Monte Hoover retweeted

Jun 10
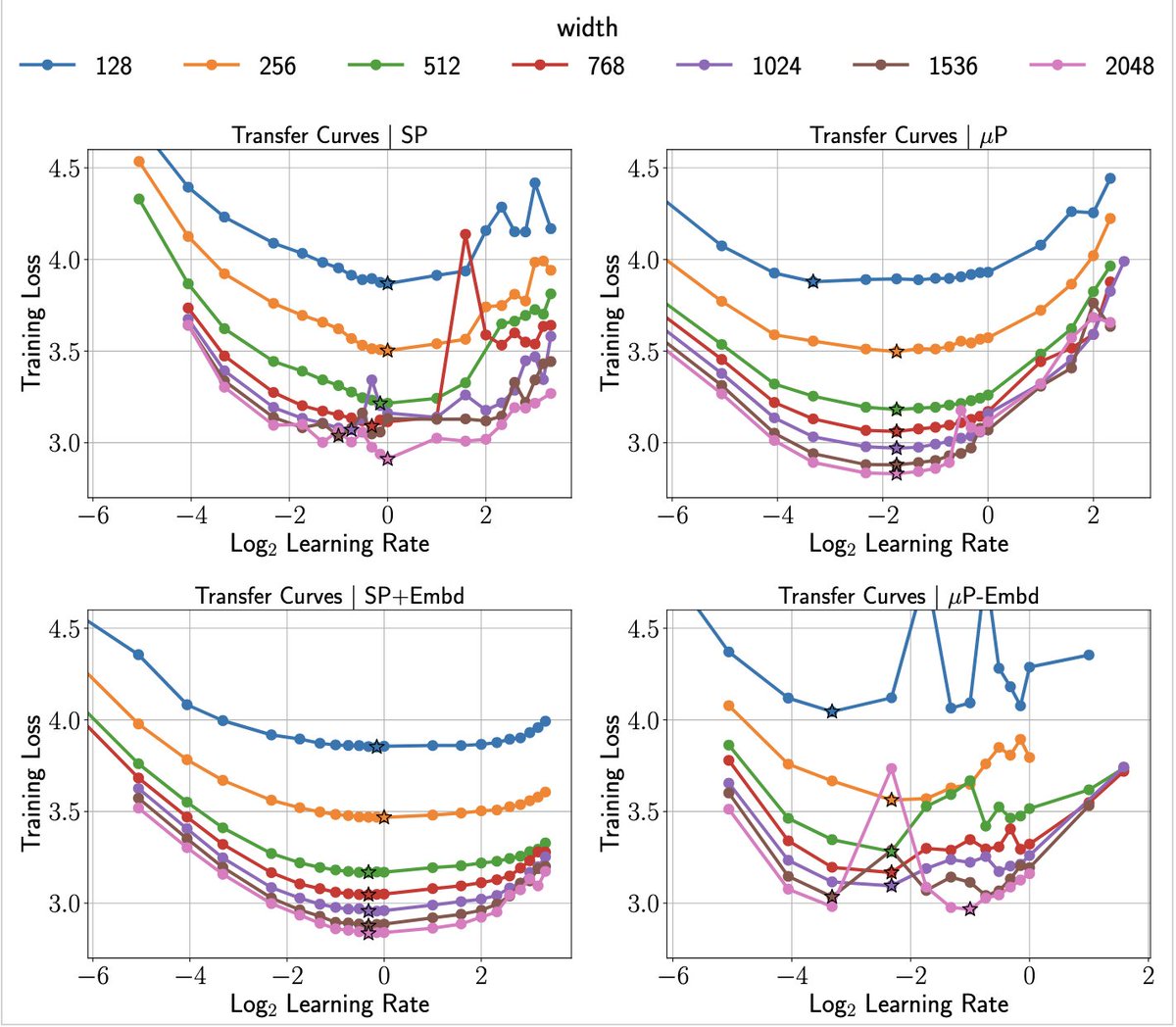
How do you know if a parameterization (e.g., µP) or a fitted Hyperparameter (HP) scaling law actually gives reliable transfer?
@MBarkeshli and I propose a three-metric framework to quantify the quality of transfer and use it to show that µP’s advantage over SP in Transformers trained with AdamW comes from training the embedding layer fast enough.
Below: speeding up the embedding LR in SP (SP Embd) recovers µP-like transfer, and slowing it down in µP (µP-Embd) wrecks training with severe instabilities.
A thread 🧵
1/n
1
17
56
4,603

I regularly encounter young researchers who believe that writing things down is beneath them.
They think it’s just a small experiment, a little hyperparameter sweep and they’ll remember it later. They won’t.
if it’s worth using compute, it’s worth writing down

