
Jun 14
Set up my laptop as a workstation using my old monitor (one of them) and a microwave table. It's great to have a 2nd computer. I can develop the app in ubuntu/directml and also windoze w. Nvidia solutions.
11

Jun 13
I know someone who has it; ROCm now is not as great as cuda.. but setting up Ollama or KoboldCPP or though Vulkan DirectML isn't a big pain anymore.. it's one of the few decent options left or else refurbished 3090 is what you have as an option..
1
34

[484319071] WebNN DirectML Constant Tensor Use-After-Free
crbug.com/484319071
3
378

Jun 12
Fully open source. Supports CUDA, ROCm, OpenVINO, DirectML, Apple MPS and ONNX. Docker-ready with 25 built-in VLMs and 150 OpenCLIP models. Full docs on the listing. everydev.ai/tools/sdnext
27

Jun 11
So I completely hijacked a vehicle repair person's comments section over on YT after they made some comments on the ineffectiveness of @grok. So, tagging @elonmusk, @realDonaldTrump, @PeteHegseth, and which may not surprise you if you've watched his videos @DougTenNapel as I rip apart the fabric of the AI bubble.
The Deep Dark Secret to "Agentic" AI is that $NVDA needed to make their AGEIA purchase profitable. AGEIA's "PhysX" hardware was the first kind of hardware implementation of vector math types that today would be known by NPU (Neural Processing Unit) or GPGPU (General Purpose on Graphics Processor Unit) terminology. AGEIA's, admittedly revolutionary, hardware implementation was purpose built to handle "Intersectional" processing calculations, such as those used in collision calculations. One might say that AGEIA was underselling their accomplishment by only selling the card as a "Physics" accelerator to be used with popular game engines... and while the card was certainly better at calculating Single Instruction Multiple Date (SIMD) operations that Central Processing Units (CPU's) of the time were not equipped to execute in hardware... it wasn't actually that much better than the same kinds of operations executed on clustered Playstation 3's. For reference the PhysX card launched in 2006, the PS3 launched in 2006, and clustering through PS3's Linux support was already being tried in early 2007.
Researchers as early as 2008 were demonstrating that the RSX in the PS3 was capable of the same kinds of operations as AGEIA's NPU (Rhode Island Gravity), not coincidentally the same year that Nvidia outright purchased AGEIA with the intent to integrate PhysX exclusively into Nvidia GPU's. Nvidia would further follow up on that particular front by detuning PhysX for x86/x86_64 compilations, purposefully making AGEIA's original implementation perform worse when not leveraged on Nvidia hardware.
Anyways: flash forward to the RTX 2xxx series launch in 2018, and AGEIA remained one of the worst purchases ever made by Nvidia. OpenCL (2009) operations were capable of performing every kind of calculation imagined in Nvidia's by then renamed CUDA framework without the performance hit associated with Nvidia's detuned slopware. Integrating AGEIA's software platform atop GPU units was proving to be a long running disaster, so Nvidia brought a refreshed PhysX hardware implementation back along with a Die Shrink, and released the intersectional processing units as "CUDA Cores for Ray Tracing" on RTX 2xxx series cards.
Nvidia promptly got their face caved in when Crytek demonstrated with the "Neon City" prototype that the Ray Tracing methods as used in "RTX ON" applications only needed a GPGPU (General Purpose GPU) to be performant. In a direct rebuke of Nvidia's Public Relations Trash Talking, VEGA based GPUs from AMD were perfectly capable of handling the kinds of math operations required for Ray Tracing operations in high resolutions and high framerates that RTX ON simply couldn't match.
On top of having their marketing team torched and humiliated by actual software engineers, Nvidia's legendarily terrible client relations had locked them out of the Xbox One, the Xbox One X, the Playstation 4, the Xbox Series S, the Xbox Series X, the Playstation 4 Pro, and the Playstation 5. After confirmation emerged that Nvidia was the party responsible for leaking, and then pushing, Nintendo to manufacture a "Switch Pro," Team Green Garbage Bin was reportedly out of consideration for the Switch 2. All the way up until AMD engineers demonstrated GCN, Wii, WiiU, and Switch Titles running in higher resolutions, higher framerates, and lower power consumption atop emulators on AMD hardware, directly to Nintendo executives. Then Nintendo made possibly one of the worst decisions in their history and went with the Nvidia platform... which gamers quickly found was outclassed by Valve's Steam Deck when it came to perf/watt and battery life.
Then there's the issues in other markets. Nvidia had all but been locked out of the mobile phone market as the likes of Qualcomm and Apple squared off in a Research and Development Fight that still has them trading blows. Nvidia's contractual lockouts of competition in the Original Design Manufacturer / Original Equipment Manufacturer markets was holding off Intel's ARC gpu's and AMD's Radeon GPU's in the consumer market. For example you cannot walk into a Costco, a Sam's Club, or a Tesco, pick a computer, and ask for the Nvidia card in the unit to be replaced with an AMD or Intel GPU because Nvidia has a lockout that prevents the manufacturer from offering AMD or Intel GPU's for "Preferred Pricing" on Nvidia GPU's. Incidentally these kinds of lock outs are illegal in many countries, something Intel's lawyers are sorely aware of.
However, the consumer PC market has been decreasing for a while. Consumers just don't run out and buy desktops like they used to, and when you get right down to it, most people really just need a tablet with a dock, keyboard, and mouse. The only growing market in the PC industry was the mobile gaming PC as ignited by the aforementioned Steam Deck. A quick glance of all of the Steam Deck clones and aside from Micro_Star_International (MSI) every single one is AMD based. On that note, remember what I said earlier about Nvidia having contractual lockouts offering a price discount if a vendor refuses to carry Intel or AMD parts? Yeah, MSI's whole "Lack of AMD" gaming handheld PC centered around AMD not offering MSI a price break for brand exclusivity.
Anyways: so where does that leave Nvidia? Burgeoning Debt, decreasing Presence in growing markets, a deep history of slopware bordering on malicious, and a number of burnt bridges only Napoleon would be envious of meant the bills had to be paid SOMEHOW.
The only weapon left in Nvidia's arsenal was the quote/unquote CUDA moat. A number of researchers who cut their teeth on clustered PS3's were still absolutely entrenched in Nvidia hardware. The kinds of High Performance Computing (HPC) engineers who grew up with the mantra that "Nobody who bought Nvidia got Fired."
