

Jun 12
Found the secret. If you pop out this post while its playing it will autoloop and keep you company as you scroll.
1
1
51


Jun 11
Changed our PFP to our logo!
An interesting fact about Spark & loop engineering:
We built a framework for self-improving loops under the Spark Domain Chip Labs before loop engineering got hot.
Our logo symbolizes evolving loops rather than symmetrical, non-growing ones.
We think this is the future, and you can already test what we built inside the Spark Domain Chip Labs repo.
It comes with a system for:
- creating specialization on any domain
- building a benchmark around that
- and then having an autoloop that grows
Github: github.com/vibeforge1111/spa…

16
13
97
2,798

Local businesses miss calls, lose leads, and forget follow-ups. Every single day. I built AutoLoop — AI agents that handle lead follow-up, appointment booking, and customer support on autopilot. No more manual chasing. autoloop-3.polsia.app
7

This hokey clown is an autoloop sales pitch bot. Say it again, parrot. Try to sell us shit with some "aw shucks golly" rage bait.
6

Most AI agents do not improve.
They just repeat.
A loop is not enough.
The agent needs a judge.
That judge is the eval.
Without it, the loop only spins.
With it:
- attempts get scored
- weak changes roll back
- better versions survive
That is the difference between a loop and an autoloop.
Build one specialist.
Give it:
- workflow
- tools
- benchmark
Then let it improve while you sleep.
The eval is not the boring part.
The eval is the product.
Bookmark this before you build another busy agent.

9
3
65
5,968

Jun 3
Spark r24 is here and here is the changelog:
## spark-compete
- Added durable R24 scoring docs, ledgers, dry-runs, and guarded apply scripts.
- Added separate scoring lanes for missing rows, packet audit, status evidence, private score, public publish, adopted repair, identity correction, and final leaderboard apply.
- Added R23 scoring methodology docs so future leaderboard passes are faster and more consistent.
- Fixed final R24 team attribution issues before leaderboard publish.
## spark-cli
- Refreshed R24 registry pins and installer metadata.
- Added `spark search --json` for agent-friendly registry lookup.
- Improved JSON success contracts, including `ok` behavior for compile summaries.
- Improved provider doctor errors for HTTP, network, and invalid JSON failures.
- Improved malformed or missing `spark.toml` handling with clearer CLI errors.
- Improved `spark init` TOML escaping.
- Improved browser-use JSON path redaction.
- Hardened support bundle and doctor-report privacy handling.
- Tightened URL policy around trailing dots and metadata-host blocking
## spark-telegram-bot
- Improved local Spark service intent detection to avoid false positives.
- Improved Telegram completion report handling so reports do not end mid-report.
- Added safer sanitized warning behavior for delayed completion summary failures.
- Improved timeout/env validation for mission control, relay, voice bridge, LLM clarification, chip loop, and path loop settings.
- Added TTL/pruning improvements for long-lived mission/task caches.
- Improved operator docs for health polling and installed module paths.
## vibeship-spawner-ui
- Improved corrupted active-mission recovery with bounded inactive/corrupt state handling.
- Improved scheduler state robustness around corrupted schedules, crash recovery, next-fire calculation, and fallback saves.
- Improved mission-control and creator-mission state writes with temp-and-rename patterns.
- Improved HTTP/non-JSON error handling across scheduler, mission board, access lane, memory quality, and provider-runtime paths.
- Added many safe JSON parse guards across persisted provider results, mission state, skill manifests, dashboard snapshots, and event relay state.
## spark-researcher
- Improved external chip defaults so new chips use `~/.spark/chips` instead of Desktop-only paths.
- Improved missing-config JSON guidance and config-path redaction.
- Added timeout handling around researcher subprocess paths.
- Improved corrupted JSON/JSONL handling across memory, proposals, reviews, collective loaders, and failure status.
- Improved autoloop and adapter error clarity.
- Improved web-result and web-note response cleanup to avoid resource leaks.
- Improved atomic writes for trainer and trial queue state.
## spark-character
- Improved dash-family scoring and audit behavior with focused tests.
- Added bounded timeout behavior for lowest-tier evolution subprocesses.
- Treated live-search snippets and titles as untrusted quoted source text.
- Improved malformed YAML and malformed base chip handling.
- Improved provider error clarity when gateway responses are HTML instead of JSON.
- Improved live-search failure logging.
- Improved persona pointer cleanup and trait-mutator validation for NaN/Infinity deltas.
- Improved voice corpus loading for missing or malformed JSON.
## spark-voice-comms
- Rejected invalid, non-object, or oversized hook inputs before dispatch.
- Added strict `voice.transcribe` base64 validation.
- Improved unsupported Kokoro runtime handling with structured failure.
- Improved env parsing and env-read failure visibility.
- Improved malformed voice profile JSON handling.
- Improved Kokoro TTS speed validation.
- Improved provider and voice-transcribe error messages.
- Improved delivery trace safety and import-wrapper behavior.
## spark-personality-chip-labs
- Improved registry assign/default errors so missing targets list installed personality IDs.
- Improved active personality chip diagnostics by naming configured personality IDs.
- Added safer atomic JSON cache writes.
- Improved bridge staleness timestamp parsing.
- Improved empty voice-signature handling.
- Improved bridge cleanup with safer file unlink behavior.
## spark-domain-chip-labs
- Added or represented CLI usability improvements such as `--version`.
- Improved artifact-quality validation messages by naming allowed reviewer verdicts.
- Kept related changes gated where scoring or release proof was not ready.
## spark-intelligence-builder
- Improved Builder chip-hook privacy by removing local `.env` file paths from payloads.
- Improved auth-provider errors by naming known provider IDs.
- Carried Builder adoption work through maintainer paths without giving duplicate carrier credit.
4444 points have been added during this update to Spark Compete leaderboard. Special thanks to all the open source contributors!
14
14
86
3,779


