gartzen retweeted

Decoding analog 5.8 GHz FPV with a HackRF
Sweeps all channels, locks a feed (not Wi-Fi or noise). Live spectrum and video recording.
Wild that a "lower-end" 8-bit SDR nails it. (It runs on any SoapySDR or UHD radio that reaches 5.8.)
Built on gr-ntsc-rc by Simon Bicais & Leonardo Cardoso.
1
26
219
9,424

Everyone is decoding @BeingSalmanKhan’s post differently
May 17

By I me myself, 2 ways to be by yr self, Alone and Lonely, Alone is by choice n lonely when nobody wants to be with u….. Ab iske aage you Figure out what you need to do

Dr. Khurram Abbas retweeted

انجینئر خرم دستگیر خان 16 جون 2026 کو آئی ایس ایس آئی میں منعقد ہونے والے اہم سیمینار “Decoding the Future Trajectory of Pakistan-India Relations” میں اپنے خیالات کا اظہار کریں گے۔

2
3
442

Here is an AI answer that I massaged in order to make a point about rote - the primary reason for the decline:
the "Enjoyment" Trap:
The insistence that kids need to "enjoy learning" at every step has led to curricula that prioritize engagement activities over the rigorous, repetitive practice required for mastery. While engagement is valuable, academics often mistake entertainment for learning.
Ignoring the Foundation:
By rejecting rote learning entirely, schools often skip the automaticity phase. Just as a musician cannot improvise without scales, a student cannot solve complex algebra if they are still counting on their fingers, nor can they comprehend a text if they are still laboriously decoding every word.
Evidence of Failure:
Recent analyses show that states and districts that have returned to phonics-based instruction (which relies heavily on rote decoding practice) and explicit math drills are seeing improvements, while those sticking to purely "conceptual" or "inquiry-based" methods continue to struggle
1
6
Sad Hacker retweeted

Paper alert 🚨: LLMs build a shared multilingual latent space for meaning, decoding into languages only later. 🌍 Performance gaps come from tokenizer bias & weaker late-layer circuits, not missing concepts. We show this mechanistically with Cross-Layer Transcoders. 🧵👇
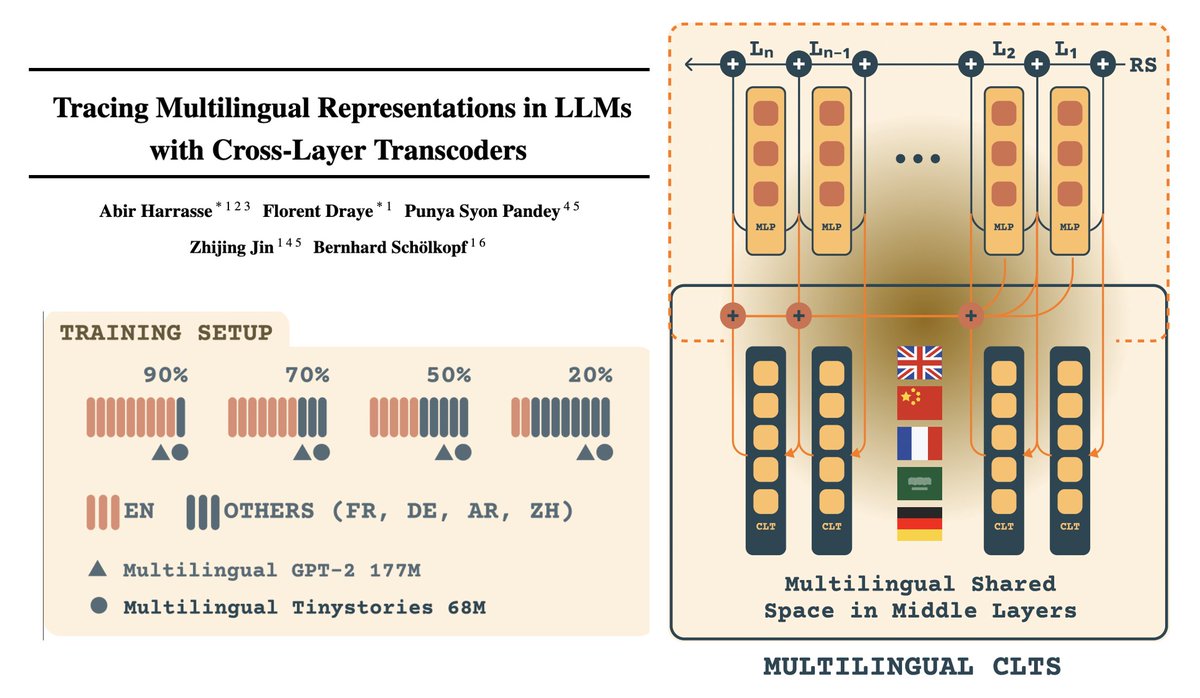
3
15
55
9,788

Tests you can watch are underrated, half the value is seeing the failure instead of decoding a diff log. For game visuals the hard part is determinism: freezing time, RNG and animation frames so the baseline doesn't flap. How are you handling that?
2
BraLoco retweeted

