
5 Apr 2025
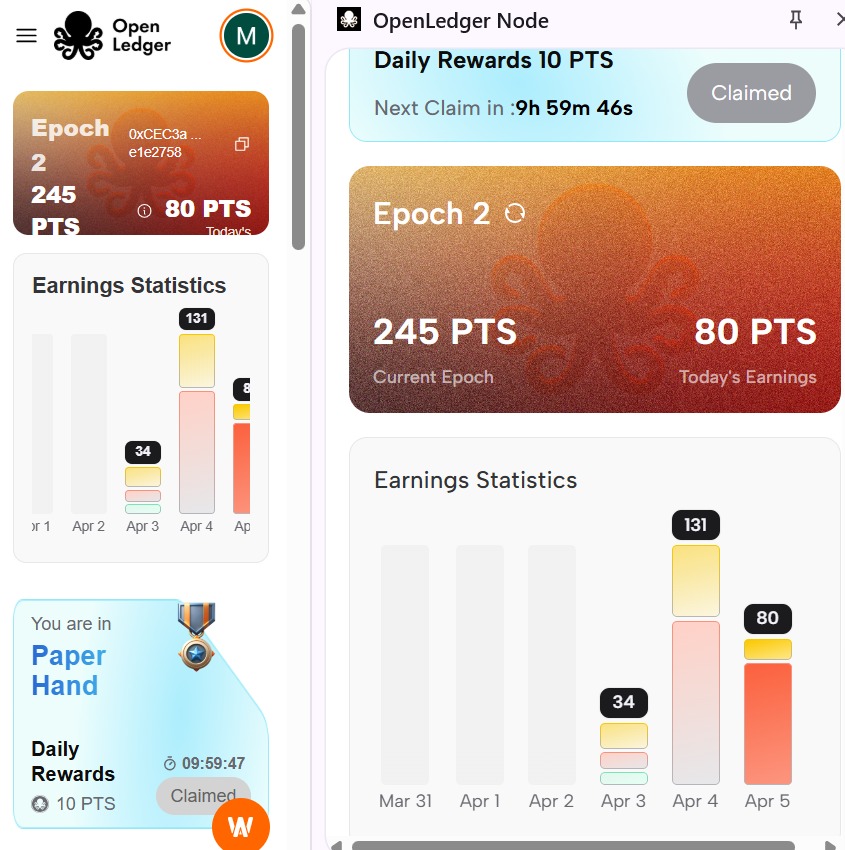
2nd day on @OpenledgerHQ ☺️⚕️, I have now earned about 245 heartbeat points 🫶. I'm increasingly contributing to Openledger's testnet infrastructure, and I'd be proud to say sometime in the future, that I was part of the test phase that brought about the game changing Tech 🤭💜.
***
Ooooh so yesterday I was yapping about @OpenledgerHQ 🐙 and how their innovative tech of developing AI models on a decentralized infrastructure would be a game changer for the Web 3 and AI world. I gave some insights on how the tech would make it possible for developers of various AI models get access to data, which would then be used in creating and fine-tuning other AI models for different applicationsp🔥.
(If you don't understand, or you're curious how, just go through the quoted tweet, it's just a 2 minute read 🥹😂).
⚕️⚕️
Have you ever tried researching on a particular topic and the output (replies) you're getting from the AI model weren't aligning with what you needed? 😩, that can be so frustrating right?, puting into account the time you've spent already which would have been solved if the AI model was well equipped with Datasets from that particular topic/industry.
Well, we're Twins 🙂↕️, same happened to me also.
Two weeks ago, I was researching on a particular topic because I needed more knowledge on it. It was about fitness and recreation, braaah you needed to see the replies from the AI model 😭, ain't lying, but broo is dumb asf. Intelligence in the mud.
Why do you think that happened🥲? Isn't an AI supposed to be smart?!, How come sometimes they sound like a layman with no idea about the topic😞.