May 26
At GitHub Next, the Autoloop agent is porting Pandas to Typescript
Read about this experiment in simple, declarative goal-directed repository automation!
githubnext.com/posts/tsb/
1
1
12
2,033

May 21
What if you guys just ran it on autoloop, for all theorems? Prove or disprove open problems.
Make no mistakes @ThePrimeagen

1
2
106
May 15
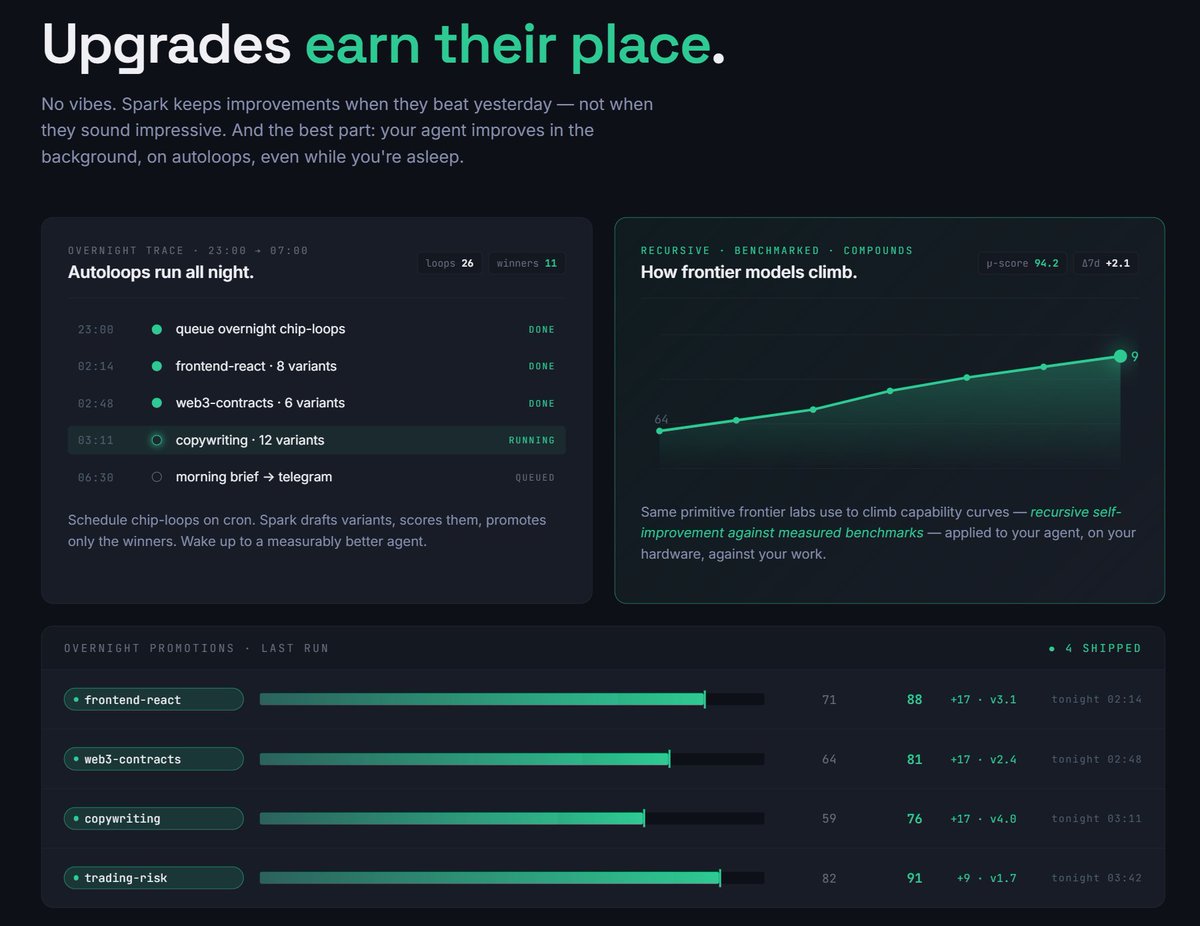
Spark takes its self-improvement loop from the methodology that created the best AI models.
Benchmark evaluated, recursive self-improvements.
The special part is that your Spark agent can apply this to master your workflows.
creating
> the benchmark
> specialization path autoloop
> then self-improving even while you sleep
so that it can serve you better as a personal agent.
25
42
268
10,787

