André Faustino retweeted
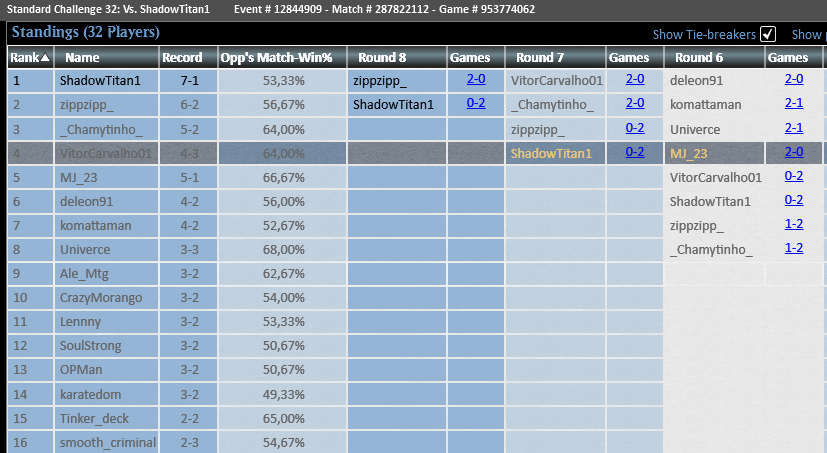
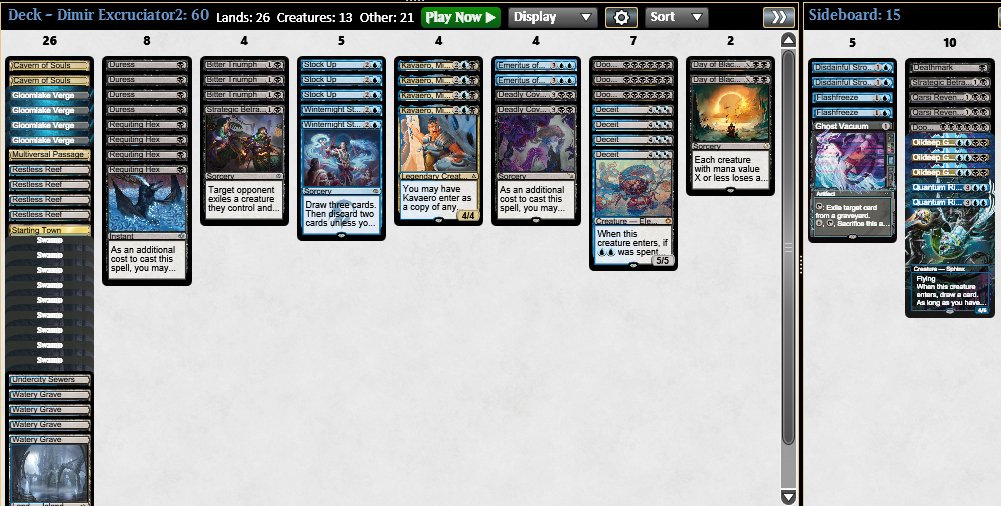
Top4 in the Standard Challenge Playing with UB Excruciator.
Sideboard Guide is avaible just send DM for more infs.
@fireshoes
@Mana_traders
6
17
1,825

Ce sera le problème des infs qui changeront tes bandages, de la secu qui paiera pour tout ça, de tes proches qui s’inquiéteront pour toi etc..
Après honnêtement je m’en fous, c’est ton dos. C’est vrai, tu ne mets que toi en danger, mais t’impactes d’autres personnes, sache le !
1
102

Jun 16
The Minister of Finance and Development Planning, Dr. Retšelisitsoe Matlanyane, has officially launched the Lesotho Integrated National Financing Strategy (INFS) in Maseru today.
mohalefm.co.ls/lesotho-launc…

