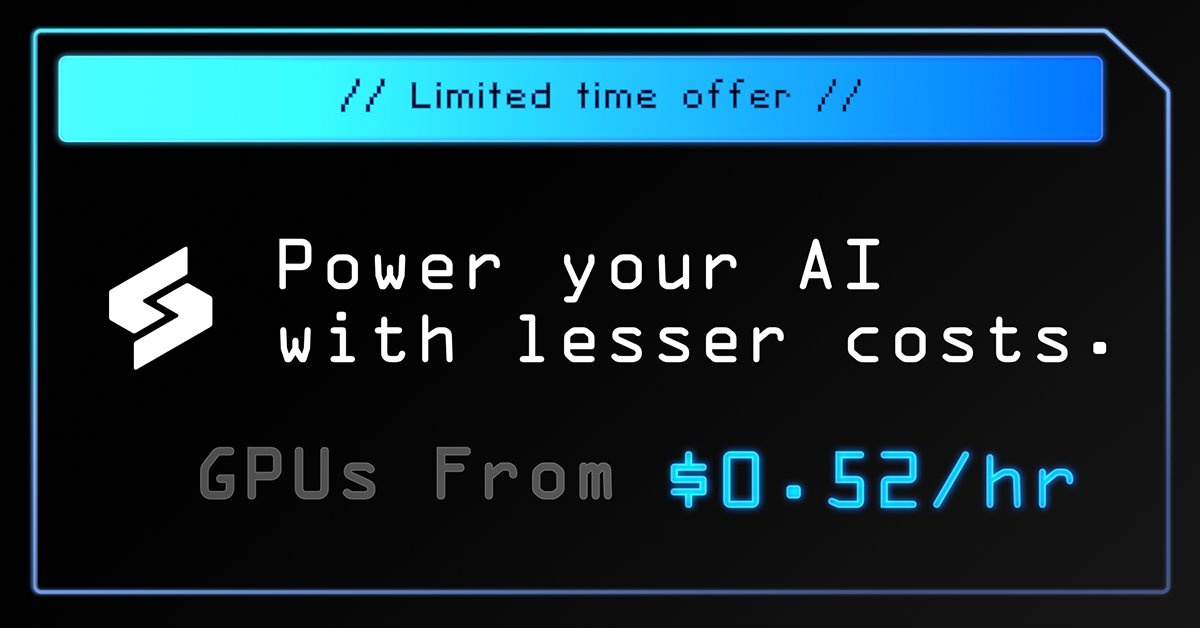
Launching Now: On-Demand Access to H100s,5090, H200s, B200s & more
No more waiting lists.
No long-term contracts.
No vendor lock-ins.
Just instant access to the GPUs you need—from SXM5 InfiniBand to PCIe—all in one place.
⚡ Spin up 100 H100s or reserve a few H200s for training
🧠 Choose across providers without switching tabs
💸 Pay only when you run workloads
Your infra team’s dream stack is live.
Fire up your first cluster now
app.spheron.ai
5
8
38
10,833
Feb 20
Enterprise compute. Startup terms.
Access H100 clusters instantly with pay-as-you-go pricing - no long-term commits, no minimums, 20-50% cheaper than hyperscalers.
Built for AI teams that move fast.
→ spheron.ai
1
3
427
Spheron AI retweeted

Jan 7
AWS just raised H200 pricing by ~15%.
Our prices stayed cheaper and affordable as always.
While hyperscalers keep pushing compute costs up, we’re doing the opposite: giving teams access to the same enterprise GPUs without the enterprise tax.
Teams switching to Spheron are already saving up to 80% on GPU spend.
The shift happens when people realize:
you don’t need hyperscalers to run serious AI.
Jan 6

Amazon $AMZN AWS has raised pricing for EC2 Capacity Blocks for ML by about 15%, with H200-based p5e.48xlarge moving from $34.61 to $39.80 per hour in most regions and p5en.48xlarge from $36.18 to $41.61, while US West (N. California) p5e went from $43.26 to $49.75 - The Register

3
10
1,362
Jan 5
Enterprise GPUs. Without enterprise pain.
So you can Build faster and Pay less.
Spheron is built for teams actually shipping AI. Spin up instances in minutes, pay up to 70% less than hyperscalers, and run on real enterprise GPUs with predictable pricing.
3
3
4
1,053
Jan 5
So we fixed it.
What you get with Spheron:
• Fast access to enterprise GPUs, on-demand or spot
• Transparent pricing that makes sense from day one
• Global availability across multiple providers
• Real humans when you need support
1
284
Jan 5
If your bottleneck isn’t the model, but the infrastructure behind it, Spheron is built for you.
Start building at👇
spheron.ai
240
Spheron AI retweeted
Jan 4
Most startups think fine-tuning is only for teams with million-dollar ML budgets. That idea did not come from reality. It came from how AI infras has been sold for years.
The truth is simpler. Fine-tuning does not need bloated setups, long contracts, or enterprise-only platforms. It needs clear pricing, easy access to GPUs, and the freedom to iterate fast.
What actually breaks startup AI budgets is not ambition. It is:
- Procurement calls.
- Locked contracts.
- Unclear pricing.
- Slow access to compute.
Smart teams are moving away from platforms built for big logos and moving toward infra provider built for speed. Places where they can spin up, experiment, fine-tune, deploy, and repeat without waiting weeks or guessing costs.
That is exactly how @spheron is designed.
On Spheron, fine-tuning is treated like what it really is: a normal step in building AI. You get real GPUs, transparent pricing, spot and on-demand options, and the ability to start small and scale only when your data proves it makes sense.
If your biggest bottleneck is not the model but the cloud around it, the problem is your infrastructure.
AI workflows should have worked this way from day one.
3
3
11
1,150
Jan 3
If your AI training keeps crashing, slowing down, or costing more every week, the problem usually isn’t your model. It’s the GPU.
Most teams don’t need the newest GPU on the planet. They need one that works reliably, and doesn’t blow up the budget. That’s why NVIDIA A100 matters
4
1
4
920
Jan 3
You can run A100 GPUs starting at $0.76/hour.
That means you can:
Train faster.
Test more experiments.
Ship without waiting on procurement calls.
1
194
Jan 3
If you’re tired of paying premium prices for GPUs you don’t fully use, A100 is still one of the smartest choices in AI
And if you want it without contracts, hidden fees, or vendor games, Spheron makes it simple.
blog.spheron.network/rent-10…
1
1
4
779
Jan 2
Nvidia might be selling shovels in the AI gold rush, but Spheron is selling an entire mining operation, ready to go.
Jan 2