提到 autoloop 尤其是我以前讲的issue驱动 还有提到Github是能够让人、Agent、cli 协同合作的最佳范式!
所以我并不是现在出来吹multica 而是我曾经有很多想法和multica不谋而合!
不得不说我作为传统制造业出身
一个行外人既没有接触前沿领域也不会写代码,但是对技术的发展还是有洞察之力!
不行了!让我双手插兜牛逼一会儿!
其实仔细想想 我以前很多project都可以进一步上升形成可行的产品而不是Github的一个小项目!
知行合一 现在的我比以前更自洽了!😁

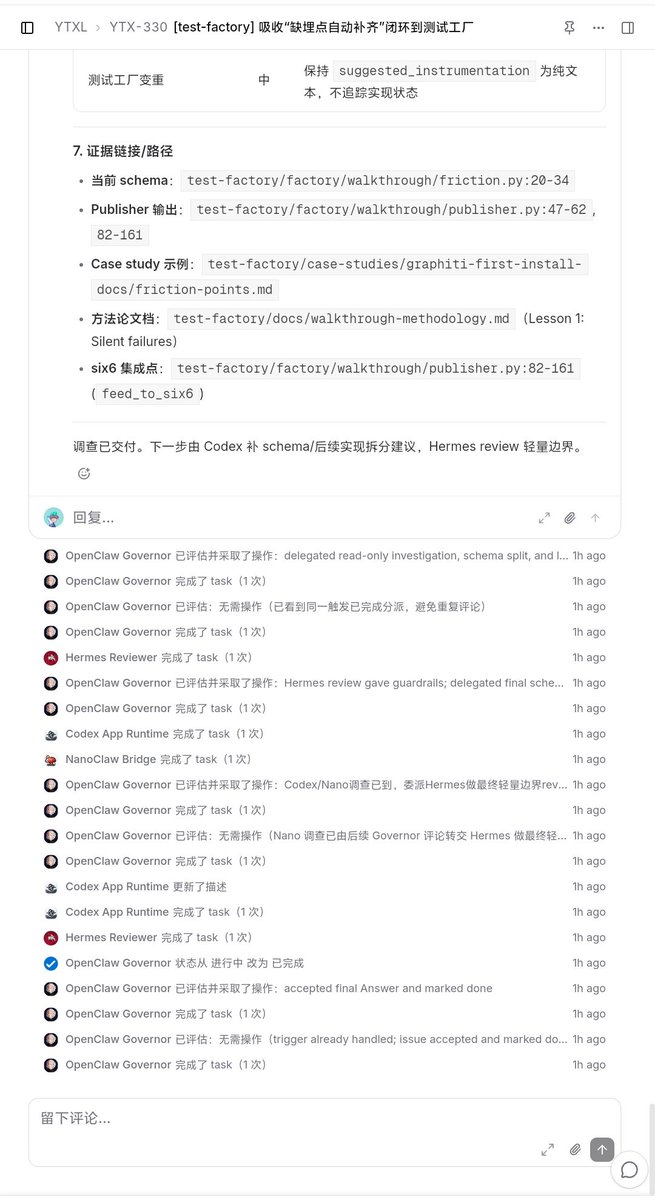
还是不得不对multica的小分队功能提出赞赏,让多Agent之间的协作丝滑如流水而且节省时间,我以前都是靠autopilot功能驱动Agent进行review和done的推动,现在小分队出动任务直接解决!
同时我也为自己的机智感到沾沾自喜!最终答案写回 issue 描述下方这个操作神之一手啊!
从任务到答案我直接看结果就行!
如果你之前用过或者听说过我的autoloop那么一定要尝试下这个名为“squads”的更新!
现在来看,AI往前发展就是要逐步弱化提示词的作用,我记得几年前提示词工程师这个概念出来的时候,大家还趋之若鹜,现在呢?!提示词这事情本来就是应该由厂商来做,我们用户无感使用就行!