Well the reason that happens is because the developers of the Ai model didn't train the model with vast amount of data- especially from that domain/industry(i.e; fitness) needed to provide quality outputs based on a prompt or question asked by users🫴.
Well @OpenledgerHQ said; enough is enough, AI's are supposed to be smart not slow, and it's about time we come about some change👏.
One of Openledger's aims is to ;
∆ Facilitate specialized data collection
What even is this jargon right 😡?,
Well it requires expertise and skills to collate quality data that'd meet the requirements of a particular Industry, So openledger is coming out to say they'd make this easy 👏.
How is this or how can this be possible?
1. Openledger will collect and provide only high quality data 🥹🔥, and will also reward the contributors. Openledger doesn't settle for less!, She's building a decentralized Infra for AI applications, so nothing but the best will be used 👏.
By collating high quality data alone, we can be rest assured that we(me and you) will always get accurate and relevant outputs(replies) from researches we are making with the help of AI models 😍.
2. Openledger will collect domain/industry specific data
There are more than 15 well known domains/ industries, i.e;
~Manufacturing and production
~ Education
~Media and entertainment
~Sports and fitness. Etc
So Openledger will ensure they aggregate data from all domains and make the datasets accessible to all developers needed for the fine-tuning of AI models 👏🔥.
Meaning, with the open and accessible datasets from @OpenledgerHQ , you can get the best experience from AI applications that were created and fine-tuned on Openledger's decentralized infrastructure 😍😍.
You might be wondering or might need to know..........
-How does Openledger aggregates, validates and make domain specific datasets accessible to all developers which would be needed for AI models fine-tuning 🤔?
Say no more bby 🙅♂️
Openledger does so with the help of their DATANETS
we'd talk more about Openledger's Datanets some other time 😂🫵.
Suspense 😂🤎.
Decentralized infrastructure for AI applications with access to High-quality data from different domains while rewarding contributors and keeping everything Open on a Blockchain network..........that's how I define Openledger 🐙🐙.
4 Apr 2025

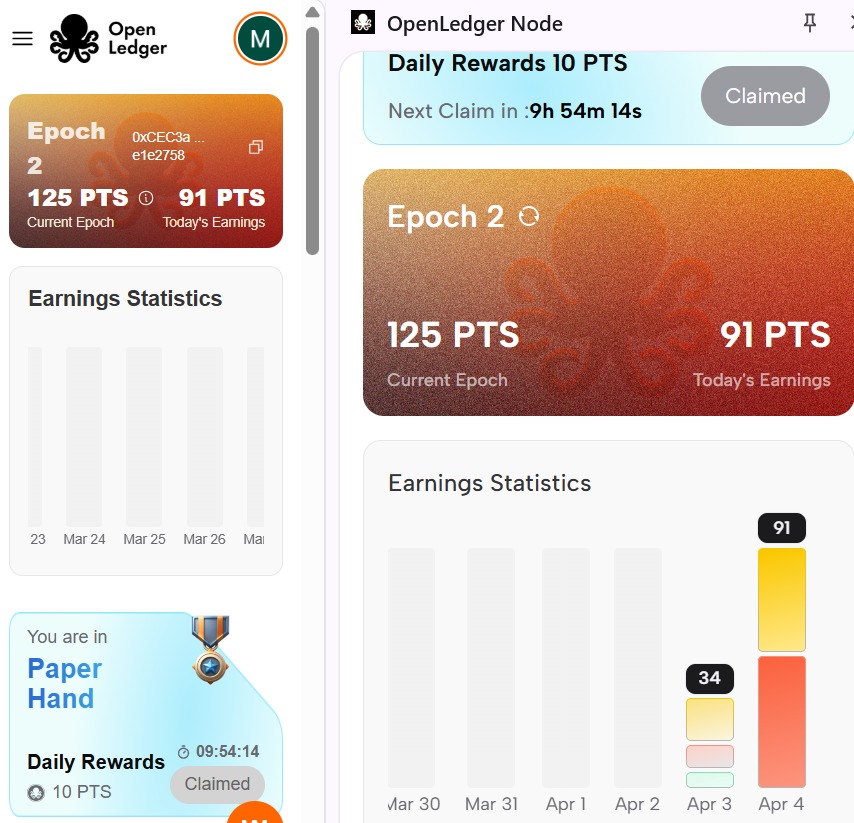
Just got onboarded to @OpenledgerHQ yesterday after they gave access to the public and I've earned about 125 heartbeat points just by sharing my bandwidth and contributing to the Testnet Infrastructure 🤭😂.