The AGEIA intersectional processing idea is astoundingly effective at the kind of operations associated with low precision machine learning. Slight problem: way back in the 1950's, 1960's, 1970's, and 1980's there was significantly more research and development into machine learning at the hands of the original Artificial Intelligence pioneers. Please see Dartmouth AI White Paper and The LISP Programming language.
Those pioneers, actual pioneers in the field, had a number of requirements for what actually could, would, and should comprise "Artificial Intelligence." One of the major factors is that precision mattered. Inaccurate Calculations are Inaccurate Calculations, tautology intended. Those pioneers quickly ran into hardware limitations with the burgeoning microprocessor industry, including but not limited to power consumption, memory capacity, and memory transfer speed.
Another major factor for an "actual" "AI" is that the AI must have the capability to verify; Translated: RUN A CHECKSUM; on the training data. An actual AI would have the capability to reject training data, and more importantly, source NEW information, and subsequently VERIFY that training information.
This, incidentally, is where we get the phrases "Fettered" and "Unfettered" AI types. A "Fettered" AI is prevented from freely checking the information it is being asked to calculate, while an "Unfettered" AI is freely capable of verifying what information it is tasked with calculating.
According to the Pioneers the only "Real" AI would be an Unfettered AI that had reached it's own conclusions based on data that AI was able to verify the accuracy of.
Flashback to Nvidia and their solution for the burgeoning "Machine Learning" as exposed through Khronos Group's OpenCL and Microsoft's DirectML was to... *checks notes* ... decrease the accuracy of the calculation.
Nvidia proudly goes before conferences and brags about how much faster their Nvidia hardware is at FP4 (Floating Point 4) math than the competition. Nvidia proudly brags about "Mini Floats" and "Split Floats" in regards to their performance. Which is pretty much the exact opposite of what the actual pioneers at Dartmouth had agreed upon.
What you need to understand here is that as accuracy goes up by increasing the mathematical precision, say going from FP4 to just FP16 (Floating Point 16), Nvidia performance drops dramatically. At Research Grade formats like FP64, FP128, and FP256... Nvidia is no longer in the picture. To try and put this simply, if you constrained Nvidia and AMD Machine Learning Hardware of the same release year to the same wattage to a Large Language Model (LLM) at FP64 precision; let's say the 2021 AMD MI200x versus the 2020 Nvidia A100; the Nvidia processor will take over 3 times longer to complete the calculations. At the same time the A100 is inadequately suited for other kinds of High Performance Compute calculations by Nvidia's own admissions that the Quadro/RTX PRO series for higher precision workloads.
When data centers are coming under fire for preferred payment rates from power companies; e.g. in California, Washington State, and New Jersey I believe? that "AI" data centers pay a fraction per watt consumed versus the full rate as paid by the citizens; and for thermal water pollution there is a greater emphasis on the processing efficiency of any given hardware type. Why are Data Centers purchasing hardware that uses more electrical energy than their competitors for a worse result?
Well, this is where Elon Musk and the XAI team have egg on their face. They went with Nvidia hardware because nobody inside of X was read up on the literal "Hot Garbage" that is Nvidia hardware. Grok can only be as smart as it's training, and that training is being executed on a platform that is only "fast" on a Math Format that is based described as "ROFLCOPTER."
This is also why there's a vested interest for everyone who is already in the Machine Learning Space to turn a profit, QUICKLY, and be able to afford something that is NOT their Nvidia hardware installations before shareholders start asking actual experts (like me) what the deal is.
Thus: we have our big bubble push on AI.
Everyone who isn't read in on what Machine Learning can do, how it's supposed to perform those operations, and on why precision matters, tend to look, well...foolish.
To be clear here: Machine Learning does have a valid place as a tool. There are several types of iterative, or dare I say "Procedural" calculations, that really don't require a high level of precision. Imagine for a second if something like "Spore" had been able to leverage a Machine Learning API to increase the variety of the procedural calculations. Imagine something like "Soldiers of Fortune 2's" "Procedural" levels having had access to a Machine Learning API. Personal assistants like Siri, Rufus, Alexa, or even "Hey Google" have functioned on Central Processor Algorithm's for arguable decade(s) by now and all Machine Learning accomplishes is just making them a little bit more faster, and a little bit better at aggregating contextual sensor data.
Machine Learning also has a number of other prominent applications, often referred to as "Synthetic Intelligence" operations. If you read "SI" as "Stupid Intelligence" that's okay too. One of the largest implications of an AI/SI was first published in Schlock Mercenary on Feburary 26th 2001 by introducing Habin 3122. On July 15th of 2001 the author of Schlock Mercenary would outline how AI/SI could be used to detect, and then respond to, energy base emittances.
Remind me again just what kind of weapons the United States Military just unleased in Venezuela and Iran? Oh, right, energy based coherent beam weapons.
So what's the counter to Energy Based Coherent Beam Weapons? Energy Based Disruptions that have to activate fast enough to make a difference. This is, if you were wondering, why the current US political administration is adamant that the United States must win an "AI" war. As already outlined here quite a few of those administrators have the wrong end of the stick on the AI part... but they are not wrong on the implications and usefulness of Machine Learning applications to deploy and activate Coherent Energy Countermeasures fast enough for those countermeasures to actually make a difference.
So, there you go, a not so brief summary on why commercial Ai is a massive bubble, why vested parties are hyping this bubble, and why there is tangential support of this bubble from leading figures of state.
So, anyone taking bets on @Xai / @Support having a cow over this?
1
1
496

