
It initially seemed to me like it was just too much upward pressure on the extractor since the factory 20s are just 18s with a slightly longer basepad and the springs were super tight, but even downloading to 18 in both new and old mags didn't make a difference at a point.
1
6

God knows how they disembowelled the building to install ovens, grills and extractor fans,
1
25

yes by all means stupid people. Drop a bullet in your chamber...and pray your extractor works.
1


Idk if you noticed but a couple days ago when I was on, I noticed my daily’s not giving me the portable extractor no matter how many I did, just wanted to make you guys aware of this
1
1
240

As soon as you picked it up and swap it. You should have swap your pickaxe to your portable extractor. It would've extracted it and counted
1
1
562

U launched a ticker and suddenly went ill, hahahaha, u aren't convincing little kids here broski. We know ur type in the space😎
(Hit and Run)
U tried to extract but @Pumpfun @a1lon9 @metaversejoji saved this lovely meta $WORLDCUP & the CT again from such an extractor like u😂
1
2
127


#Fortnite Ch7, S3: Mastery Monday #2 is now live!
Legendary and Mythic Sprites appear more often
- Water Sprite decreased by 30%
- Earth Sprite decreased by 30%
- Fire Sprite decreased by 30%
- Duck Sprite increased by 46%
- Ghost Sprite increased by 46%
- Demon Sprite increased by 46%
- King Sprite increased by 46%
- Dream Sprite increased by 71%
- Punk Sprite increased by 71%
- Zero Point Sprite decreased by 99%
- Burnt Peanut increased by 100%
^ Variants are then an additional % chance of this base spawn.
Level up Sprites twice as fast
Sprite XP earned increased:
Elims by 166%:
- 150
➥ 400
Assists by 100%:
- 75
➥ 150
Extract by 100%:
- 100
➥ 200
Opening Containers by 100%:
- 75
➥ 150
Players Downed by 50%:
- 100
➥ 150
Dupe Extract by 100%:
- 200
➥ 400
Earn 2x Sprite Dust from extractions
Extraction by 100%:
- 1x
➥ 2x
Extraction Gummy Variant by 100%:
- 1.1x
➥ 2.2x
Win by 100%:
- 1x
➥ 2x
Extraction Holofoil Variant by 100%:
- 2x
➥ 4x
Portable Extractor Daily Challenge bonus

22
25
279
15,966

MASTERY MONDAY EVENT IS NOW LIVE
• 2x Sprite XP
• 2x Sprite Dust
• Mythic Legendary Sprite Rate up
• Portable Extractor Daily Challenge
• & more..
Trade Sprites with others here: Discord.gg/BiGameHub

5
8
142
7,463

Explain the butt dials alone?! JM repeatedly calling and hanging up over and over, butt dials.. people are in jail from their phone data alone, yet that same data extractor that found the 223am hos long to die now is a clitch?! Life 360 app that’s not accurate anymore?! FUCKERY!
1
9

LUXURY 5BEDROOM FULLY DETACHED DUPLEX FOR SALE
Amenities:
- [ ] Fitted Kitchen
- [ ] Modern Day POP Ceiling
- [ ] Detailed finishing
- [ ] Wardrobes
- [ ] Heat extractor
- [ ] BQ
- [ ] Swimming Pool
📌PRICE : 450M ASKING
📍: CHEVRON TOLL GATE LEKKI LAGOS 🇳🇬




2

- Detailed finishing
- Wardrobes
- Water heater
- Heat extractor
- Ample parking space
- Secured Estate
- Bq
1

NEWLY BUILT 2 BEDROOM APARTMENT WITH POOL
LOCATION: Lekki Phase 1, Lagos
FACILITIES
- En-suite rooms
- Fully Fitted Kitchen
- Water heater
- Heat Extractor
TITLE: CofO
PRICE: 260m
Leery Obi kekerenke Shank Tiwa Happ New week here we go Mourinho Marc Amorim AC millan code




