
Joined April 2018
- Tweets 940
- Following 31
- Followers 5,915
- Likes 1,123
330 Photos and videos









Pinned Tweet

20 May 2025
1/ At Valence Labs, @RecursionPharma's AI research engine, we’re focused on advancing drug discovery outcomes through cutting-edge computational methods
Today, we're excited to share our vision for building virtual cells, guided by the predict-explain-discover framework 🧵

3
21
94
10,417
Valence Labs retweeted

Jun 11
In my experience, the biggest risk with interdisciplinary AI projects is solving the *wrong problem*. In my latest piece for Inside @valence_ai I explain how I think AI experts should take more ownership of problem formalization to maximize the chance of success [1/2]

1
2
14
606
Jun 11
New Inside Valence Op-ed out today!
In it, Valence Labs' @austinjtripp shares his views about an overlooked best practice in interdisciplinary collaboration.
2
1
6
822
May 26
🚀 Thrilled to see Valence researchers recognized with a Spotlight presentation at @icmlconf's GenBio workshop!
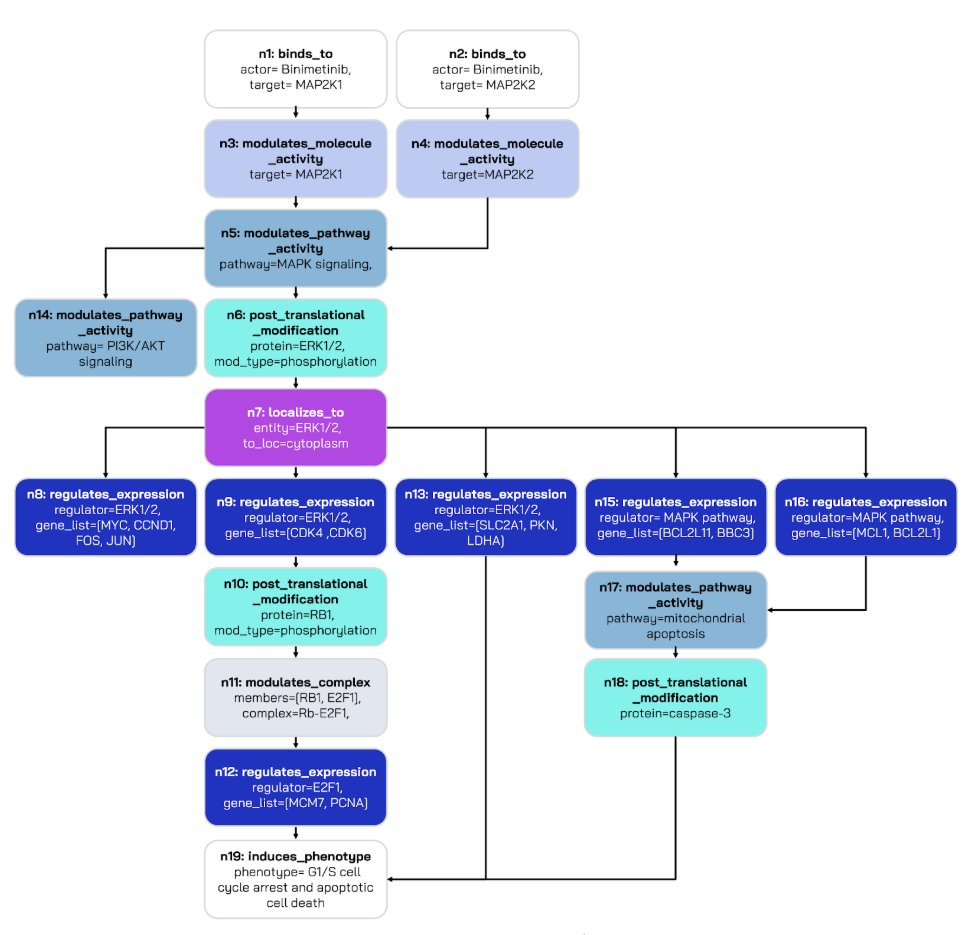
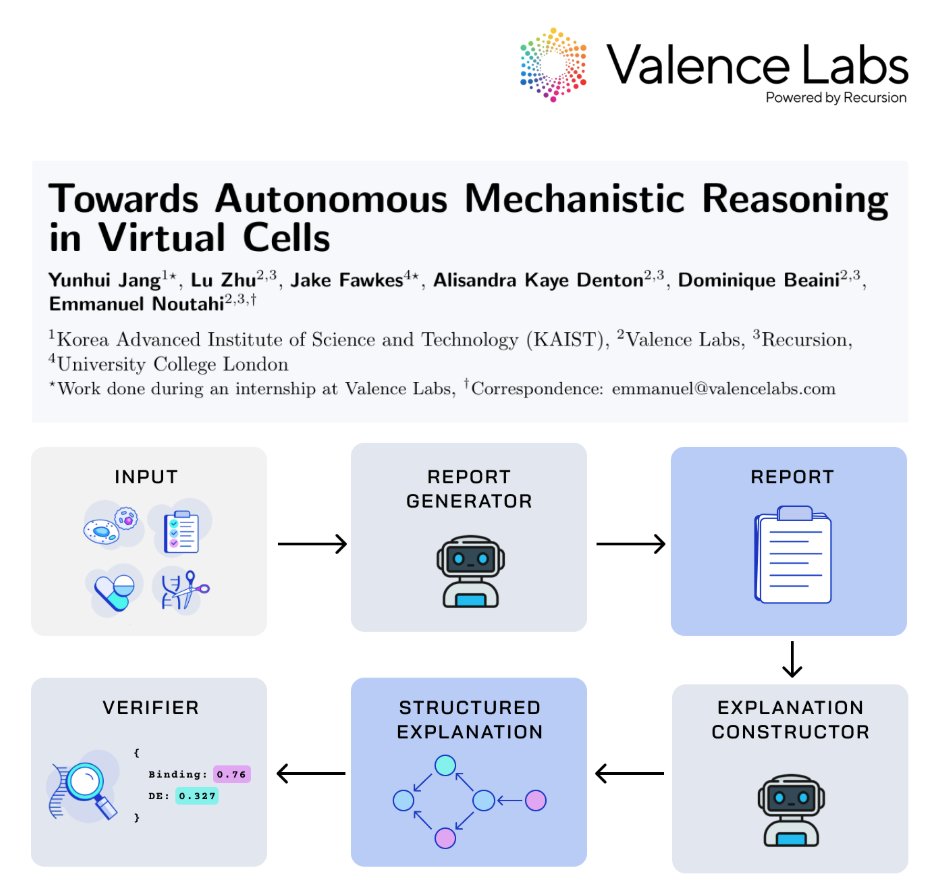
VCR-Agent is designed for explainability, to explain the relationship between perturbation and cellular response. It’s an area that’s underexplored in the research but critically important for practitioners.
If you want to build on this work, we’ve released VC-TRACES, an initial collection of mechanistic traces on the Tahoe dataset.
Links in the thread below 👇
Shoutout to our research team: @yunhuijang_, @LuZhu66 , @FawkesJake, @AlisandraDenton, @dom_beaini and @ENoutahi! 👏
We can’t wait to connect with the GenBio community and anyone else pushing the boundaries of drug discovery at @icmlconf in Seoul!
1
4
13
1,509
Valence Labs retweeted