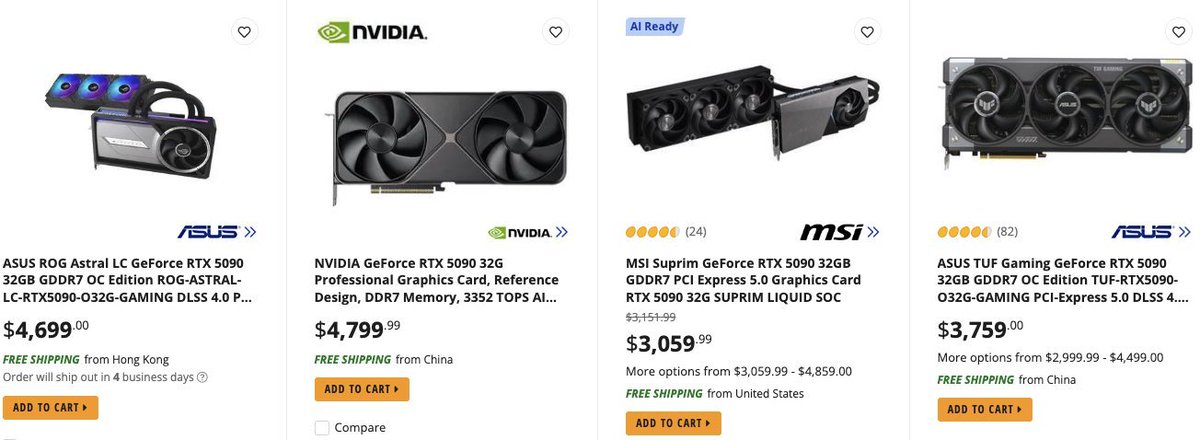
RTX 5090 prices are touching near to $5,000
GPUs are no longer “PC parts.”
They now cost more than most people’s first car.
200
31 Dec 2025
Most AI teams are not compute-bound anymore. They are memory-bound. That is why NVIDIA built the H200.
LLMs, long-context inference, RAG pipelines hit memory limits long before they hit FLOPS. H200 fixes that with 141GB HBM3e and much higher bandwidth.
1
1
2
173
31 Dec 2025
Most H200 capacity is locked behind enterprise sales calls, allocation delays, and unclear pricing.
On Spheron AI, teams can actually use H200:
• Spot, dedicated, or reserved options
• Transparent pricing upfront
• No hyperscaler lock-ins
blog.spheron.network/rent-nv…
1
1
725
Spheron AI retweeted
30 Dec 2025
Why spend $1,000s upfront on buying GPUs, when renting gives you the same compute for ~99% less cost?
In a fast AI cycle, renting beats buying for most teams.
3
1
6
787
Spheron AI retweeted
31 Dec 2025
Today marks the end of 2025. It was a year of extremes.
Compute shortages. Rising costs. Rapid shifts across AI, crypto, and global tech.
But one thing stayed constant, Teams that kept building, shipping, and solving real problems moved forward.
At @spheron, we spent 2025 doing exactly that. Helping builders access the compute they need, when they need it, without the usual friction.
We’re carrying that momentum into 2026.
More access. Better pricing. Fewer barriers between ideas and execution.
Wishing everyone a strong, focused, and meaningful year ahead. Here’s to 2026 🚀
3
4
7
1,010
30 Dec 2025
The NVIDIA B200 is not a hype GPU.
It exists because H100 and H200 are no longer enough.
If your models are hitting memory limits, bandwidth ceilings, or scaling walls, Blackwell is the next step. The problem is access. Most teams only see B200 in decks, not in production.
1
3
168
30 Dec 2025
@spheronai offers some of the best B200 pricing available without long sales cycles or hidden constraints.
Read the full article below 👇
blog.spheron.network/rent-nv…
1
3
4
662
Spheron AI retweeted
29 Dec 2025
The direction is clear. Most people will not own serious compute anymore.
AI demand is pushing hardware prices up across the board. RAM, GPUs, storage, even consumer devices keep getting more expensive. For many users, owning powerful local machines no longer makes sense. Compute is moving to shared infra that you access when you need it.
That shift does not have to mean control, lock-in, or surveillance by default. The real question is who owns and operates that compute. Centralized clouds concentrate power. Open, distributed compute networks spread it out.
From our side, the goal is simple. Make high-performance compute accessible without forcing people into a single gatekeeper. If compute is going to be streamed, it should at least be open, affordable, and choice driven.

2
12
871