
Build performance is a bottleneck in HPC.
Without visibility, it’s hard to know where time is going. CMake and CDash instrumentation help surface those inefficiencies.
Watch how: ow.ly/Oh5G50Z4LLN
#CDash #CMakeTools #TechInsights #HPSF
2
181


May 27
Earlier this month, many Bitcoin Core developers met up in Barcelona, Spain as part of their regular twice-yearly in person meetings.
Attendees volunteered to take notes on the unconference-style sessions and the transcripts have been added to the BTC transcripts website:
- AI session
- ASMap
- BIP324 and group policy options
- BIPs editors
- Bitcoin TUI
- CAmount
- CDash
- Coins cache
- Erlay redesign
- External interfaces
- GUI repo
- Inventory send queue
- Kernel (laundry list, overview, session)
- Libevent
- Logging
- Modern crypto library
- Mutation testing
- Package relay
- Post-cluster mempool
- Private broadcast
- QML (planning, update)
- Silent payments
- Static builds
- SwiftSync
- TCP hole punching
- Template hash
Additional informal discussions, code reviews, working groups, or other sessions occurred on:
- Quantum
- Determinism in testing
- Testnet5
- MEVPool
- Wallet priorities
- Silent payments
- Coins caching
- Peer observer
- ASMap updates
- IPC updates
- Utility binaries
- Bitcoin Kernel
- QML GUI
- Deterministic simulation testing
- AI assisted code review
- BIP39 import
- BIP54
- Fuzz testing
- Mutation testing
- Static builds
- FIBRE updates
- Parallel block input fetching
btctranscripts.com/bitcoin-c…
4
18
58
5,028

May 11
🚀 MONDAY – BIG WEEK AHEAD FOR $RMV 🚀
Another massive week ahead for @Realitymeta 👇
🔥 RRush Rewards Finalization
Haven’t claimed yet?
➡️ Go to Reality Rush TG
➡️ Type: /my_rewards
🎮 Gamification is evolving FAST:
🟢 VIP Points
🟢 CDash integration
🟢 Bid2Earn
And this is only the beginning 👀
📚 Tuesday Topic:
“The Network Effect: Why Community Is Everything”
And honestly… the $RMV community is becoming one of the STRONGEST in crypto ❤️
📈 Momentum on X keeps growing:
🔥 Top 12
🔥 Top 10
🔥 Top 5
Let’s push even harder this week.
Comment under posts with:
👉 $RMV a short message
🎤 Thursday = AMA Day (TBC)
While most of crypto sleeps…
Reality Metaverse keeps building ⚡️
TG Discussion Group 👇
t.me/ KeNCmgFRF7szNDk0

May 10

Day by day I’m getting more and more bullish on $RMV @Realitymeta 💥
So many things are coming that people are highly unaware of it.
Monopoly launch will blast us massively.
Just get a NFTs and start earning income.
You also can spin the wheel and grab some for free.
Great project with great use cases.

15
2
18
555

2/ 🔥 RRush Rewards Finalization
If you have NOT claimed your rewards:
➡️ Go to Reality Rush TG
➡️ Type: /my_rewards
➡️ Follow the instructions
🎮 GAMIFICATION is evolving FAST.
The team already announced:
• VIP Points
• CDash integration
• Bid2Earn
We're ONLY beginning! 👇
2
7
138
3/x 🔥 WHAT’S COMING
VIP POINTS (Final Stage)
→ Medium article dropping this week
GAMIFICATION STARTING
→ CDash integration
→ Bid2Earn (NFT auctions)
Got ideas? Send them 👇
1
6
122

Apr 3
ABOUT TO CDASH TF OUT, I JUSG GOT HOME FROM MY LAB AND THERE IS A BIG ASS WASP JUST CAMPING ON MH HOUSE LIKE LEAVE PLSSSSSSSS, IM SCARED TO LEAVE MY CAR, YOUVE BEEN TAILONG ME SINCE TUESDAY 😭😭😭😭😭😭😭
4
8
374

