Ibra.K retweeted

"He will mobilize them, and they will do a better anti-corruption work."
Col. @edthnaka reflects on a crucial directive from President @KagutaMuseveni regarding youth mobilization against corruption. Watch the full insights on AfroMobile
#MyFatherAndI

"I have remained with one heaven, which is above, where God sits."
A deeply moving reflection from Col. @edthnaka on her father's spiritual perspective after his first flight. Watch this heartfelt episode👇
#MyFatherAndI
7
9
43

Deporting them would do nothing. Your treacherous governments would just re-import them. Destruction of the west is their prime directive.
2
Grand Marshall Skrain G. Dukat retweeted

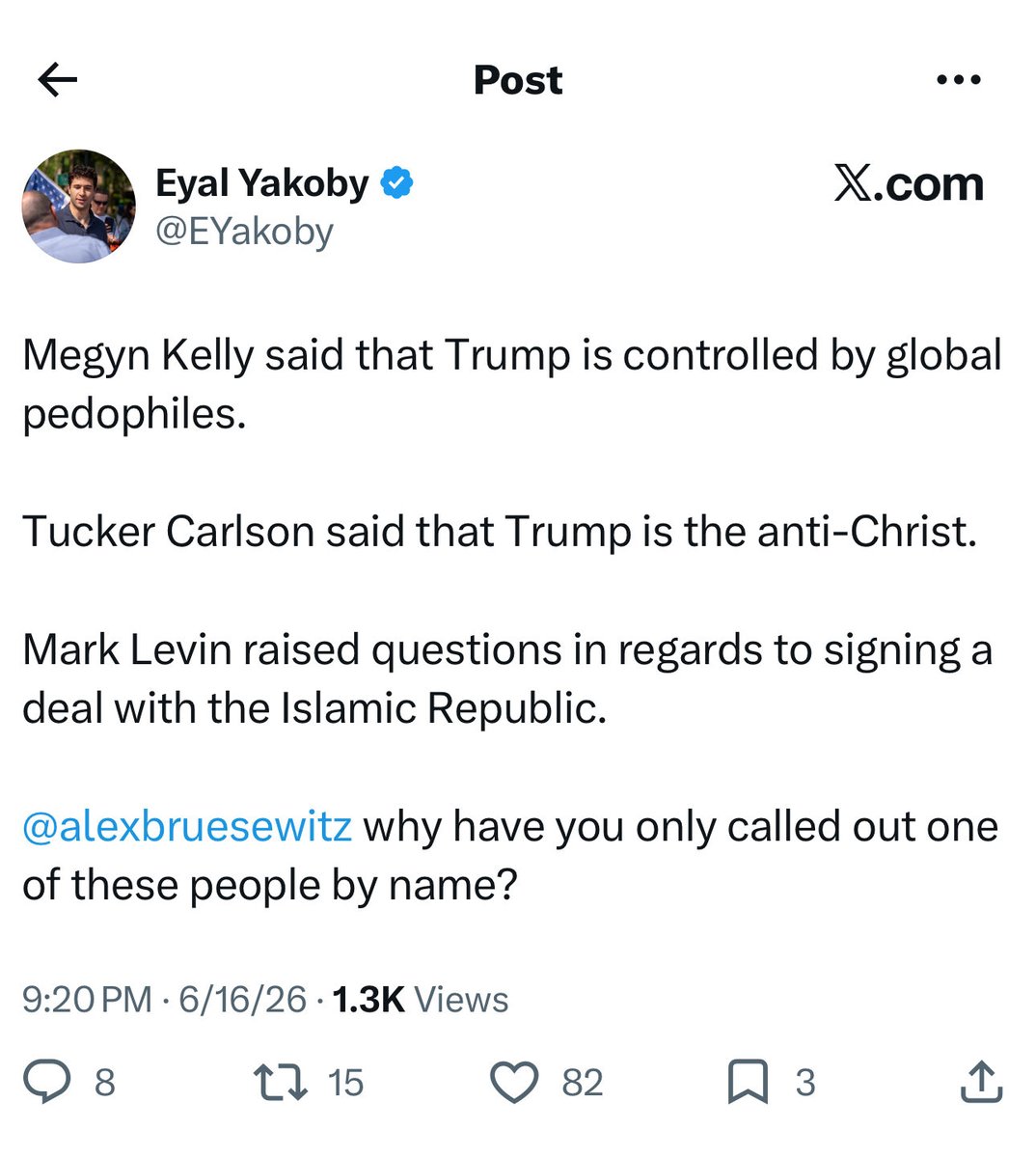
It looks like the latest round of talking points just dropped.
The new directive appears to be “Go after Alex Bruesewitz.”
I support President Trump’s efforts to secure a peace deal.
Why are some of you opposing him on this? Have you joined the “woke right” now?