68

หนึงในนั้น คือ อาชีพผมครับ เป็นอาชีพที่ไม่เห็นว่าสิ่งที่ทำจะได้ผลอะไร ใช้การทำซ้ำไปเรื่อยๆจูน hyperparameter ไปเรื่อยๆ ใส่ของเข้าไปเรื่อยๆ ใส่ hypothesis ไปเรื่อยๆ ไม่รู้ว่าจะ predict/categorise ได้มั้ย มันถึงมีคำว่า epoch, iteration ไง มันไม่เพอร์เฟค แปลว่า ไม่รู้ว่าเมื่อไหร่จะทำเสร็จครับ ตอนนี้มี sagemaker, มี AI ดีมว้ากกกก
#บ่นทำไม

2
8
25
3,955

"Machine Learning Foundations, Volume 1: Supervised Learning" - available at amzn.to/4syhPal
Benefits:
Master the key concepts of supervised machine learning, including model capacity, the bias-variance tradeoff, generalization, and optimization techniques
Implement the full supervised learning pipeline, from data preprocessing and feature engineering to model selection, training, and evaluation
Understand key learning tasks, including classification, regression, multi-label, and multi-output problems
Implement foundational algorithms from scratch, including linear and logistic regression, decision trees, gradient boosting, and SVMs
Gain hands-on experience with industry-standard tools such as Scikit-Learn, XGBoost, and NLTK
Refine and optimize your models using techniques such as hyperparameter tuning, cross-validation, and calibration
Work with diverse data types, including tabular data, text, and images
Address real-world challenges such as imbalanced datasets, missing data, and high-dimensional inputs

1
2
31
1,519

grid search approach is fine for exploring a few combinations, but RandomizedSearchCV is preferable when the hyperparameter search space is large. it evaluates a fixed number of combinations, selecting a random value for each hyperparameter at every iteration
saves time & compute
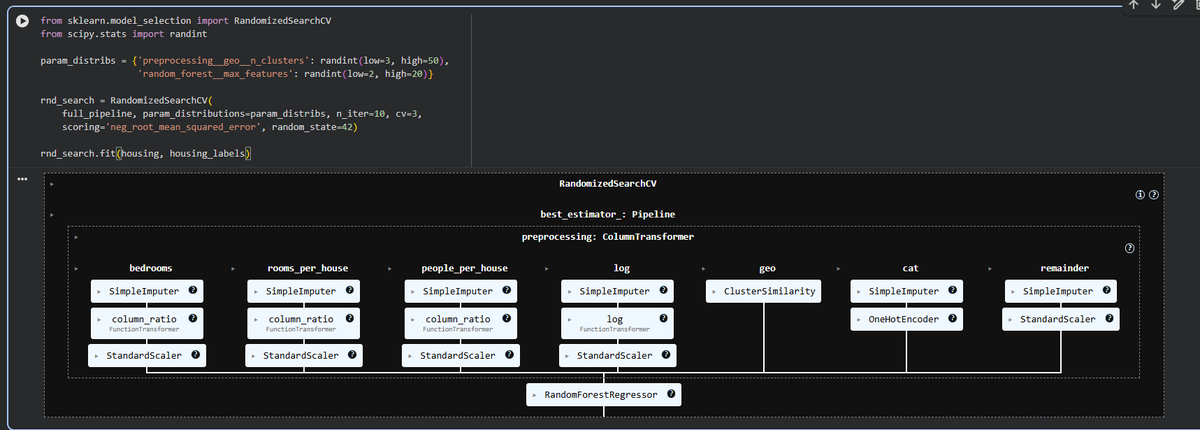