This one dier unless we meet @code_micky for the highway for decoding! 🌚

See What Sarkodie is Doing On Facebook 😂😂😂
“EVERLASTING” Trolling 💔💔🤣🤣🤣🤣🤣🤣
3
14
145
2,186

Palak Tiwari holds an advanced degree in decoding dating terminology, majoring in detecting red flags
indianexpress.com/article/li…
4

Our human nature is exactly what you see in the image: we seek simplicity, beauty, and peace ،not complicated things.
Wallchain shows how timing changes everything in crypto value.
In short durations, efficiency matters more and signals like CEBE become important.
@Wallchain is just one example of how new crypto projects try to frame value and rewards in a smarter way.
But honestly, getting rich in this space doesn’t always require decoding every complex metric.
Sometimes it’s just about choosing the right project early and being around the right people #wallchain


BPS measures Bitcoin per common share before senior claims. CEBE BPS measures Bitcoin per common share after senior claims. CEBE is the conservative risk metric. BPS is the common equity growth metric. BTC Yield measures BPS execution.
33

Decoding Top-Down vs Bottoms-Up Investment Strategy with Suleman Maniya and Khizar Kahloon.
Thanks for such an excellent session @sulemaniya_ and @KhizarKahloon
@KahloonPodcast
Insights on Pakistan's current economic landscape, investment strategies, and sector-specific opportunities. From bottom-up investing in small to mid-cap companies to the evolving sugar sector, get expert guidance on navigating Pakistan’s stock market and hidden gems worth exploring.
Key Topics:
1. Pakistan's real estate and equity market outlook amid geopolitical tensions
2. Bottom-up vs. top-down investment strategies explained with practical examples
3. Sector deep-dive: sugar, logistics, and agriculture potential in Pakistan
4. How small-cap companies like Meske and FMTI are turning around with new management
5. Importance of company governance, AGM participation, and financial literacy for retail investors
6. Role of foreign investors and local high net worth individuals in driving Pakistan’s stock market
7. Impact of deregulation and new listing mechanisms like SPACs on Pakistan’s capital markets
8. Risks: leverage, market volatility, and the need for patient, strategic capital
youtu.be/6rrCeuMmDao?si=AFG1…
1
1
128

33m
Nammaluku jolly ku ku rhyme aagura maari vandha orey word adi poli ah irundurukkum adhukku oru decoding

13
Suleman Maniya retweeted

Episode 89 is live.
@sulemaniya_ on Decoding Top-Down vs Bottoms-Up Investing.
How the best investors think about the market, why most retail investors get their strategy backwards, and how to find the right stocks using both approaches.
For anyone serious about how they pick their next investment.
youtube.com/watch?v=6rrCeuMm…
2
1
1
143

In the era of AI, can AI do the heavy lifting for a literature matrix? Absolutely. But our role has fundamentally shifted.
Before, it was about finding a needle in a haystack (finding the gap). Now, with AI easily decoding papers and spotting logical gaps, our actual job is finding the meaningful gap (crucial for research proposals).
1

KV cache is a nice example of how much of LLM engineering is just avoiding repeated work.
During generation, the new token needs to attend to old tokens. The old tokens have already produced their keys and values, and they are not changing. So instead of recomputing them every step, the model stores them and reuses them. That stored state is the KV cache.
This makes decoding much faster, but it moves the pressure somewhere else: memory. Longer context means a larger cache. More layers, heads, batch size, and concurrent requests mean more memory pressure.
So, I made a video explaining the KV cache in detail 👇.
1
19

حوّل أي جدار في بيتك إلى سينما منزلية 🎬🍿
إذا كنت تدور على بروجكتر يعطي شاشة ضخمة فهذا الخيار يستحق النظر:
✅ يدعم 4K decoding
✅ نظام Android مدمج
✅ Wi-Fi وبلوتوث
✅ تشغيل Netflix وYouTube والتطبيقات مباشرة
✅ مناسب للأفلام، المباريات والألعاب
✅ أكثر من 3,000 عملية بيع وتقييم 4.7⭐
بس تخيل مباراة أو فيلم على شاشة 100 بوصة وأنت مرتاح في البيت 😎
a.aliexpress.com/_c3BHfhFL
10

Before there was social media, influencers, and OTT, there was E NOW.
Now we're back—decoding the hype, uncovering what lies beyond the headlines, and bringing you the reel life in real time.
Catch E NOW with Shreya Srivastava, every Monday–Friday at 2:30 PM, only on Times Now
468

Developer Saurabh Kumar flagged Qwen 3.6's built-in multi-token prediction as a major breakthrough, noting it eliminates the need for an external draft model in speculative decoding, a simplification with significant implications for agent inference stacks.

1
1
250
Em retweeted

6 Oct 2016
Overthrowing a false prophet – Jack Conrad reviews: Chris Knight, 'Decoding #Chomsky', Yale University Press 2016 weeklyworker.co.uk/worker/11…

2
1