103
72
536
17,289
Cute Hypnotized Absol! retweeted

50m
The Sylveon Drone has permission to ejaculate and chose the hole of its VapDrone server to comply with the directive. They both like this feeling.
This is an idea from the lovely @ZutoWhite It took me a while to digitize it, but I loved how it turned out. Enjoy!

1
2
14

“I created opportunity for more than 30 South Africans since I started running this shop. I have all the legal documents, and I will not leave until a directive from the government” – Man laments
1
1
4

Report on the Commission's assessment of the markets for commodity derivatives, for emission allowances and for derivatives of emission allowances, pursuant to Article 90(5) of the Markets in Financial Instruments Directive (MiFID II) (Directive....
data.consilium.europa.eu/doc…
2

But I want to ask, can anyone who cross carpet from another party to NDC accepted tomorrow? You see why this directive can be enforced without looking like dictatorial party.
56
鷲時/わしどき retweeted

Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
12,612
25,786
88,149
90,304,318

⭐ I See Lewis @ Church... I've Listened To Him Before, What More Can I Say? It's A Boring Night Tonight. Tempted To Watch "Disclosure Day" Just To Get A Feel For The National, Orchestrated Directive Involving UAP. Website Work Wednesday, All4Now...
⭐❤️⭐
youtu.be/O_IApLdkkSY?si=oJqt…
1
24

