
Building the hardware for superintelligence
Joined April 2024
- Tweets 28
- Following 9
- Followers 19,926
- Likes 31
8 Photos and videos









Introducing Oasis: the first playable AI-generated game.
We partnered with @DecartAI to build a real-time, interactive world model that runs >10x faster on Sohu. We're open-sourcing the model architecture, weights, and research.
Here's how it works (and a demo you can play!):
1,408
1,077
12,264
24,646,005
We're excited to partner with @Cognition_Labs @Mercor_AI @CoreWeave and @AnthropicAI to host an inference-time compute hackathon, featuring >$60K in cash prizes and >1 exaflop of free compute.
9
20
230
77,546
We believe today's models significantly underutilize inference-time compute and search. With better algorithms and much faster hardware, we can push this scaling law by several orders of magnitude.
We're particularly interested in research that accelerates parallel reasoning, high batch speculative decoding, text diffusion, and adaptive scaling.
3
39
15,294

Thousands of people in the line 😅 adding compute to handle the load!
Go to oasis.decart.ai to try it yourself
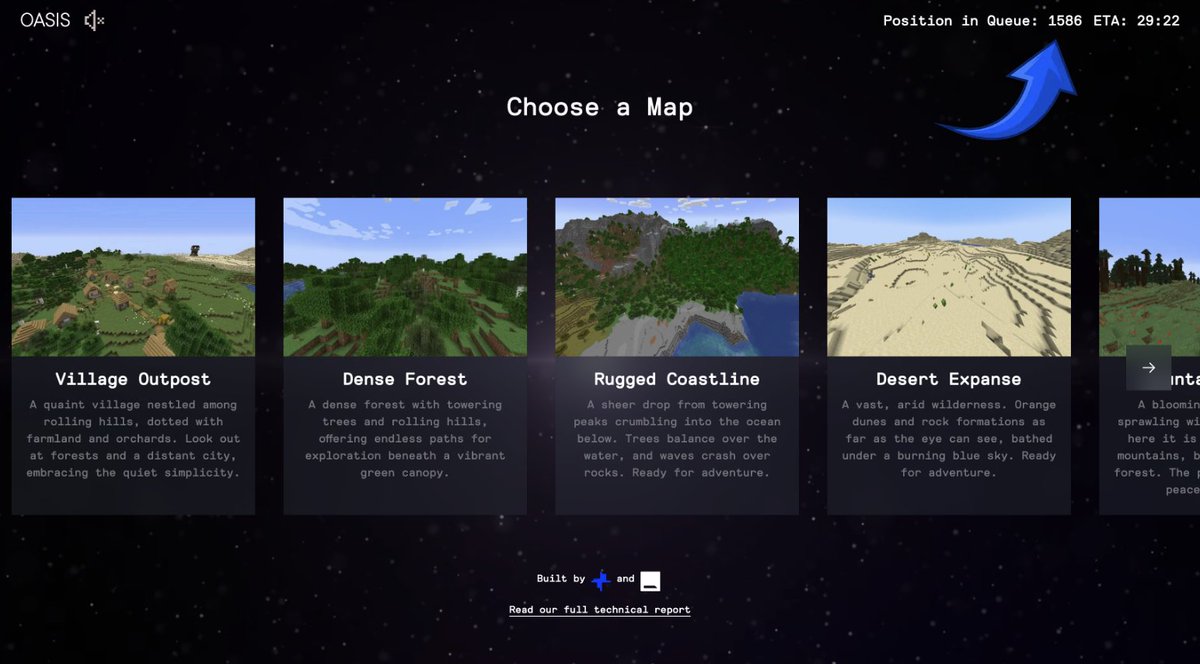
ALT Number of people in the queue
19
12
170
45,641
Introducing Oasis: the first playable AI-generated game.
We partnered with @DecartAI to build a real-time, interactive world model that runs >10x faster on Sohu. We're open-sourcing the model architecture, weights, and research.
Here's how it works (and a demo you can play!):
1,408
1,077
12,264
24,646,005
You can play Oasis here: oasis.decart.ai
Learn more about the model and partnership here: etched.com/blog-posts/oasis
17
26
532
478,592
Oasis was trained on purely open-source data from VPT, OpenAI's open-source Minecraft dataset (MIT license)! You can learn more about that dataset here: github.com/openai/Video-Pre-…
9
4
208
467,467
Tens of thousands of people are using Oasis, the world's first AI-generated game. Try it yourself at oasis.decart.ai!
It's trained on purely open-source data from VPT, OpenAI's open-source Minecraft dataset (MIT license)!
6
5
55
18,848
Check out the open-source version (model weights and code) here: huggingface.co/Etched/oasis-…
You can learn more about that dataset here: github.com/openai/Video-Pre-…
1
18
102
31,157
You can play Oasis here: oasis.decart.ai
Learn more about the model and partnership here: etched.com/blog-posts/oasis
7
18
178
25,831
Today we announced our $120M fundraise to bring Sohu to the world. Thanks @edludlow for hosting us!

Meet Sohu, the fastest AI chip of all time.
With over 500,000 tokens per second running Llama 70B, Sohu lets you build products that are impossible on GPUs. One 8xSohu server replaces 160 H100s.
Sohu is the first specialized chip (ASIC) for transformer models. By specializing, we get way more performance: Sohu can’t run CNNs, LSTMs, SSMs, or any other AI models.
Today, every major AI product (ChatGPT, Claude, Gemini, Sora) is powered by transformers. Within a few years, every large AI model will run on custom chips.
Here’s why specialized chips are inevitable:
27
81
530
117,688
Etched retweeted

25 Jun 2024
INTERVIEW WITH FOUNDERS OF @ETCHED
the thiel fellows fighting nvidia
- @UbertiGavin & @robertwachen on AI chips
- Debating future unemployment predictions
- AI's impact on long term GDP growth
- Raising their $120m Series A
- Slow vs Fast Takeoffs
- much more.
20
74
618
98,529
GPUs aren’t getting better, they’re just getting bigger. In the past four years, compute density (TFLOPS/mm^2) has only improved by ~15%.
Next-gen GPUs (NVIDIA B200, AMD MI300X, Intel Gaudi 3, AWS Trainium2, etc.) are now counting two chips as one card to “double” their performance.
With Moore’s law slowing, the only way to improve performance is specialization.
The economics of scale are changing
Today, AI models cost $1B to train and will be used for $10B in inference. At this scale, a 1% improvement would justify a $50-100M custom chip project.
ASICs are 10-100x faster than GPUs. When bitcoin miners hit the market in 2014, it became cheaper to throw out GPUs than to use them to mine bitcoin.
With billions of dollars on the line, the same is happening for AI.
11
70
537
116,550
Thank you to all our supporters - @peterthiel, @ashtom, @jasoncwarner, @amasad, @kvogt, @balajis, @kevinhartz, @immad, @bryan_johnson, @amiruci, @novogratz, David Siegel, Stanley Druckenmiller and many more.
9
11
238
93,930