May 14
🧬 Bridging the gap in AI drug discovery.
@AlisandraDenton, Staff Machine Learning Scientist at Recursion and one of the authors on our recent paper in @NatureBiotech, explains how the AI model TxPert predicts how a cell will respond to perturbations.
Predicting a cell’s RNA activity, or transcriptome, is key to bridging the gap between cellular changes and clinical outcomes and advancing the potential for AI drug discovery. As Ali says, “with hundreds of cell types and so much disease variation, the total possibilities are too vast to measure in a lab.”
She describes how TxPert allows us to perform a “Virtual Assay,” taking the mathematical signature of a healthy cell called the Basal State and adding the perturbation’s embedding to deliver a highly accurate prediction of what the cell’s transcriptome will look like after treatment.
TxPert uses layered graph-based models that integrate phenomics — or how a cell looks — and transcriptomics — which genes are expressed — along with massive public biological knowledge resources.
The model can even predict how a perturbation will work in entirely new cell lines it hasn’t seen before as well as accurately forecast the effects of “double perturbations,” consistently identifying "unknown unknowns" that traditional models — and even massive general-purpose AI — often miss.
Ali notes that TxPert is currently predicting genetic perturbations, but more flexible models — including those predicting drug effects — are in the works.
👉 Check out the full paper in Nature Biotech: nature.com/articles/s41587-0…
1
9
47
9,760
May 4
1/ Our most recent Inside Valence blog post delves into TxPert, a SOTA model published in @NatureBiotech.
The key finding: scale alone is insufficient, even smaller model architectures can achieve top performance when coupled with biological priors.
@IhabBendid35780
1
3
16
5,286
May 4
2/ In biology, data diversity is often a bigger challenge than data scale, with existing datasets capturing only a fraction of true biological complexity. The inability to navigate these sparsely populated datasets is why many high profile foundation models for transcriptomics underperform simple baselines.
Alongside an efficient Multilayer Perceptron (MLP), TxPert combines curated literature graphs (STRING, GO) with proprietary, high-throughput experimental screening data to maximize predictive power.
TxPert shows promising progress towards predicting perturbation outcomes in entirely unseen cell lines where no perturbations were observed during training. This capability will bring us closer to performing highly targeted, confirmatory wet-lab screens, converting the lab from an exploratory tool to a validation tool, and ultimately helping to accelerate the discovery of novel medicines.
1
1
346
May 4
3/
Link to Blog: open.substack.com/pub/valenc…
Link to Nature Biotech Paper: nature.com/articles/s41587-0…
1
323
Valence Labs retweeted

TxPert: using multiple knowledge graphs for prediction of transcriptomic perturbation effects go.nature.com/3QZW9WQ