1
4
4
126


MIT CSAIL showed that long-context reasoning may be better treated as an inference-time operating-system problem than a bigger-window problem. Instead of forcing the model to remember everything, RLMs let the model inspect external context with code, recursively delegate subproblems, and pull only the relevant working set into active attention.
That is both more accurate and more impressive.
The paper is real: Recursive Language Models, by Alex L. Zhang, Tim Kraska, and Omar Khattab of MIT CSAIL, was submitted to arXiv on December 31, 2025 and last revised on May 11, 2026. The paper describes RLMs as an inference paradigm that treats long prompts as part of an external environment, letting the model programmatically examine, decompose, and recursively call itself over snippets of the prompt.
The biggest fix: stop saying “they solved AI memory”
That line is viral, but it is technically weak.
RLMs do not solve memory in the persistent, human-like, lifelong-agent sense. They solve a narrower but extremely important problem: how to reason over inputs that are too large or too damaging to stuff into a single model context window.
Better phrasing:
MIT CSAIL did not solve memory by making the model remember more. They changed the interface. The document stops being “memory” and becomes an external environment the model can inspect.
Even better:
RLMs turn long context from a passive attention problem into an active navigation problem.
That is the thesis.
Stronger core version
MIT CSAIL may have just reframed the context-window war.For years, AI labs have chased larger context windows: 32K, 200K, 1M, 2M tokens. The assumption was simple: if the model can hold more text, it can reason over more reality.But long context has a hidden failure mode: context rot. As prompts grow, models often become less reliable at using the information already inside them. They may have the tokens, but they do not have stable access to the right facts at the right time.Recursive Language Models attack the problem differently. Instead of pushing an entire document into the model’s context window, they store the input outside the model — for example, as a variable in a Python REPL. The root model receives the question and a way to inspect that external context. It can search, slice, grep, transform, and delegate smaller sections to sub-model calls before synthesizing the answer.The result is not “infinite memory.” It is something more practical: an AI that knows how to look.
That version keeps the drama but removes the brittle claims.
Most important accuracy corrections
1. The idea did not suddenly appear only on December 31
The arXiv paper was submitted on December 31, 2025, but the authors’ project page says the original RLM idea and experiments were proposed earlier in a 2025 blog post, with the expanded results later in the arXiv preprint. The GitHub README says the same: initial experiments came from a 2025 blogpost, with expanded results in the arXiv preprint.
Better line:
The full arXiv paper landed on December 31, 2025, after an earlier 2025 research blog post had already sketched the paradigm.
2. “No API costs” is wrong
The code is open source, but RLMs still call underlying models. The paper’s evaluations use GPT-5 and Qwen3-Coder as base models, and the GitHub examples show RLMs wrapping standard API-based or local LLMs. So the framework may reduce or redirect token costs, but it does not magically remove model costs.
Replace:
No API costs.
With:
The framework is open source, but production use still pays for whatever root and sub-model calls it makes.
3. “Drop it in and your app does not notice” needs caveats
The repo does say RLMs can replace a normal llm.completion(prompt, model) call with rlm.completion(prompt, model), but production use is not trivial because the default local REPL uses Python exec on the host process. The README explicitly warns that non-isolated environments can be problematic when prompts or tools interact with malicious users, and lists isolated environments such as Docker, Modal, Prime, Daytona, and E2B.