Mar 11
Study Data Tabulation Model (SDTM)
A required standard for submitting clinical trial data to regulatory authorities like the FDA & PMDA. It defines a universal structure for organizing data into specific domains (e.g., Demographics (DM), Adverse Events (AE), Lab Results (LB)) to facilitate consistent review & analysis.
The SDTM is arguably the most well-recognized & widely implemented CDISC standard. It outlines a universal standard for how to structure & build content for data sets for individual clinical studies, while the Standard for Exchange of Nonclinical Data (SEND)allucent.com/resources/blog/… is an implementation of SDTM that provides the same structure to nonclinical data. Utilizing SDTM datasets allows for traceability to the source data, maintaining data integrity & quality. Following SDTM structures supports consistent data representation, reducing errors & discrepancies.
Both SDTM & SEND are required by the FDA in the United States, while the PMDA in Japan requires SDTM. Additionally, SDTM & SEND define each segment of data as a “domain,” which enables the agencies reviewing the data to find the information they need w/ limited to no study-specific understanding. These domains provide structure to all data, including highly specialized fields like pharmacokinetics (PK).allucent.com/resources/blog/…
allucent.com/resources/blog/…
{sdtm.oak} – SDTM (Study Data Tabulation Model) programming in R
{sdtm.oak} is an EDC (Electronic Data Capture systems) & Data Standard agnostic solution that enables the pharmaceutical programming community to develop CDISC SDTM datasets in R. The reusable algorithms concept in {sdtm.oak} provides a framework for modular programming & also can potentially automate SDTM creation based on the standard SDTM spec.
{sdtm.oak} is developed in collaboration w/ volunteers from several companies, including ROCHE, PFIZER, GSK, PATTERN INSTITUTE, TRANSITION TECHNOLOGIES SCIENCE, & ATORUS RESEARCH {sdtm.oak} is also sponsored by CDISC COSA w/ a vision of being part of CDISC 360 to address end-to-end standards development & implementation.
{sdtm.oak} package addresses a critical gap in the pharmaverse suite by enabling study programmers to create SDTM datasets in R, complementing the existing capabilities for ADaM, TLGs, eSubmission, etc.
{sdtm.oak} is designed to be highly versatile, accommodating varying raw data structures from different EDC systems & external vendors. Moreover, {sdtm.oak} is data standards agnostic, meaning it supports both CDISC-defined data collection standards (CDASH) & various proprietary data collection standards defined by pharmaceutical companies. The reusable algorithms concept in {sdtm.oak} provides a framework for modular programming, making it a valuable addition to the pharmaverse ecosystem.
PDF DOWNLOAD
phuse.s3.eu-central-1.amazon…
Algorithms & Sub-Algorithms
SDTM mappings are defined as algos that transform the collected (eCRF, eDT) source data into the target SDTM data model. Mapping algos are the backbone of the {sdtm.oak} - SDTM data transformation engine.
🔸Algos can be re-used across multiple SDTM domains.
🔸Algos are pre-specified for data collection standards in MDR (if applicable) to facilitate automation.
Sub-algorithms
{sdtm.oak} supports 2 levels for defining algorithms. For example, there are some SDTM mappings where a certain action has to be taken only when a condition is met. In such cases, the primary algo checks for the condition, & the sub-algorithm executes the mappings when the condition is met.
The permutation & combination of algorithms & sub-algorithms creates endless possibilities to accommodate different types of mappings.
pharmaverse.github.io/sdtm.o…
R provides a robust array of user-developed packages that can efficiently manipulate complex datasets, such as those based on the Study Data Tabulation Model (SDTM).
The process leverages R packages such as sas7bdat, tidyverse, haven, parsedate, dplyr, tidyr, & Hmisc.
researchgate.net/publication…