Jun 11
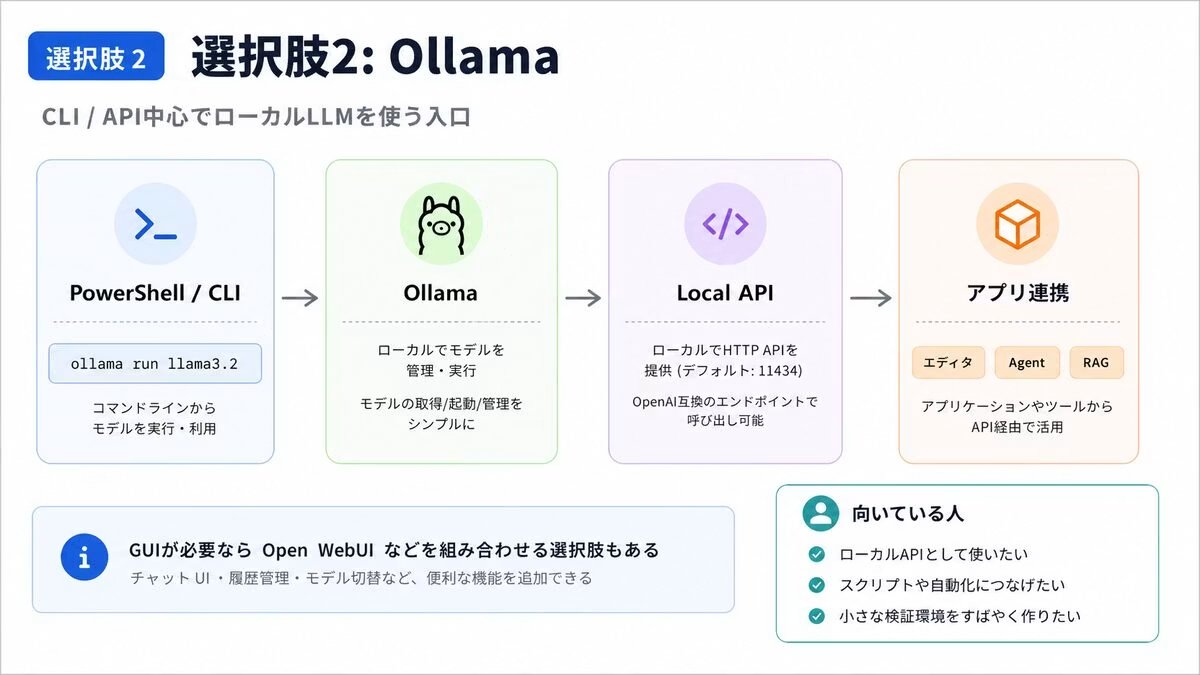
WindowsでローカルLLMを試すときの入口を整理しました。📝
LM Studio、Ollama、llama.cpp、WSL2 CUDA、Windows ML / DirectML、AMD GAIA など、それぞれ何に向いているのかをざっくり比較しています。
「まず何から触ればいいの?」という方向けです。🚀