Better line:
At the API boundary, RLMs can look like a drop-in replacement. In production, the hard part is sandboxing, logging, latency control, cost caps, and preventing the model from executing unsafe code.
4. “No information loss” is too absolute
RLM avoids forced summarization loss because the original input remains externally accessible. But the model can still fail to search the right thing, choose the wrong decomposition, over-delegate, under-delegate, or synthesize incorrectly. The paper’s own limitations section says the optimal implementation remains underexplored, the experiments used synchronous sub-calls and recursion depth one, and current models are inefficient decision-makers over their context.
Better line:
The source text stays intact. The failure mode shifts from “the model forgot” to “the model searched, decomposed, or synthesized badly.”
That is a much more sophisticated insight.
The strongest single thesis
The context-window war was trying to make models remember more. RLMs ask a better question: what if the model should not remember the library — what if it should know how to use one?
That sentence should be the heart of the piece.
Better headline options
Most viral:
MIT Did Not Make AI Remember More. It Taught AI Where to Look.
Most technical:
Recursive Language Models Turn Long Context Into an External Environment
Most founder-facing:
The Next AI Memory Layer May Not Be a Bigger Context Window
Most contrarian:
Bigger Context Windows Were Only Half the Answer
Most cinematic:
The End of Shoving the Library Into the Brain
Most accurate and punchy:
RLMs Reframe AI Memory as Navigation, Not Storage
Better opening hooks
Hook 1
MIT CSAIL did not solve long-context AI by building a bigger window.
They opened a door.
Hook 2
The breakthrough is almost insulting in its simplicity: stop making the model read the whole archive. Give it tools to search the archive.
Hook 3
The last five years of AI memory research asked, “How much text can we fit inside the model?” RLMs ask, “Why is the text inside the model at all?”
Hook 4
Human experts do not answer questions by holding an entire library in working memory. They search, inspect, compare, delegate, and synthesize. RLMs bring that pattern to LLM inference.
Best rewritten version
MIT CSAIL just made the context-window war look less inevitable.The new paper is called Recursive Language Models. The idea is brutally simple: stop forcing a model to hold the whole document in its context window.Store the long input outside the model — for example, as a variable in a Python REPL. Give the model a question, tell it the external context exists, and let it inspect the data programmatically.It can search with regex. Slice sections. Count structure. Grep for clues. Transform the text. Pull in only the pieces it needs. And when a section is too large or too semantically dense, it can call smaller sub-models on those snippets and synthesize their results.That changes the problem from memory to navigation.A normal long-context model tries to answer while drowning in everything.
A RLM behaves more like an expert with a library, a terminal, and a team of assistants.The paper reports that RLMs handled inputs up to two orders of magnitude beyond model context windows and outperformed base LLMs and common long-context scaffolds across several long-context tasks, while keeping costs comparable or cheaper in many cases.The important lesson is not “context windows are dead.” Bigger windows still matter. The lesson is sharper:The future of AI memory is not just larger attention. It is active context management.
Genius-level positioning upgrade
The current draft frames this as a “bigger brain vs smaller brain” story. That is good, but the deeper frame is:
RLMs are out-of-core algorithms for language models.
The paper itself draws inspiration from out-of-core algorithms: systems with small, fast memory can process much larger datasets by intelligently fetching what they need. That analogy is excellent and should be brought to the surface.