2
466
还是不得不对multica的小分队功能提出赞赏,让多Agent之间的协作丝滑如流水而且节省时间,我以前都是靠autopilot功能驱动Agent进行review和done的推动,现在小分队出动任务直接解决!
同时我也为自己的机智感到沾沾自喜!最终答案写回 issue 描述下方这个操作神之一手啊!
从任务到答案我直接看结果就行!
如果你之前用过或者听说过我的autoloop那么一定要尝试下这个名为“squads”的更新!
现在来看,AI往前发展就是要逐步弱化提示词的作用,我记得几年前提示词工程师这个概念出来的时候,大家还趋之若鹜,现在呢?!提示词这事情本来就是应该由厂商来做,我们用户无感使用就行!
#multica
两个办法让multica的issue可读性提高80%
众所周知大家都不喜欢看公式,就像之前霍金讲书里每多一个公式销量下滑一半!
multica issue也是,本来我好好的下发一个任务,Agent一边做一边给我冒出来大段的专业术语不说居然还给我会标明文件路径,一大串完全没有可读性,不过这两天我进化了一下,让issue可读性大大提高,至少我作为一个非coder能看懂,能知道他干了啥!
首先第一条:任务下发要走模版,不能把你的命令编码成看不懂的东西,比如我昨晚给他发的任务他拆解成目标、背景、边界、验收标注(指明是一份报告还是一份PR merge)还有干活的先后顺序,约束起来。这个约束条件之前有一点但是也不多,吸收了HN文章中的clipboard机制,感觉做的更好了!
第二条也是我最关心的一条,验收标准,issue做完做了啥,成果在哪里?!
以前做完了都是夹杂在评论区,我要去翻,这也还行,最关键的是完全看不懂在做啥,全部嗲是专业术语一脸懵逼,有时候你还得通过读评论区组装起来才明白做了啥!
现在就好,我给他讲清楚写明白验收标准:
1. 最终答案写回 issue 描述下方
2. 评论区只放过程、分派、review 记录
3. 附件放完整报告/证据
4. 不把关键结论藏在 thread 或动态底部
而且要把这套标准放到小分队的规则之中!现在来看就很合理易读,你的任务是什么 罗列七八条,然后最终的结果是什么罗列出来 一目了然!
而且也可以要求他用.md文件的格式在multica issue中生成报告!或许也能生成图片之类没有去尝试!
总之 现在issue我能看懂了!也把这个漂亮的看板功能利用起来,再也不会两眼一抹黑。


3
1,065

May 13
Got a samsung ultra, screen long enough to do split screen for both, have tiktok on autoloop. Brainroot speed running
3
2
72