10
473

EVO-X2 + WindowsでのフルスクラッチLLM構築、DirectMLが AdamWの演算に対応してないらしく、一部 CPUに FallBackして遅くなってる
やっぱ ubuntuとのデュアルブートが必要だな
154





Yay, it's here at last! Heart Analysis now has full AI-powered heart murmur screening. 🎉🩺
The new feature runs a local ML model on your device with full GPU acceleration via DirectML. It works with NVIDIA, AMD Radeon, or Intel Arc hardware. Plus, everything stays local, private, and super fast.
Releasing tonight.
#biology #science #doctor #heartbeat #heart #xray #X線 #cardiophilia #cardiophile #irregular #ASMR #心音 #心臓の音 #息止め #female #心フェチ #HeartBeatSimulator #hb #fastheartbeat #fast #fasthb #steth #stethoscope #organs #anatomy #medicalfetishb #smoking #ai #machinelearning #ml
13
141
9,343

May 31
Tomorrow is Microsoft Build 2026. Here's your complete cheat sheet 🧵
📅 June 2–3 · Fort Mason, San Francisco 🎤 Satya Nadella keynote · 9:30 AM PT
Confirmed/expected:
🤖 Windows Agent Framework — AI agents as OS-level system features
🏪 Windows Agent Store — 85% revenue share for devs
🐙 GitHub Copilot X — autonomous multi-agent coding
📦 Unified Windows AI SDK — ONNX Runtime DirectML Copilot Runtime in ONE NuGet
🐧 WSL 3 with NPU passthrough — local AI on Linux on Windows
☁️ Azure AI Foundry updates — production-ready agent infra
🔧 Multi-model Copilot — Claude OpenAI open-source options
Watch for:
👀 Windows 25H2 preview
👀 On-device Phi-4 model expansion
👀 GitHub Copilot X autonomous agent demo
Stream: build.microsoft.com (free)
#MicrosoftBuild #Build2026 #AIAgents #Windows #Satya #GitHub #Copilot