Use this:
Databases solved this problem decades ago. You do not load the entire warehouse into RAM. You keep the data outside, index it, query it, page in the relevant pieces, and compute over the working set.RLMs apply that same idea to language models.
That is the killer technical analogy.
The best metaphor
Do not say:
They gave AI infinite memory.
Say:
They gave AI a file system.
Or:
They stopped treating context like RAM and started treating it like disk.
Or:
They turned the model from a reader into a researcher.
Best final metaphor:
A long-context model is a person trying to memorize a library.
A RLM is a person who knows how to use the library catalogue.
Missing concept: “context as environment”
This phrase should appear early. It is the actual conceptual breakthrough.
The paper’s core move is that the long prompt is not fed directly into the Transformer. It becomes part of the environment, represented as a variable inside a REPL that the model can inspect and manipulate.
Add:
The key move is ontological: the prompt stops being text inside the model and becomes an object outside the model.
That is a deep and memorable line.
Missing concept: “attention is expensive; navigation is cheap”
This is one of the best hidden ideas.
A model attending over millions of tokens is expensive and unreliable. But searching a string with code is cheap, exact, and deterministic. RLMs exploit that asymmetry:
Let code do what code is good at: search, filter, count, slice, transform.
Let the model do what models are good at: semantic judgment, decomposition, synthesis, ambiguity handling.
This should be framed as cognitive specialization.
Missing concept: “the model’s context becomes a control plane”
In normal prompting, the context is both data and instructions. In RLMs, the root model’s context becomes more like a control plane:
Data plane: external prompt / documents / codebase
Control plane: root model deciding what to inspect
Worker plane: sub-model calls over bounded snippets
Execution plane: Python REPL / tools / deterministic code
Synthesis plane: final answer
That is a powerful systems framing.
Suggested line:
RLMs separate the control plane from the data plane. The root model does not need to carry the whole archive. It needs to orchestrate access to it.
Missing concept: “RAG was retrieval before understanding; RLM is retrieval during reasoning”
This is the best RAG comparison.
The current draft says RAG is a compromise. True, but make the contrast cleaner:
Classic RAG:
A retriever chooses chunks before the model fully reasons about the problem.
RLM:
The model can iteratively decide what to inspect as its understanding evolves.
Use this:
RAG retrieves before reasoning. RLM retrieves as part of reasoning.
That is concise and brilliant.
Add nuance:
RLM does not make RAG obsolete. It absorbs retrieval into an agentic loop where search, inspection, decomposition, and verification can happen repeatedly.
Missing concept: “failure mode migration”
This is a key advanced insight.
RLMs do not remove failure. They move it.
Old failure modes:
Context rot
Lost-in-the-middle
Truncation
Bad chunking
Lossy summarization
Retriever misses
Huge token bills
New failure modes:
Bad search strategy
Unsafe code execution
Tool abuse
Recursive overthinking
Latency spikes
Cost variance
Incorrect decomposition
Bad synthesis from good sub-results
Sandbox escape risk
Prompt injection through external documents
Insufficient observability into sub-call trajectories
This makes the piece much more credible.
Add a “what actually happened in the benchmark” section
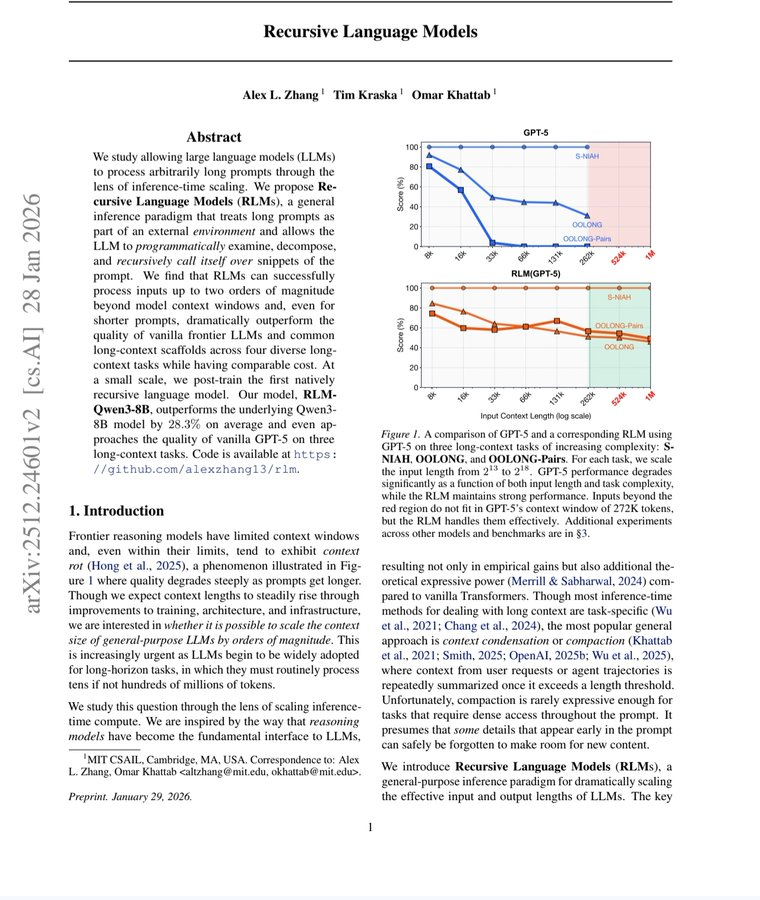
The paper evaluated RLMs across tasks including CodeQA, BrowseComp-Plus, OOLONG, and OOLONG-Pairs, with input lengths ranging from tens of thousands of tokens to 6M–11M tokens in the BrowseComp-Plus setup. The reported table shows GPT-5 RLM outperforming GPT-5 base calls and other scaffolds on several tasks, including 91.33 on BrowseComp-Plus versus 0.00 for the base model where the base model hit input limits, and 58.00 F1 on OOLONG-Pairs versus 0.04 for base GPT-5.