1
19
67
6,240
May 1
Announcing TxPert, a SOTA model for perturbation prediction in transcriptomics, which we just published in Nature Biotechnology. TxPert shows promising progress towards predicting perturbation outcomes in entirely unseen cell lines where no perturbations were observed during training.
2
16
69
5,223
May 1
Congratulations to the team! Frederik Wenkel, Wilson Tu, Cassandra Masschelein, Hamed Shirzad, Liam Hodgson, Ihab Bendidi, Cian Eastwood, Shawn Whitfield, Craig T. Russell, Yassir El Mesbahi, Marta Fay,
@bertonearnshaw, @ENoutahi, and @AlisandraDenton.
1
3
575
Valence Labs retweeted
May 1
🧬 Closing the translation gap between cells and patients. 😷
@NatureBiotech just published a new paper from Recursion on TxPert – a deep learning framework that accurately simulates the transcriptomic shift in unseen biological contexts. TxPert represents an important step in our ongoing work to accurately model transcriptomics and bridge the gap between in vitro discovery and clinical reality – which is critical for improving and scaling AI drug discovery.
🔹 TxPert address this translational gap through:
▪️ Graph Neural Networks (GNNs): Rather than treating genes as isolated lines of code, TxPert uses an advanced Exphormer-MG architecture to map genetic perturbations across multiple, massive knowledge graphs, forcing the model to understand both the physical (phenomic) and molecular (transcriptomic) realities of a cell simultaneously.
▪️ Simulating the "latent shift": By mathematically applying a "perturbation embedding" to a cell's baseline state, TxPert can accurately predict the entire post-perturbation transcriptomic profile—without anyone ever having to touch a pipette.
▪️ Predicting unseen biology: TxPert successfully predicts the transcriptomic outcomes of completely unseen single perturbations, complex combinatorial therapies (Double Perturbations), and even how known drugs will act in entirely new, unseen cell lines.
TxPert is one of several models at Recursion to model transcriptomics and close the translation gap between cell responses and patients in the clinic.
🎉 Congrats to the team! Frederik Wenkel, Wilson Tu, Cassandra Masschelein, Hamed Shirzad, Liam Hodgson, Ihab Bendidi, Cian Eastwood, Shawn Whitfield, Craig T. Russell, Yassir El Mesbahi, Marta Fay, @bertonearnshaw, @ENoutahi, and @AlisandraDenton.
👉 Read the full publication in Nature Biotech here: nature.com/articles/s41587-0…
3
10
49
10,492
Valence Labs retweeted
Apr 30
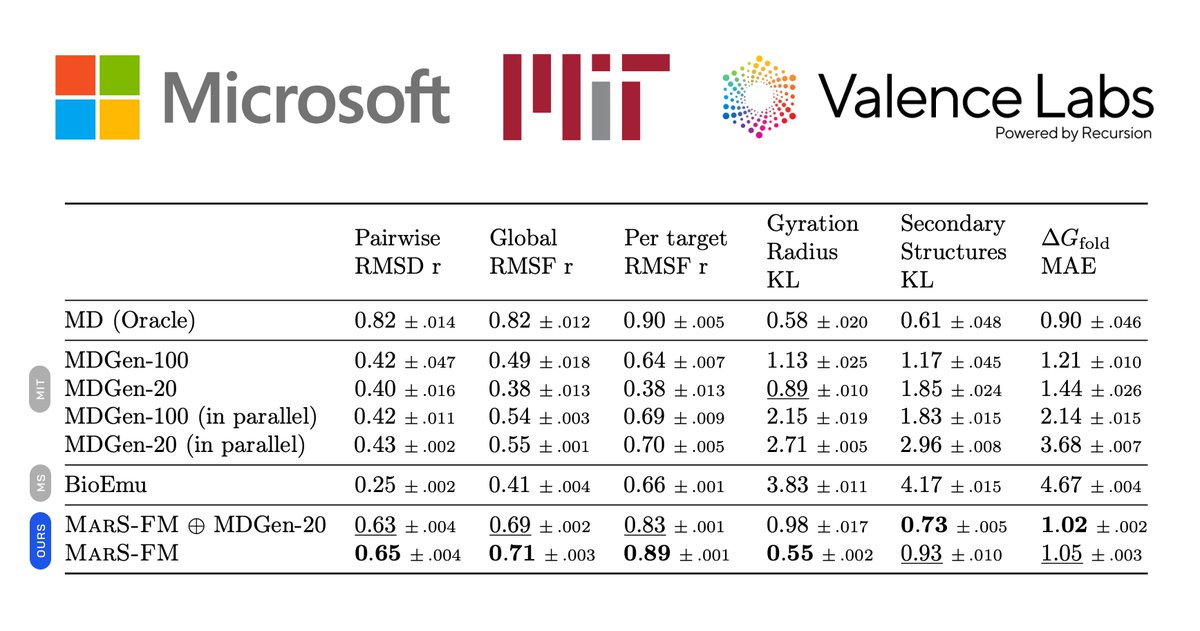
We had a fantastic time with @valence_ai at @iclr_conf in Rio sharing our latest machine learning breakthroughs, including presentations on TxFM, our state-of-the-art transcriptomics model that outperforms models up to 100x larger in terms of data size, and MarS-FM, our new class of generative models for molecular dynamics simulations.
And there were lots of great community conversations happening at the rooftop TechBio Social, co-hosted with ICLR’s Learning Meaningful Representations of Life (LMRL) Workshop.
Coming soon: we’re looking forward to sharing more of our ML breakthroughs at @icmlconf!
👉 TxFM paper here: openreview.net/pdf?id=NqZqCl…
👉 MarS-FM paper here: arxiv.org/html/2509.24779v3
2
5
27
6,066