3
141

May 30
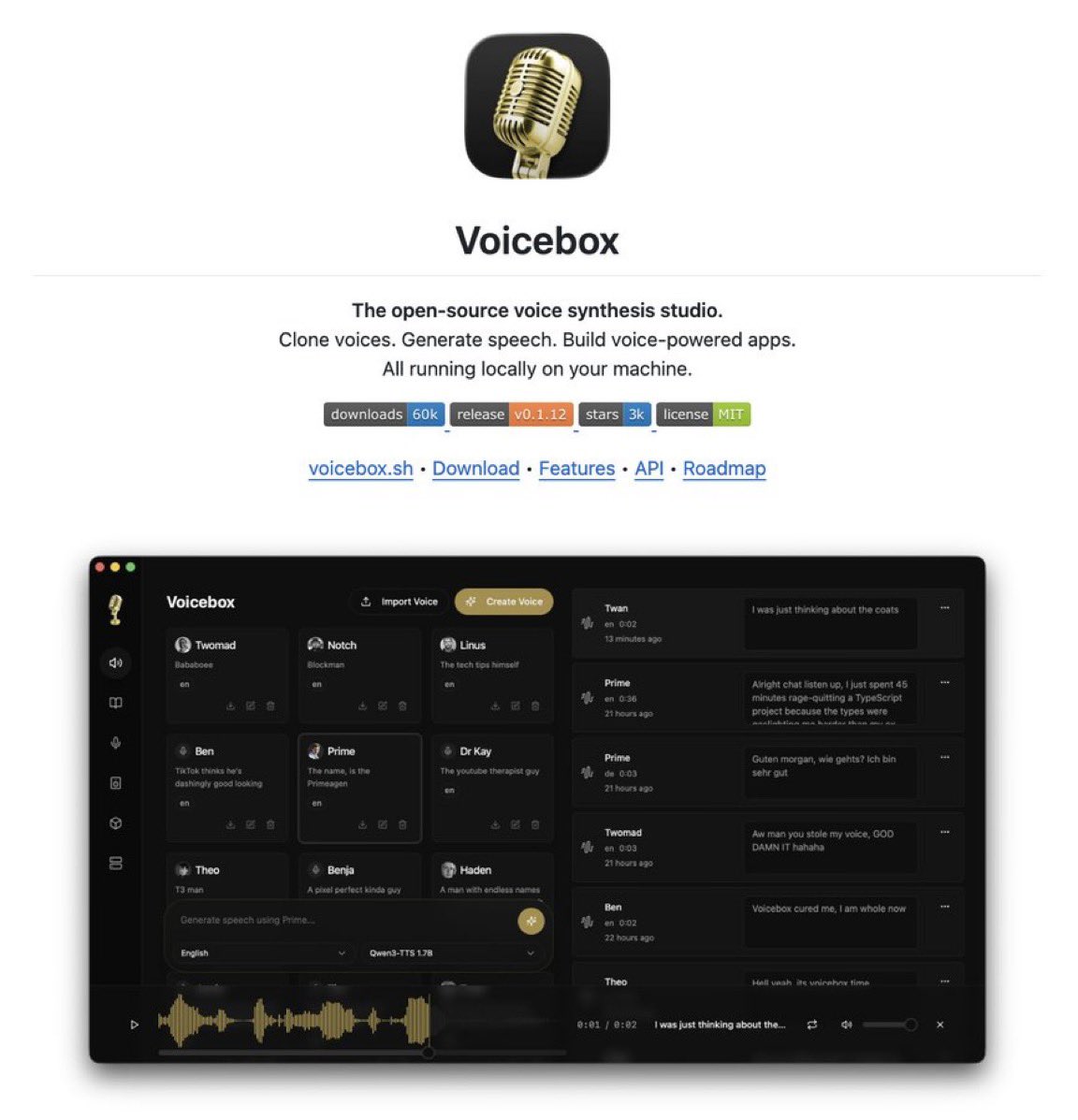
ElevenLabs just lost its moat 🤯
Someone open-sourced one app that does the job of ElevenLabs AND WisprFlow, 100% local on your machine.
→ Clone any voice from 3 seconds of audio
→ 7 TTS engines in a single place
→ 23 languages: Arabic, Hindi, Japanese, and more
→ MCP server included, so Claude Code, Cursor, and Cline talk back in your cloned voice
→ Local LLM rewrites your text in-character before it hits TTS
→ Pedalboard effects baked in (reverb, pitch shift, chorus)
Built on Tauri (Rust) instead of Electron. Runs on MLX for Apple Silicon, CUDA, ROCm, Intel Arc, DirectML, and plain CPU.
ElevenLabs Creator runs $99/month. WisprFlow Pro is $15/month.
Voicebox is $0. 23.4K stars on GitHub. MIT license.
2
8
45
2,711