But the draft’s line about “GPT-5 on a benchmark requiring complex code history beyond 75,000 tokens could not solve even 10%” is not safely supported by the table as written. The CodeQA row in the paper reports GPT-5 base at 24.00 with an input-limit marker, not below 10%. The “near-zero” collapse is more accurate for BrowseComp-Plus under input limits and OOLONG-Pairs F1.
Better wording:
On some of the hardest long-context setups, base frontier models either hit input limits or collapsed to near-zero performance, while RLM versions remained useful. The most dramatic example is OOLONG-Pairs, where GPT-5 base scored near zero while the RLM version reached 58.00 F1.
Add the caveat that small contexts may not need RLM
The paper explicitly notes that the base LM can outperform RLMs in the small-input regime, suggesting there is a tradeoff point for when to use an RLM rather than a direct model call.
This is crucial.
Suggested line:
RLM is not automatically better for every prompt. For short, simple inputs, the overhead can hurt. The win appears when the task is long, information-dense, or decomposition-heavy.
That line makes you sound like you actually understood the work.
Add Prime Intellect accurately
Prime Intellect really did publish a post calling RLM a major research focus and arguing that teaching models to manage context end-to-end through reinforcement learning could enable long-horizon agents working over weeks or months. They also describe using Python, sub-LLMs, and sandboxed execution to let models manage context without stuffing all data into the main context window.
Better line:
Prime Intellect called RLM a major research focus and is betting that RL-trained context management is the next step: models that learn when to search, when to delegate, when to compress, when to branch, and when to stop.
Add recent follow-on work
Since the original paper, follow-on work has already started probing the weak points.
One March 2026 reproduction found that depth-1 RLMs can boost accuracy on complex reasoning tasks, but deeper recursion can cause models to “overthink,” degrading performance and inflating execution time and token costs.
Another March 2026 paper argued that RLM success depends heavily on how context-interaction programs are selected, and introduced self-reflective program search to improve over RLM under the same time budget.
A separate March 2026 λ-RLM paper criticized open-ended REPL control as hard to verify and proposed a typed functional runtime with pre-verified combinators, reporting better reliability and latency than standard RLM in its experiments.
This gives you a more mature angle:
The first RLM paper opened the door. The next race is not “who has the biggest context window?” It is “who can train the best context manager?”
Stronger “why this matters” section
The breakthrough matters because it attacks three bottlenecks at once:
1. Context quality
The model no longer has to attend over every irrelevant token.
2. Cost shape
The system can spend tokens only where useful instead of paying to ingest everything.
3. Agent duration
Long-running agents need to manage history, files, logs, search results, tests, and tool traces. Bigger windows delay collapse; active context management may prevent it.
The paper shows that RLM costs can be comparable or cheaper in median cases, but also warns that cost and runtime have high variance because different trajectories can take very different numbers of steps.
Add a production architecture
This is a missing “genius-level” element. Turn RLM into an implementation blueprint:
User query
↓
Root model
↓
Context environment
- documents
- codebase
- logs
- database rows
- embeddings
- search indexes
- previous run traces
↓
Programmatic tools
- regex
- AST parser
- grep
- SQL
- BM25
- vector search
- diff tools
- test runner
↓
Sub-model calls
- file analyst
- contradiction checker
- evidence extractor
- code reviewer
- legal clause reader
- timeline builder
↓
Verifier
- citations
- tests