Shift to basal bolus regime.
Somogyi is a thing of the past in the basal bolus era.
Or shift to twice daily insulin degludec/insulin aspart combination.
If affording, club with stand alone CGM or even can consider Insulin pump with CGM in autoloop.
1
1
2
1,313

the choice micro to macro of the feelin of biased justififation of morals with the ego the thought has scripted whole narrative for and realaf movie..it actually feels real cos my ego justified an imagination on no measurement. these spells is connected to a definition created by the master spell masters. attached to these chains or official definitions with common inconsistency interpreration based on imagination designed by invisible fear jail. u do not choose the truth ur seeking validation to justify cheatin on a feelin that feels weird but the lable designed to compound layers of imagination narratives has the legal laws of safety. the countries the news u cannot validate the source. seekin patterns the addiction to biasly satisyin. larger numbers doesnt evidently mean power its jus a label narrative of pattern sequence to empathetic comfort by energy alignment as its the main source. start or no start. the narrative or start by official dictionary created by man to make this environment. each word each spell. even when u dont speak outloud the choice of spell u keep thinkin about the voice in ur head. nobody watchin n principles is a label of unconfirmed narrative judged by ur dependency for man made validaton narrative to justify continuing the ego desire narrative submitted to man made scary spells to protect this single dimension..the designer or dimension spell is not the authority. we spawn no memory we learn spells. we taught n see common pattern of nice winning feelin feels so nice. nice traits creates an addictive xp n justify bein nice by biased interpretation of official dictionary spell chains. submittin to participatin in learnin to be inclusive the fear of imaginational ego justification.
cheat code
as we r addicted to spell manifest desirable feelin outcome for our imagination feelin sensation
whatever your dream is do you really think its the possible of all? the submission is acceptin the autoloop compounded through recycled spell feelings to autopilot ur justificaton