8 Aug 2025

The HADES PROJECT and The OHDSI (Odyssey) Consortium
Health-Analytics Data to Evidence Suite (HADES): Open-Source Software for Observational Research
HADES, an R package suite, leverages the globally adopted OMOP CDM for analyzing healthcare data. It transforms CDM data into diagnostics, statistics, and visuals, shaping clinical decisions. Researchers worldwide have utilized HADES in impactful studies, w/ open-source code for reproducibility. HADES’ liberal Apache v2.0 license fosters flexibility for collaboration, modification, & sharing. Designed for federated networks, HADES prioritizes privacy by localizing data & sharing analytics.
pmc.ncbi.nlm.nih.gov/article…
Access HADES at:
ohdsi.github.io/Hades/
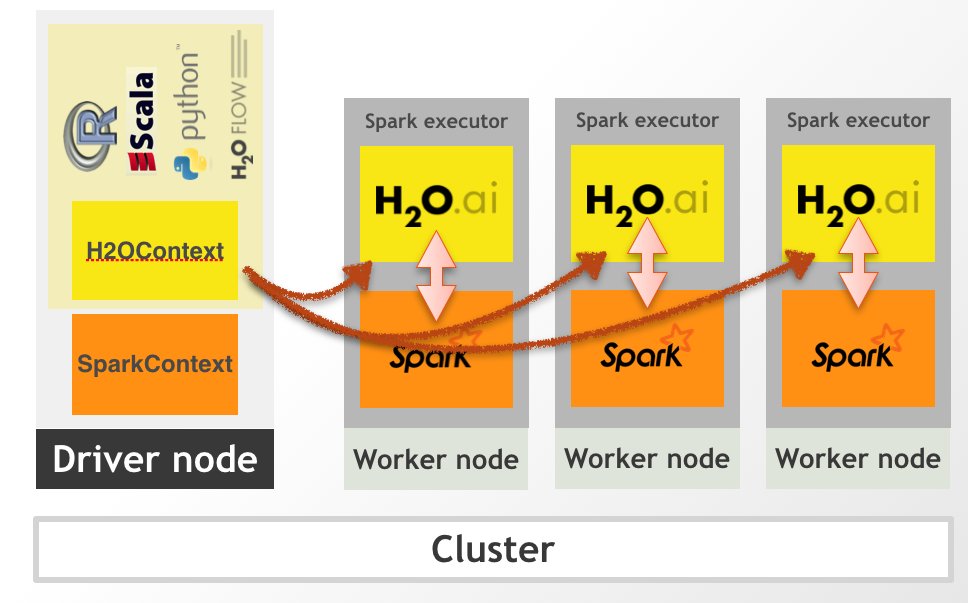
sparklyr:R Interface to Apache Spark
R interface to Apache Spark, a fast & general engine for big data processing, see <spark.apache.org/>. This package supports connecting to local & remote Apache Spark clusters, provides a 'dplyr' compatible back-end, & provides an interface to Spark's built-in machine learning algorithms.
sparklyr.r-universe.dev/spar…
R interface for Apache Spark
spark.posit.co/
Hydra
An R package and Java library for hydrating package skeletons into executable R study packages based on specifications in JSON format.
ohdsi.github.io/Hydra/
AsynchroNous Disk-based Representation of MassivE DAta (ANDROMEDA)
Storing very large data objects on a local drive, while still making it possible to manipulate the data in an efficient manner.
ohdsi.github.io/Andromeda/
Cyclops (Cyclic coordinate descent for logistic, Poisson & survival analysis)
An R package for performing large scale regularized regressions.
ohdsi.github.io/Cyclops/
BigKnn
An R package implementing a large scale k-nearest neighbor (KNN) classifier using the Lucene search engine.
ohdsi.github.io/BigKnn/
Apache Lucene
Lucene Core
Lucene Core is a Java library providing powerful indexing & search features, as well as spellchecking, hit highlighting & advanced analysis/tokenization capabilities. The PyLucene sub project provides Python bindings for Lucene Core.
lucene.apache.org/
PyLucene
PyLucene is a Python extension for accessing Java Lucene™. Its goal is to allow you to use Lucene's text indexing & searching capabilities from Python. PyLucene is not a Lucene port but a Python wrapper around Java Lucene. PyLucene embeds a Java VM w/ Lucene into a Python process. The PyLucene Python extension, a Python module called lucene is machine-generated by JCC.
PyLucene is built with JCC, a C code generator that makes it possible to call into Java classes from Python via Java's Native Invocation Interface (JNI). Sources for JCC are included w/ the PyLucene sources.
lucene.apache.org/pylucene/
lucene.apache.org/pylucene/f…
Automated Characterization of Health Information at Large-Scale Longitudinal Evidence Systems (ACHILLES) Achilles provides descriptive statistics on an OMOP CDM database.
Performs broad database characterizationExport feature for ARES
ohdsi.github.io/Achilles/
A Research Exploration System (ARES)
ohdsi.github.io/Ares/
github.com/OHDSI/Ares
FeaturesExtraction
An R package for generating features (covariates) for a cohort using data in the Common Data Model.
ohdsi.github.io/FeatureExtra…
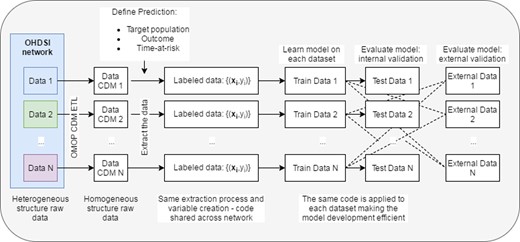
OMOP CDM (Common Data Model)
ohdsi.github.io/CommonDataMo…
OMOP CDM v5.4
This is the latest version of the OMOP CDM.
ohdsi.github.io/CommonDataMo…
The cdm reference
A cdm reference is a single R object that represents OMOP CDM data. A cdm reference is a list of tables. These tables come in three types: standard OMOP CDM tables, cohort tables, & other auxiliary tables. The tables in the cdm reference may be in a database, but a cdm reference may also contain OMOP CDM tables that are in dataframes or tibbles, or in arrow.
cloud.r-project.org/web/pack…
CDMConnector 2.0.0
CDMConnector is meant to be the entry point for composable tidyverse tidyverse.org/ style data analysis operations on an OMOP CDM.
darwin-eu.github.io/CDMConne…


1
13
18
757

Feb 12
Before biotech, there was candy. 🍬 With Valentine's Day right around the corner, did you know that Cambridge once produced some of America’s most beloved sweets, and many of the factory buildings are still standing!?
📸: Cambridge Historical Commission's CDASH tool
6
549