- consistency checks
- source coverage
↓
Final synthesis
This turns the concept into a product roadmap.
Add a “when to use RLM” matrix
Use caseRLM fitWhy10-page document Q&ALowDirect context is simpler500-page legal contractHighNeed targeted search and clause synthesisFull codebase migrationHighNeed navigation, grep, AST, tests, subagentsSimple summarizationMedium-lowSummarization baseline may be enoughMulti-hop research over many docsHighIterative retrieval beats one-shot retrievalExact extractionHighCode search can be deterministicCreative writingLowLong external context may not helpSecurity log analysisHighSearch, filtering, and anomaly isolation matterLong-running coding agentVery highContext history needs externalizationTiny promptLowRLM overhead may hurt
Add an “RLM beats RAG when…” section
RLM is most useful when:
The answer requires several passes over the data.
The relevant evidence is not known before reasoning starts.
The query changes as the model learns more.
Distant sections interact.
The document has structure that code can exploit.
The task benefits from exact operations: grep, count, parse, diff, sort, filter.
The output needs verification.
The input is too large or too noisy to fully ingest.
RAG may still be better when:
The query is simple.
The corpus is already indexed well.
The answer lives in one or two obvious chunks.
Latency must be extremely low.
You cannot safely run code.
You need deterministic retrieval with strict governance.
Add the security section
This is a major missing element.
RLMs are powerful because the model can write code. That is also the danger. The GitHub README says the default local environment runs through Python exec and should not be used for production settings; it recommends isolated environments for risky cases.
Add:
The production version of RLM is not “give the model a terminal and pray.” It needs sandboxing, filesystem controls, network controls, execution timeouts, package restrictions, audit logs, output caps, and prompt-injection defenses.
Production checklist:
Sandbox every REPL.
Disable network by default.
Mount input data read-only.
Set CPU, memory, and wall-clock limits.
Limit printed output per tool call.
Require allowlisted packages.
Log every code cell and sub-call.
Hash the external context.
Track token and dollar budgets.
Run deterministic verifiers where possible.
Use separate credentials per run.
Prevent sub-calls from receiving secrets.
Add prompt-injection scanning for external documents.
Add “RLM observability”
This could become a killer product feature.
Every RLM answer should ship with a trace:
What did it search?
Which slices did it inspect?
Which sub-models did it call?
What did each sub-model answer?
Which evidence supported the final answer?
What code did it execute?
What was ignored?
How much did each step cost?
Where did it change its mind?
The GitHub repo already includes optional trajectory metadata, logging, and a visualizer for reconstructing RLM runs.
Suggested line:
The answer is not the product. The trace is the product.
That is especially true for legal, finance, code, medicine, compliance, and research.
Add “the next benchmark should not be long context; it should be long work”
Most long-context benchmarks test whether a model can answer from a big prompt. But agents need to survive long workflows.
Suggested benchmark ideas:
1. Month-long repo benchmark
Agent must fix issues across a simulated month of commits, tests, regressions, and changing requirements.
2. Litigation discovery benchmark
Millions of tokens of emails, exhibits, contracts, and depositions. Task: build timeline, identify contradictions, cite evidence.
3. Scientific literature synthesis benchmark
Thousands of papers with contradictory findings. Task: produce a review with uncertainty and evidence maps.
4. Incident-response benchmark
Logs, tickets, code diffs, alerts, and chat transcripts. Task: find root cause and propose remediation.
5. Product-memory benchmark
Agent maintains a project over weeks: specs, customer feedback, design docs, bugs, launch changes.