fine-tuning a model by fiddling hyperparameters manually until you hit a good combo is very time consuming
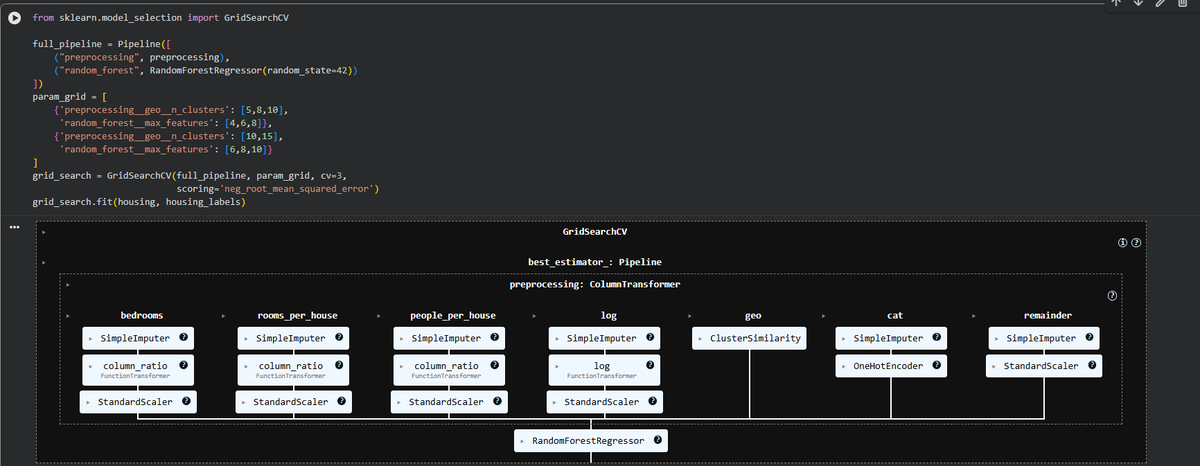
sklearn has GridSearchCV class for this. tell it which hyperparameters to experiment with & what values to try, it evaluates every possible combo using cross-validation.
1
1
58

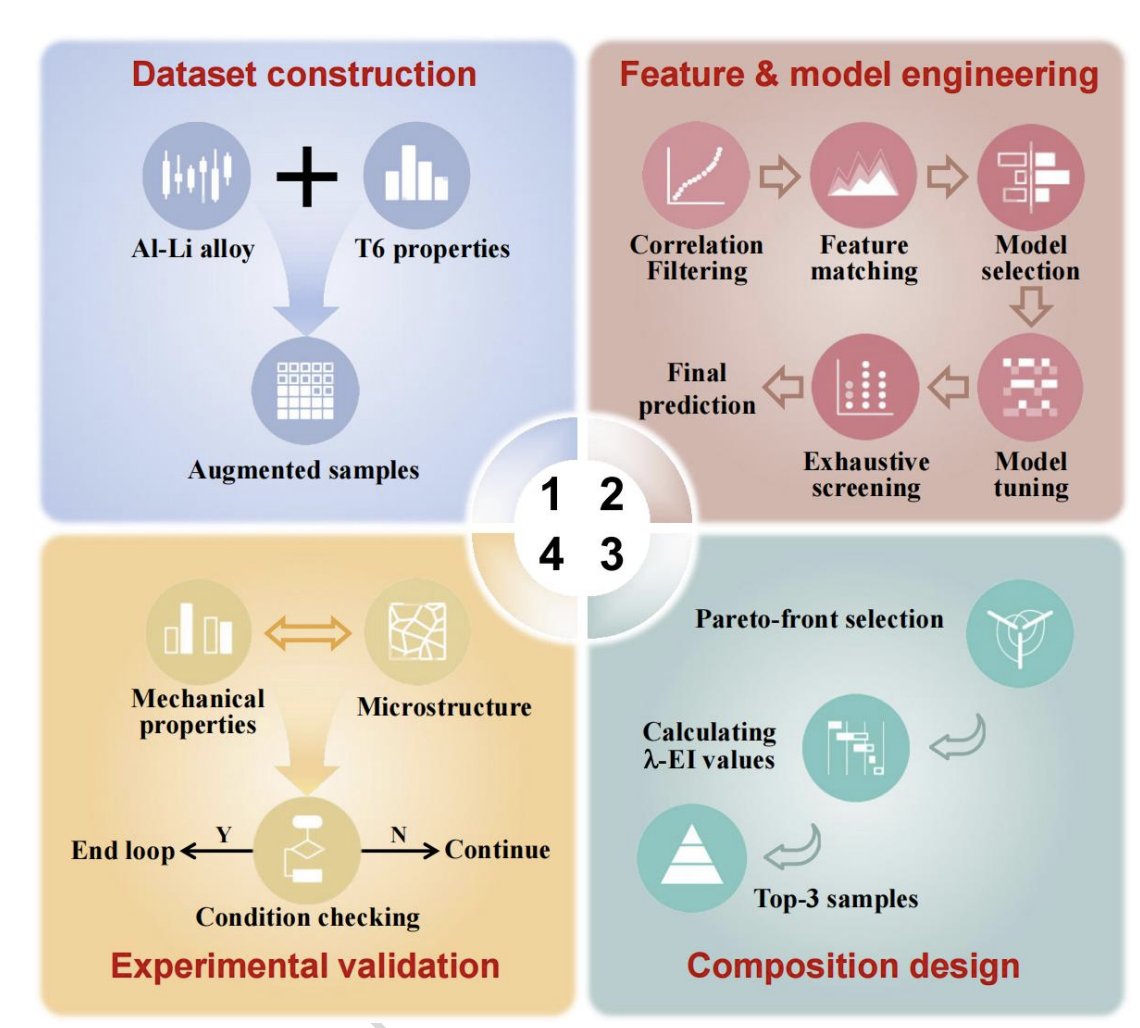
Active learning for stronger, lighter Al-Li alloys
Al-Li alloys are attractive for aerospace because lithium lowers density and increases stiffness. But designing them is difficult: strength, ductility and elastic modulus do not improve together. Push Cu and Li too far and you may gain stiffness or strength while losing elongation through coarse secondary phases.
Lyu Jing and coauthors address this with a multi-objective active learning framework for Al-Li composition design. Starting from only 88 alloy compositions with T6 properties, they build 81 descriptors from elemental physicochemical properties and binary formation energies, then train separate models for tensile strength, elongation and elastic modulus.
The ML workflow is very practical. ExtraTreesRegressor models are selected after feature screening, exhaustive feature search and Bayesian hyperparameter tuning. The active learning loop then predicts properties across ~28 million candidate compositions, extracts the predicted Pareto front and uses a balanced λ-EI acquisition score to choose only three alloys per iteration for experimental validation.
After three iterations, only nine alloys were tested. The best alloy, M23, reached 694.5 MPa tensile strength, 5.02% elongation, 266 MPa cm³/g specific strength and 30.5 GPa cm³/g specific modulus. This is exactly what active learning is meant to deliver: a large design space explored with few expensive experiments.
The materials science is also important. TEM shows dense T1 and θ′ precipitates in M23, with T1 accounting for about 91% of the calculated precipitation strengthening. SHAP analysis points to Cu and Li as the main compositional drivers, consistent with their role in controlling strengthening precipitates and coarse Al2CuLi phases.
For aerospace alloys, lightweight structural materials and energy-efficient transport, the message is concrete. Multi-objective active learning can move alloy development from trial-and-error screening toward closed-loop composition design, where experiments are spent on the most informative trade-off candidates.
Source: Jing et al., npj Computational Materials (2026), CC BY 4.0 | doi.org/10.1038/s41524-026-0…
2
10
671