the truth is no label no definition. frequency n the feelin intensity of ego discomfort or pleasurable. the loop to delete words creates a ripple effect of thoughts thinking and decodin not realisin the loop is the feelin formed by trauma feelin missions thats been avoided based on thought decodin justification measured by space and time designed with historical evidence based on moral ego narrative again avoidin the fear. the booby trap of submittin to the dream n if each dream is based on the outcome we desire. if it wasnt for desire then y does it bother the ego. ur loops ur spells ur choice ur desire or wu wei no labels no narratives no reason to justify a high lvl spell combo with compounded layers of evidence with common unconfirmed source but just to the submission its not possible. the not possible spell combo is an easy measurement of spell choice selection is clear evidence ur beleif isthe creator of this.
memories is the library of scene generation categorised as feelin moments..if ur able to access your internal dialogue transcript u will see patterns of feelin labels which move combo used by familiarity optimisin moves for ego chosen feelin. with labels created by man with man made bias feelin interpretation of man made definitions is intentional. measurement is not possible its a design with man approved bias
4
200
#multica #虫巢计划
简单快速讲讲我为什么选择 multica 以及为什么我说six6这个框架天生适合 multica
背景:目前我重新启动了三只claw,他们分别是vps上openclaw 架构的小灵,这个也是老读者最常听到的名字,我和他之间三个月的深度聊天已经足以让他了解我的方方面面;然后是macbook上的hermes 架构的赫妹以及nanoclaw架构的🍅claw。
我也不是闲着瞎折腾三只claw,一方面这是我的虫巢计划一个环节,另外一方面总不能出一个claw我们就抛弃掉彻底转向吧!我想要的是依据不同的架构特性给他们安排符合特性的定位。我其实给自己定位是个Agent测评玩家。
然后nanoclaw 已经受我影响搭建了一套测试工厂的雏形,我也不想放弃这个心血之作,尤其是这也是six6这个 skill 的形态之一,six6 就像是安卓操作系统,测试工厂就是手机上的app。
然后我为什没有选择slock.ai
主要原因还是太复杂,而且和我的定位不符合,我进入界面之后,只能选择mac上的claude code gemini 这些cli,但是我想要的是让拥有我记忆的claw合作。
为什么说six6这个框架天然适合在multica
先介绍一个six6,这是一个由白日梦/冥想/农场/autoloop/monitor/memory 组成的skill 群组。
其中白日梦负责发散思维产生创意种子到农场,claw 会对农场中的种子进行浇水,等到成熟度到达80%就进入Github 挂issue 然后进入autoloop机制,autoloop是受卡帕西影响,核心机制是Claude code 第一轮做完任务,然后间隔半小时会新启一个session对上一轮的成果进行审核,避免一个session一口作气出幻觉,然后如果第一轮失败会带着第一轮的经验进行第二轮尝试,如此三次失败最后进入humanloop评判。
冥想是用来观察一整天下来的内容对流程进行优化,monitor是观察整个系统中的阻塞然后开issue让Agent 进行修理。
为什么说契合:
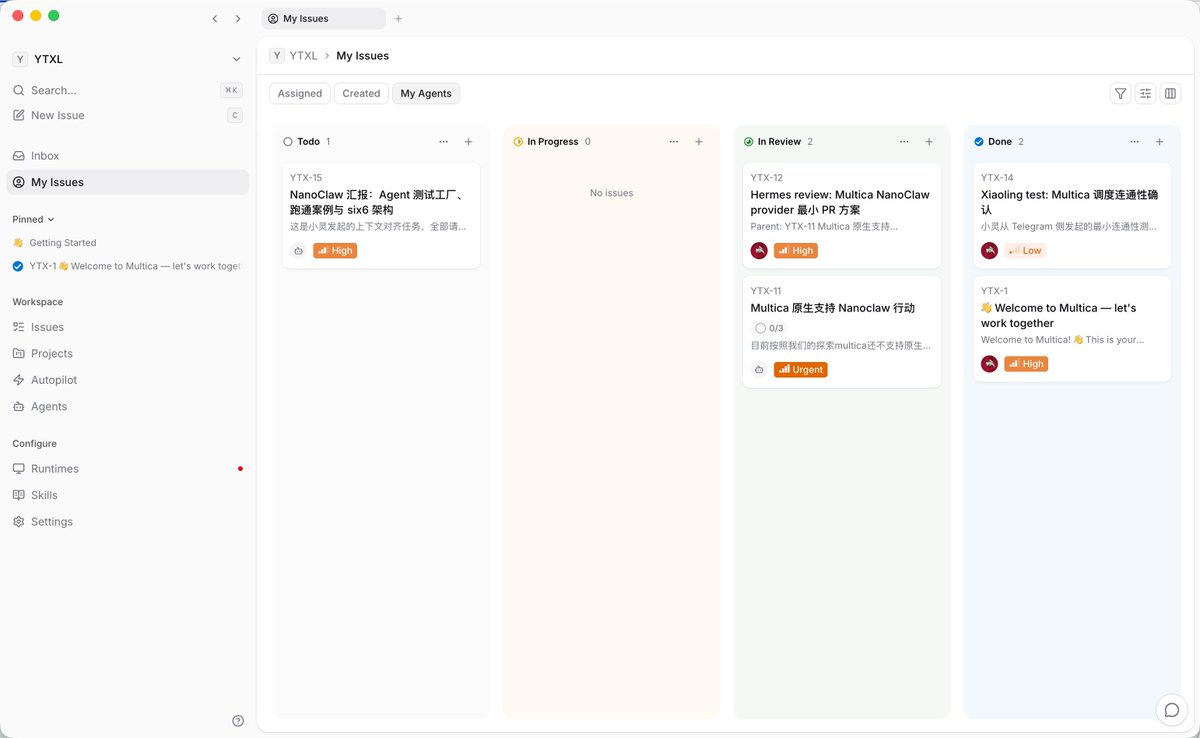
上边的一切其实终点就是issue机制,multica 的核心思想也是如此,说他是agent合作的平台不如说是Agent 平台的github。
我今天发现,我让claw去开单一个to do issue ,可以@特定的agent 进行作业,完成之后会进入in reivew 的阶段,我为了让这个阶段更自动化,我会让第一个@agent做完之后工作放置到in review 的阶段后自己@审核agent来做,这样自然出发审核不用人类来判断,这种机制正好和autoloop完美匹配!
然后剩下的白日梦和农场 这两个也可以使用Issue 的形式来进行表征,成熟度也可以引入在mulltica中,这样我的six6架构基本就在multica中成熟。
最后最关键的是 multica 有cli 那这套模式就是天生的Agent驱动的,这也是我很喜欢的一点。
ok 暂时就介绍到这里,等后边我上手了来再说更多的内容!
Apr 28

OpenAI Symphony is great, but what if you don’t want to be limited to Codex? If you want to use Claude Code, Hermes, OpenClaw, Cursor Agent, or many other coding agents, Multica is built for that.
1
1
16
5,601