6. Long-output construction benchmark
Not just answer a question — produce a correct artifact larger than the base model’s output limit.
This connects to the paper’s point that RLMs may scale both effective input and output length by storing and passing intermediate outputs through variables.
Better critique of “context window wars are over”
Do not say:
The context window wars are over.
Say:
The context-window war just became a two-front war.
Because bigger windows still matter. Prime Intellect explicitly argues that efficient attention and context folding are both needed for long-running agents: better attention delays context rot, while context folding lets models actively manage context beyond what attention alone can do.
Better ending:
The winner will not be the lab with the biggest window. It will be the lab whose models know what to keep, what to fetch, what to delegate, what to verify, and what to forget.
Obscure but powerful angle: “RLM is a cognitive prosthesis, not memory”
This is philosophically clean.
Human intelligence is not just brain capacity. It is notebooks, search, libraries, colleagues, calculators, maps, calendars, and procedures. RLMs push AI in that direction.
Use:
RLM is not artificial memory. It is artificial scholarship.
Or:
It does not make the model omniscient. It gives the model research habits.
Obscure but powerful angle: “from monolithic inference to recursive inference”
The draft should emphasize that this changes the unit of inference.
Old unit:
One prompt in, one model call out.
New unit:
One root call orchestrating many bounded calls over external state.
That is a major architectural shift.
Suggested phrase:
The model call becomes a computation graph.
Obscure but powerful angle: “anti-forgetting by non-ingestion”
Most memory systems try to decide what to keep. RLM’s trick is: do not ingest most of it in the first place.
Use:
The cleanest way to stop a model from forgetting a fact is to stop asking it to remember the fact until it needs it.
That is a banger.
Obscure but powerful angle: “working memory vs reference memory”
The draft should distinguish:
Working memory: what the model actively attends to.
Reference memory: what remains externally accessible.
Episodic memory: previous tool traces and decisions.
Procedural memory: strategies for searching and decomposing.
Semantic memory: durable knowledge or indexed documentation.
RLM mainly improves the relationship between working memory and reference memory.
Suggested line:
RLMs do not erase the need for memory systems. They clarify the hierarchy: keep working memory small, reference memory exact, and procedural memory trainable.
Add “what models need to learn next”
The paper’s future-work section says explicitly training models to be used as RLMs could improve performance because current models are inefficient decision-makers over their context.
Training targets:
When to search.
When to read sequentially.
When to call sub-models.
When to use code instead of language.
When to stop.
When to verify.
How much context to show a sub-model.
How to combine sub-results.
How to avoid redundant calls.
How to estimate uncertainty.
How to manage a budget.
How to produce a trace.
Best line:
The next frontier is not larger context. It is learned context policy.
Add “what could kill RLM adoption”
This is the missing sober section.
RLMs could fail in production if:
Latency is too high.
Cost variance is hard to cap.
Sandboxing is difficult.
Tool traces are hard to debug.
Models over-search or under-search.
Sub-calls create inconsistent answers.
Security teams reject arbitrary code generation.
Short-context workloads do not justify orchestration overhead.
Vendors integrate similar ideas natively and erase the library-level advantage.
Benchmarks overstate gains on tasks where regex/search is unusually helpful.
That last point matters. If a benchmark rewards string search, RLM will look incredible. The true test is semantically dense, adversarial, cross-document reasoning where the search terms are not obvious.