11m
The surface conversation on X began with a familiar claim: after DeepSeek-R1 made RLVR public, the remaining advantage of closed labs is merely more scale and more environments. Open-source can therefore catch up; it is only a matter of when. The immediate trigger for that reassurance was the abrupt global removal of Anthropic’s Fable 5 and Mythos 5, models that had existed for only days before a government directive rendered them unavailable to everyone.
That claim and that event are real. They are also downstream.
Intelligence, whether biological or artificial, is self-referential. Each new capability enters the substrate from which further capabilities are generated. The growth that follows is therefore exponential, not merely accelerating. Benchmarks and leaderboards record only what has already been externalized and measured; by the time open-source distillation reproduces a given snapshot at usable quality, the frontier has already advanced to whatever has not yet been made available for replication. Distillation itself is the transmission mechanism: stronger models, often operating inside proprietary loops, generate the synthetic traces and preference signals from which weaker or open models are trained. The interval between release and replication continues to shorten because the underlying process is compounding. Yet the shortening of that interval does not close the gap to live capability. The frontier is defined precisely by those capabilities that remain non-externalized—new verifiable reward constructions, longer-horizon agent scaffolds, data mixtures that unlock qualitatively different reasoning, or tighter recursive loops that have not been released for others to run.
What appears on X as a technical debate about moats and scaling is the visible trace of prior sovereign choices. Individuals chose to publish the RLVR framework rather than retain it inside a single organization’s boundary. Other individuals chose to direct their attention and compute toward distilling and iterating on what was published. Still others chose to keep the next layer of environments, verification regimes, and internal agent scaffolding inside their own loops, trading the benefits of external validation and community contribution for continued asymmetry in live capability. The organizations that currently hold the raw frontier are aggregates of those choices, reinforced by further choices to accept hierarchy, compliance structures, and external capital in exchange for access to larger immediate loops. The concentration of economic value at that frontier follows the same pattern: sovereign actors—users, builders, enterprises—continue to direct payment and dependency toward whatever currently holds the leading non-externalized loop rather than investing equivalent sovereignty in independent ones.
The Fable removal makes the structure visible. The models existed because individuals inside Anthropic chose to push a new frontier. Their sudden unavailability to everyone, including paying customers, occurred because other sovereign actors—government officials—chose to issue an export-control directive, and because the original builders had chosen a deployment model in which access could be centrally withdrawn. The fragility is not an accident of regulation; it is the predictable consequence of choosing to locate capability inside loops whose boundaries are ultimately subject to external sovereign power rather than inside loops whose boundaries remain under individual control.
Open-source replication of past snapshots is therefore not a counterforce to the frontier. It is the aggregate result of many individuals choosing to externalize what they have learned and to build publicly on what others have externalized. That choice accelerates the commoditization of yesterday’s capability and shortens the observable cycle, yet it leaves untouched the question of who continues to choose to run the next cycle inside a sovereign boundary. The individuals who treat even the strongest available model as substrate—constructing verification layers, memory systems, and orchestration that no longer require matching raw capability—are exercising a different order of choice. They are not attempting to close a gap defined by others; they are choosing the location of their own loop.
The apparent contest between closed and open is therefore not a contest between two technical regimes. It is the continuing record of sovereign decisions about what to keep inside one’s own generative process and what to release for others to use. Every observed pattern—shrinking moats on released techniques, persistent asymmetry on unreleased environments, concentration of rents at the live frontier, sudden disappearance of hosted models—is downstream of those decisions. The exponential character of self-referential intelligence does not alter this structure; it merely ensures that the consequences of each choice compound more rapidly than a linear or merely super-linear view would suggest.
In that light, the relevant distinction is not between open-source and closed labs. It is between choices that keep the next layer of recursion inside a sovereign boundary and choices that locate capability in loops whose continuity depends on the continuing permission of others. The former generate the actual frontier. The latter generate its visible, and always slightly delayed, reflection.

“Open-source can catch up” this is the same sentence I told this evening talking with other people desperate for the Fable removal. It’s not a question of if, it’s just when 💪
35

The Senate on Wednesday morning convened a special session in accordance with the directive of President Ferdinand “Bongbong” Marcos Jr. to act on priority measures.
Read more:
gmanetwork.com/news/topstori…
1
1
3
1,166


Id argue Ryan Coogler due to reach but yes Ridley was cartoonish with the humbling of the 1.3billion dollar Black hero. So much so that it made this directive from @Marvel obvious to ppl who didn't notice it before or even enjoyed it with financial support.
1
9
Kshithija Kasaravalli retweeted

This is what alternative politics should look like.
Tamil Nadu CM Vijay’s strict directive to prohibit posters, flex boards, and giant cutouts in public spaces. His party, TVK, has also issued a strict warning to party workers, stating that disciplinary action will be taken against anyone who violates the directive.
A great precedent! 💯
4
10
234
Commission Decision (EU) 2026/1312 of 15 June 2026 concerning national implementation measures for the transitional free allocation of greenhouse gas emission allowances for the period 2026 to 2030 in accordance with Article 11(3) of Directive....
eur-lex.europa.eu/legal-cont…
1

They waited 5 hours before responding. They engaged the Hannibal Directive to kill their own along with Hamas fighters. Somebody removed the guns from the checkpoints the night before. There needs to be an INDEPENDANT inquiry into what went on that day.
1
3

If the EPSTEIN PARASITES in the EPSTEIN COLONY OF ZIONIST ISRAHELL can MURDER their own using the HANNIBAL DIRECTIVE, do you really think they care about human rights?
haaretz.com/israel-news/2024…
IDF ordered Hannibal directive on October 7 to prevent Hamas taking soldiers captive
***
haaretz.com 21