Jan 30
What did they do? I think you could argue box specific tech should be banned. But overall having easier ewgf/cdash is fine with me tbh because high level kazuyas aren’t really fucking that up anyway
1
235

thats basically how i do but mirrored
wasd, tab for map, j jump, k attack, L focus, ; quick cast, i dreamnail, u cdash
4
1,505



31 Oct 2025
Last week many Bitcoin Core developers met up in Frankfurt, Germany as part of their regular twice-yearly in person meetings.
Attendees volunteered to take notes on the unconference-style sessions and I have a pull request to add the notes to the BTC transcripts website:
- ASMap
- Batch Validation
- Secp256k1 and quantum
- CISA
- Cluster mempool
- CMake
- CoreCheck
- Debugging
- Fuzzamoto
- Libsha
- Multiprocess and Mining Interface
- Fingerprinting
- Net / net_processing split
- Package relay
- Private broadcast
- Security audit
- Subject matter experts and working groups
- Sockets abstraction
Additional informal discussions, code reviews, working groups, or other sessions occurred on:
- BIP 3
- Wallet priorities
- Compact Block prefills
- Silent Payments
- btck
- CI
- SwiftSync
- Benchmarking and IBD
- When do Bitcoin Core users upgrade?
- MuSig2
- Kernel
- Working in-person
- Complications with fuzz testing
- BlockTemplateManager
- QML GUI
- Shared Templates BIP
- Headers-first sync
- Batch Validation
- FIBRE
- Consensus Cleanup
- Silent payments libsecp256k1 light client
- Better communicating with the broad community
- Discussion on block 920138 and Bitcoin Core #33687
- Mempool and relay policy
- CI with CTest and CDash
26
37
183
54,895
Did you know you can submit build & test results to CDash without using CMake? 🧪🐍
With a simple Python example, learn how to:
✔️ Run tests via CTest
✔️ Integrate PyTest
✔️ Submit to CDash
👉 Full walkthrough: ow.ly/ZaO550X4up9
#CDash #CTest #PythonTesting #SoftwareTesting
2
117

26 Aug 2025
fazer randomizer de hollow knight te ensina umas coisas meio bizarras realmente.. eu ontem "ah acho que não consigo pegar o minério pra upar o ferrão que tá na coroa lá em peaks porque não tenho o cdash", passa segundos e eu lembro q existe pogo nos espinhos e eu só cago pra td
2
139

2 Aug 2025
CDASH研修後の修了試験1問ミスだけで合格して一安心☺️
制限時間ギリギリでヒヤヒヤしたけど、これで心置きなく休日楽しめる😊
写真全然アップできてないけど、今日は3回目の万博!
今日も色々まわるの楽しみ✨


3
23
486

Random Monday morning thought but I wanna make Cdash v TrajBrown.
Think it’s made for a classic. Both cold and to me both very similar. This ain’t pre meditated I just listened to both today and had a thought. I got £ for the winner if both parties are onit.
#TheInvasionShow
2
2
5
2,975
6 Jul 2025
🗺️📚 Explore 131,000 pages of Cambridge architectural history with the new Cambridge Digital Architectural Survey Project (CDASH)!
🔍 Browse 15,000 places via a map-based catalog
Start exploring: cdash.cambridgema.gov
#CambMA #HistoricPreservation
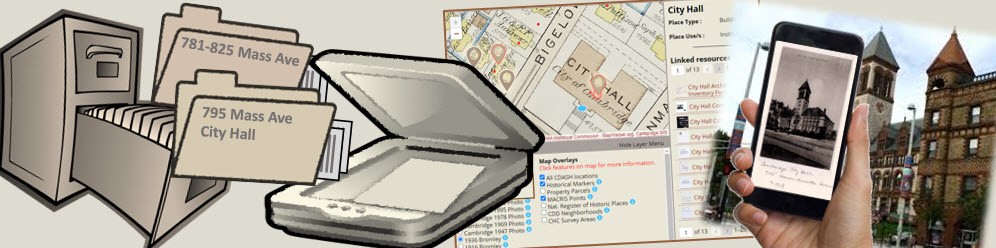
ALT Collage of images featuring a drawn mailbox with an address on Massachusetts Avenue, a Google Maps screenshot showing directions to City Hall, and a hand holding a smartphone displaying a photo of a historic building.
2
546

5 May 2025
I love how unified this public holiday cdash out it 😭 we are mad as a collective 🥺
5 May 2025

I can't believe there's no public holiday this week. This country is finished.
1
3
408

21 Apr 2025
Nightmare Knight
Pure nail
All charms at once
Shade lord
Cdash
DDark
Ashreik
Ssoul
Focus
Pogoing
Overcharming with no downside
All nail arts
Commandment of allshades
[IF they can use abilities from enemies]
NKG
Pure Vessel
Absolute radience
[All on radient]
12
535