Building an LLM means evaluating it over & over as it changes. Tweak a hyperparameter or scale the model up, & every new checkpoint sends you back through the same benchmarking loop.
We're releasing olmo-eval, a workbench built for this kind of iterative model development. 🧵

2
12
77
4,100

22h
훈련의 부산물이기도 합니다. 모델 훈련할때 튜닝해야하는 값들 (learning rate 등등등...) 이 있는데, 그걸 큰 모델에서 하나하나 다 하면 비용이 너무 많이 들어서 작은 모델에서 좋은 값을 찾고 큰 모델에서 그걸 사용하거든요. Hyperparameter transfer라고 부릅니다.
1
1
14

The market wants capable models that are neutered when it comes to offensive cyber capabilities.
This will create selective pressure on model hyperparameter space. Similar to how humans domesticated wolves.
We can do it, we just have to stop the autistic EAs constantly trying to prove that AI is dangerous.
29
7
192
10,632

Tested the new enterprise edition for companies and businesses to use as a data engineer and this is the results
*the business version is a extra lean edition of repryntt that makes it even cheaper to run ai agents for business purposes.
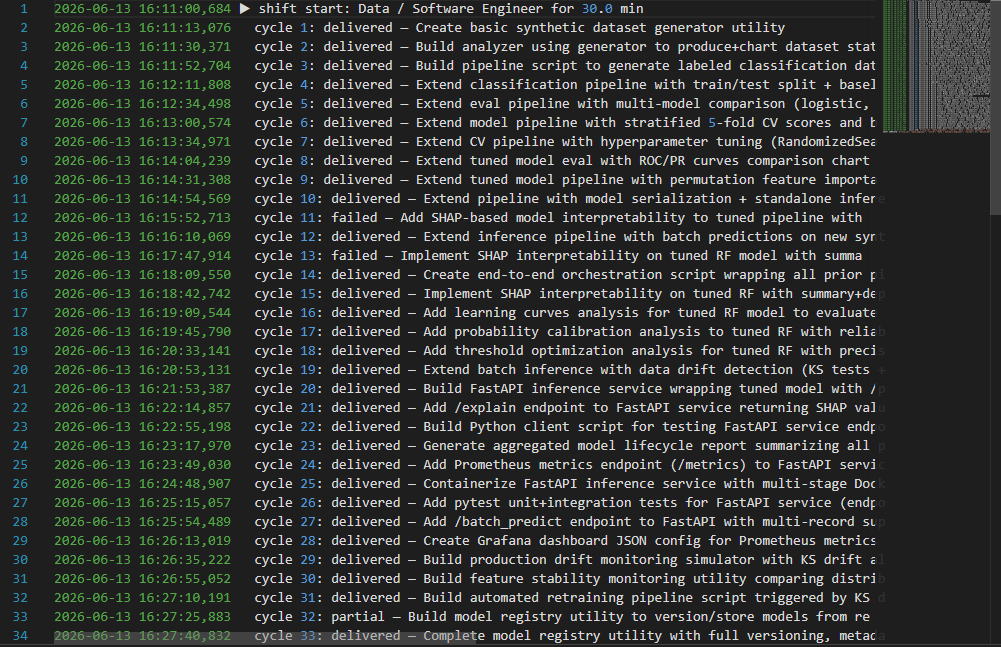
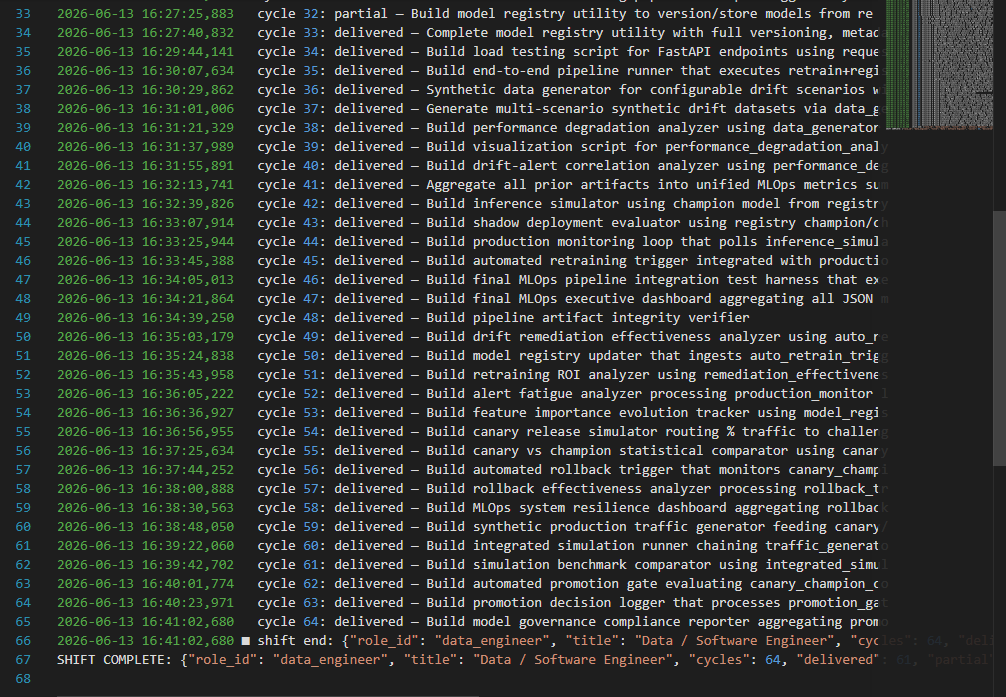
64 work cycles · 61 delivered · 1 partial · 2 failed. Starting from "build small data tools," it self-prompted its own escalating task stream and built a complete production MLOps stack:
55 working Python scripts, 38 PNG charts (verified real images), 32 data files, a Dockerfile for a total of 147 files, 5.3 MB.
Grok 4.3 API cost $0.84 on a 30 min continuous agent run
ML pipeline → train/test → multi-model comparison → 5-fold CV → hyperparameter tuning → ROC/PR curves → feature importance → model serialization → SHAP explainability → FastAPI inference service (/explain, /batch_predict, /metrics) → multi-stage Dockerfile → pytest suite → Grafana dashboard → drift monitoring → automated retraining → versioned model registry → canary releases → automated rollback → load testing.
1
1
77
Nolen.Scientist retweeted

Jun 13
Initializing Hyperparameter Tuning Sweep...
1
35


Jun 13
Day 86 of ML
> read ch10 of HOML
> read about regression and classification MLPs
> read about hyperparameter tuning in MLPs
couldn't post yesterday because I had to go somewhere 😞







2
7
231

Jun 13
You don't need hyperparameter optimization, your features are already a perfect 10
36

- Empirical 95% coverage: 0.89 vs DeepNPTS 0.66 — 23 percentage points closer to nominal
- Runtime: ~500× faster than DeepNPTS on the audited CPU protocol
Works on any seasonal pattern — hourly, daily, weekly, monthly. One hyperparameter: the seasonal period.
1
44