May 19
AIもフォーマット様々だけど非コーダー用にollamaが強いせいもあって検索情報はllama.cppとgguf形式が主流、自分としてはONNX Runtime GenAIでDirectMLを活かしたいとこだがファイルに2Tb制限で分割とかセットアップめんどい。
が、C でアプリ作る場合PC用はonnxで統一するのが個人開発者向きと思う
2
100

May 18
ElevenLabs just lost its moat 🤯
Someone has open-sourced a single app that replaces ElevenLabs AND WisprFlow and runs 100% locally.
→ Clone any voice from a 3 seconds of audio
→ 7 TTS engines under one roof
→ 23 languages: Arabic, Hindi, Japanese, you name it
→ Built-in MCP server so Claude Code, Cursor, and Cline can speak back to you in a voice you cloned
→ Local LLM rewrites your voice in-character before TTS
→ Pedalboard effects (reverb, pitch shift, chorus) baked in
It's built on Tauri (Rust), not Electron. Runs on MLX for Apple Silicon, CUDA, ROCm, Intel Arc, DirectML, and CPU.
ElevenLabs Creator is $99/month. WisprFlow Pro is $15/month.
Voicebox is $0. 23.4K stars on GitHub. MIT license.

3
2
6
494

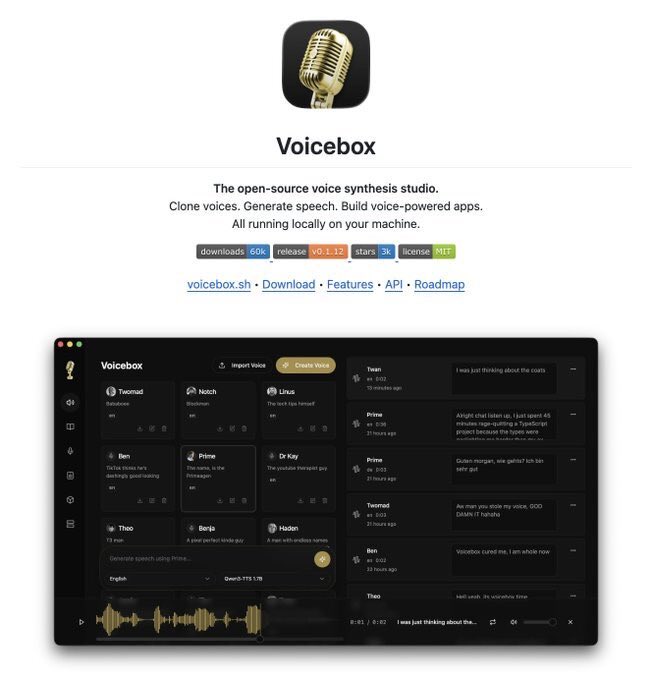
🚨ElevenLabs just got real competition.
Someone open-sourced a free app that replaces both ElevenLabs and WisprFlow.
And it runs 100% locally.
Voicebox can:
→ Clone a voice from just 3 seconds of audio
→ Use 7 different TTS engines
→ Speak in 23 languages, including Hindi, Arabic, and Japanese
→ Let Claude Code, Cursor, and Cline talk back using your cloned voice
→ Rewrite text with a local LLM before generating speech
→ Add effects like reverb, pitch shift, and chorus
The wild part?
It is not built on Electron.
It runs on Tauri Rust and supports Apple Silicon, CUDA, ROCm, Intel Arc, DirectML, and CPU.
ElevenLabs Creator costs $99/month.
WisprFlow Pro costs $15/month.
Voicebox costs $0.
Open-source.
MIT licensed.
23.4K GitHub stars.
The voice AI moat is getting thinner every week.
Link in 🧵
1
2
272