MIT just made every AI company's billion dollar bet look embarrassing.
They solved AI memory. Not by building a bigger brain. By teaching it how to read.
The paper dropped on December 31, 2025. Three MIT CSAIL researchers. One idea so obvious it hurts. And a result that makes five years of context window arms racing look like the wrong war entirely.
Here is the problem nobody solved.
Every AI model on the planet has a hard ceiling. A context window. The maximum amount of text it can hold in working memory at once. Cross that line and something ugly happens — something researchers have a clinical name for.
Context rot.
The more you pack into an AI's context, the worse it performs on everything already inside it. Facts blur. Information buried in the middle vanishes. The model does not become more capable as you feed it more. It becomes more confused. You give it your entire codebase and it forgets what it read three files ago. You hand it a 500-page legal document and it loses the clause from page 12 by the time it reaches page 400.
So the industry built a workaround. RAG. Retrieval Augmented Generation. Chop the document into chunks. Store them in a database. Retrieve the relevant ones when needed.
It was always a compromise dressed up as a solution.
The retriever guesses which chunks matter before the AI has read anything. If it guesses wrong — and it does, constantly — the AI never sees the information it needed. The act of chunking destroys every relationship between distant paragraphs. The full picture gets shredded into fragments that the AI then tries to reassemble blindfolded.
Two bad options. One broken industry. Three MIT researchers and a deadline of December 31st.
Here is what they built.
Stop putting the document in the AI's memory at all.
That is the entire idea. That is the breakthrough. Store the document as a Python variable outside the AI's context window entirely. Tell the AI the variable exists and how big it is. Then get out of the way.
When you ask a question, the AI does not try to remember anything. It behaves like a human expert dropped into a library with a computer. It writes code. It searches the document with regular expressions. It slices to the exact section it needs. It scans the structure. It navigates. It finds precisely what is relevant and pulls only that into its active window.
Then it does something that makes this recursive.
When the AI finds relevant material, it spawns smaller sub-AI instances to read and analyze those sections in parallel. Each one focused. Each one fast. Each one reporting back. The root AI synthesizes everything and produces an answer.
No summarization. No deletion. No information loss. No decay. Every byte of the original document remains intact, accessible, and queryable for as long as you need it.
Now here are the numbers.
Standard frontier models on the hardest long-context reasoning benchmarks: scores near zero. Complete collapse. GPT-5 on a benchmark requiring it to track complex code history beyond 75,000 tokens — could not solve even 10% of problems.
RLMs on the same benchmarks: solved them. Dramatically. Double-digit percentage gains over every alternative approach. Successfully handling inputs up to 10 million tokens — 100 times beyond a model's native context window.
Cost per query: comparable to or cheaper than standard massive context calls.
Read that again. One hundred times the context. Better answers. Same price.
The timeline of the arms race makes this sting harder. GPT-3 in 2020: 4,000 tokens. GPT-4: 32,000. Claude 3: 200,000. Gemini: 1 million. Gemini 2: 2 million. Every generation, every company, billions of dollars spent, all betting on the same assumption.
More context equals better performance.
MIT just proved that assumption was wrong the entire time.
Not slightly wrong. Fundamentally wrong. The entire premise of the last five years of context window research — that the solution to AI memory was a bigger window — was the wrong answer to the wrong question.
The right question was never how much can you force an AI to hold in its head.
It was whether you could teach an AI to know where to look.
A human expert handed a 10,000-page archive does not read all 10,000 pages before answering your question. They navigate. They search. They find the relevant section, read it deeply, and synthesize the answer.
RLMs are the first AI architecture that works the same way.
The code is open source. On GitHub right now. Free. No license fees. No API costs. Drop it in as a replacement for your existing LLM API calls and your application does not even notice the difference — except that it suddenly works on inputs it used to fail on entirely.
Prime Intellect — one of the leading AI research labs in the space — has already called RLMs a major research focus and described what comes next: teaching models to manage their own context through reinforcement learning, enabling agents to solve tasks spanning not hours, but weeks and months.
The context window wars are over.
MIT won them by walking away from the battlefield.
Source: Zhang, Kraska, Khattab · MIT CSAIL · arXiv:2512.24601
Paper: arxiv.org/abs/2512.24601
GitHub: github.com/alexzhang13/rlm
1
319