





Apr 28
it's famous drawing from Esscher. If you blow it up big you' ll notice things are not as they seem.
1
18


31 Dec 2025
But wait, is there cool theory too?
Oh boy yes!🤤
We've got:
🔹Connections to SOC
🔹Esscher transform interpretation
🔹Higher-order cumulants
🔹Optimal control variates
🔹Connections to Weighted Flow Matching
🔹Extensions to Flow Maps
📄: arxiv.org/abs/2512.21829
(5/5)
1
1
7
1,501

30 Dec 2025
A key tool used on the way is the Esscher Transform (TIL!), apparently used for pricing options. soa.org/globalassets/assets/…
4
892

2 Dec 2025
Als er diverse malen gerefereerd wordt aan jouw post over Esscher en Coronagelden en hier onjuistheden worden beweerd, dan kan je 2 dingen doen. Je mond houden voor de goede vrede of uitleggen. Al 12 jaar doe ik het laatste. Dus lijstschouten.nl/2025/12/eve… #Baarn (ook op Facebook)

1
1
2
179


23 Oct 2025
for Levy processes, I've actually derived the generalization of risk neutral transforms (ie Esscher etc) as the generalized inverse of prospect theoretic probability weighting functions
27 Sep 2022

ok. this references the big daddy of all elementary confusions in derivatives.
Black-Scholes (and related) models, for which Nobel prizes were won: we do NOT use them as models, we use them as normalizations only, as a convenient change of variables.
1
3
999

22 Jun 2025
22/06/2025 – NL – Skyscapes 1
15:30 h
Reminded me of 'Peel', by M.C. Esscher
(incredible artist!)
@Demo2020cracy @Elizabe32413720 @Raggedyedge1 @DELTA9_DELTA9 @BenKnight1980 @druid10 @IonisedSkyWatch @Reptoid_Hunter @Clearskiesinit @SaskiaHeijden @ImagesCoast @OpChemtrails



1
4
13
330

27 May 2025
De Hamas propaganda is meestal snel te ontmaskeren, zeker als ze AI inzetten.
We zien weliswaar geen 6 vingers aan een hand maar onze eigen Esscher zou hier met interesse naar kijken!
Zoek de fouten!
.
Let op de bedranden.
Alle kinderen die even oud lijken te zijn?

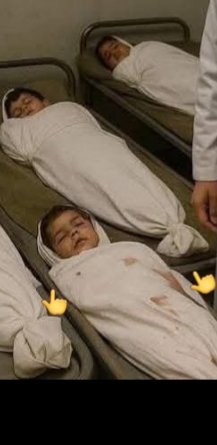

2
69

13 Apr 2025
Dit is ongetwijfeld geïnspireerd door Esscher, hoewel van mindere kwaliteit. Desalniettemin kan ik dit wel waarderen.

8
122

Oktober 2023. Onze dochter Li Ling in het Esscher museum.

4
96

23 Dec 2024
Support artists!
I actually make NFT stuff too.
Check my Photography / digital / AI / #esscher #art #NFT
exchange.art/angrybunny/nfts
2
56



30 Oct 2024
Applications of the Second-Order Esscher Pricing in Risk Management. arxiv.org/abs/2410.21649
3
215

1 Aug 2024
Esscher (1932)
Cramér (1938)
Chernoff (1952) cited Rubin
Hoeffding (1963)
Pick your fighter.
1
441

31 Jul 2024
Sergey Bobkov, Friedrich G\"otze: Esscher Transform and the Central Limit Theorem arxiv.org/abs/2407.20726 arxiv.org/pdf/2407.20726
2
104

8 Jul 2024
Mooie necrologie over Wim Hazeu (1940-2024). Wat een ongelooflijk harde werker was hij toch: als biograaf van o.m. Achterberg, Slauerhoff, Vestdijk, Marja, Esscher, Toonder en Lucebert. En dan ook nog al die literaire documentaires op radio en televisie: volkskrant.nl/boeken/wim-haz…
7
13
74
3,204