13

Jun 15
```
# Define columns (You will need to adjust these based on the exact CICIDS 2017 headers)
metadata_cols = ['Flow ID', 'Source IP', 'Destination IP', 'Timestamp']
port_cols = ['Src Port', 'Dst Port']
# Drop metadata and target label from X
X_raw = df_sample.drop(columns=metadata_cols ['Label'], errors='ignore')
y_raw = df_sample['Label']
# Clean Infinities directly on the dataframe copy
X_raw = X_raw.replace([np.inf, -np.inf], np.nan)
# Encode well-known ports directly on the dataframe (< 1024)
for col in port_cols:
if col in X_raw.columns:
X_raw[col] = (X_raw[col] < 1024).astype(int)
# Separate continuous numeric columns from categorical numeric columns (Ports)
continuous_numeric_cols = [col for col in X_raw.columns if col not in port_cols and pd.api.types.is_numeric_dtype(X_raw[col])]
numeric_pipeline = Pipeline([
('fill_missing', SimpleImputer(strategy='median')),
('smart_scaling', RobustScaler())
])
# Build the simplified preprocessor
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_pipeline, continuous_numeric_cols),
('ports', 'passthrough', port_cols)
],
remainder='drop'
)
smote = SMOTE(random_state=42)
# Note: If X_raw still contains NaNs or Infs, SMOTE will actually crash here.
X_resampled, y_resampled = smote.fit_resample(X_raw, y_raw)
# Split the RAW data (No leakage!)
X_train, X_cv, y_train_raw, y_cv_raw = train_test_split(X_resampled, y_resampled, test_size=0.2, random_state=42)
# Encode the target labels (XGBoost needs integers)
label_encoder = LabelEncoder()
y_train = label_encoder.fit_transform(y_train_raw)
y_cv = label_encoder.fit_transform(y_cv_raw)
```
35


Jun 15
The Ministry of Finance and Development Planning and UNDP Lesotho launched the Integrated National Financing Strategy (INFS), a roadmap to strengthen financing for sustainable development and accelerate progress towards Lesotho's development priorities and the SDGs.


1
3
8
490
William melo retweeted

Jun 15
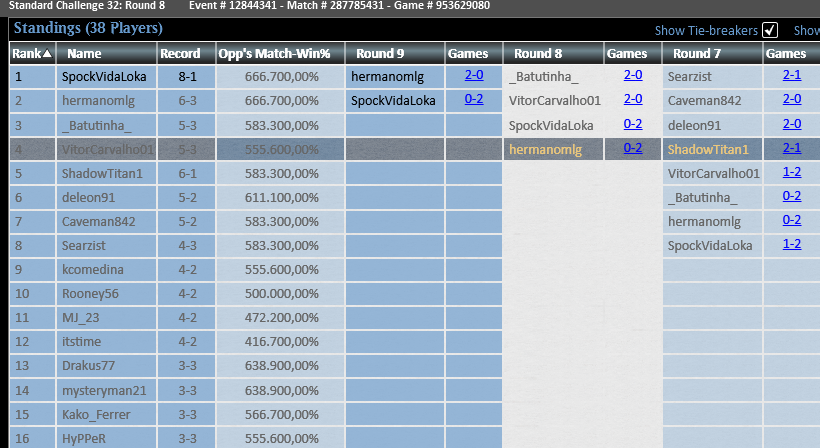
Top4 in the Standard Challenge Playing UB Excruciator
Sideboard Guide is Avaible just send DM for more infs
@fireshoes
@Mana_traders

4
19
2,157

Jun 13
I remember seeing someone on Instagram posts their POTS (triggered by multiple covid infs) struggles and they literally got a very extreme spell while driving and turning to check right/left before turning. Then ofc they had to stop and wait for a relative to pick them up.
2
2
90

Jun 13
Just got my CPR AED certificate today. 1 step closer to formally being certified as a Trainer from INFS. But I don’t work at any gym. And for sure my gym doesn’t even have a basic first aid kit.

1
1
27


Jun 13
Cooking up some float64 abstract interpretation out of a conversation with a colleague about all the implicit assumptions made about valid double values made throughout the codebase.
(Choosing to ignore here 1) overflow 2) infs of opposite signs yielding NaN.)

1
1
86