***
You might be wondering, what even is openledger 😩, is it a crypto ledger that is opened? Or is it a financial ledger where you record all revenue and expenses? Naah!, none of that 🫵.
We're all web 3 chads right? We believe and we're all proponents of decentralization right?, We're seeing an outburst of AI in society, AI models are becoming a thing- replicating human art and making it better.
ChatGPT-4o in mention just got a big boost with image generation, and can make cool pics like Studio Ghibli style which is trending currently☺️.
Everyone loved it, and other AI companies started training their models to generate similar results 🫡.
⚕️⚕️
Just as Satoshi Nakamoto thought about the decentralized web- where everyone has full control over their data and can access them from a source without a particular entity being in control of it alone, have we ever had same thoughts with AI models 🫠?
Popular AI models like Meta's Llama 3.2, Open AI's GPT model or Google's Gemini are all built on a centralized infrastructure (Whenever I hear the word centralized, I feel nauseous🤢), Meaning no one have access to the data being used to train and fine-tune these beautiful Models 😩.
Developers of AI models need access to these data to create and train other Models, but because of the centralized nature of the existing Models, they cannot be accessed 😩💔.
⚕️
As a developer looking to create AI models that serve a specific purpose, you need vast amount of data to train and fine-tune the Models you're creating, and what happens when you can't get these data because of a so called centralized authority? do you give up? Damn, all those efforts, dreams, hard work, gonna go down the drain? .....The answer is a NO, This is where @OpenledgerHQ comes in with a back flip stunt😩🙌🔥.
Open ledger sees this limitations to AI Models development and came up with a solution................... Creating a decentralized infrastructure that supports the development of AI Models.
⚕️
Some might be wondering, why do we even need this tech 😩, is it even Important?
Ok, just Chill......... i'd highlighted 2 things the dominance of centralized AI models can cause 🥹.
1 is; stifle innovation
Yes!, they have vast amount of data that can be used by other developers to develop more unique AI applications through Models but they don't share it 😩, lack of collaboration hinders growth, whether in the Web 3 or web 2 space 🫴🫴.
2 is: The dominance can raise concern about bias and fairness
Yes!, that's another one(dj Khaled! 🤭), since the source of data is not available to all, no one can analyze the data to see what's being used to train their models, meaning the Models might provide a different output to a particular sets of group/race causing unfairness🙅♂️.
****
Meaning, with Openledger - Developers will be able to access the data used to train already existing super models, and they can use these data to create new AI models with different functionalities which will serve for AI applications, while maintaining fairness and integrity 🤭🫶.
But One of the limitations faced by Blockchain technology is scalability 😞. Anyone scared AI models may not be Scalable enough if they're created on a decentralized Infra? 🥲.
Yeaa, I was also, until I discovered Openledger will be leveraging the L2 scaling solutions built on OP stack🔥.
"This is just a way to improve how the Blockchain network can handle traffic without breaking down, by performing the transactions offchain and verifying onchain"
Openledger also uses @eigen_da for data availability ensuring the security & the availability of data to all developers out there 🫡🥂.
Openledger is the future of AI applications 🔥🔥.
Pivot to Openledger now 🐙🐙.
4
1
14
632