
43m
未来 3 个月的挑战就是:让全世界做无人机 AI 的人都用 Swarm 来评测模型。
他们想把 Swarm 这个基准打造成全球衡量 AI 无人机自主能力的标准,类似于 ImageNet 在视觉领域的作用。
此外,他们开源了 Langostino 无人机,并提供了完整组装教程和 3D 打印文件,任何人都能自己组装一台去测试。
1
26
Adventure Kids retweeted

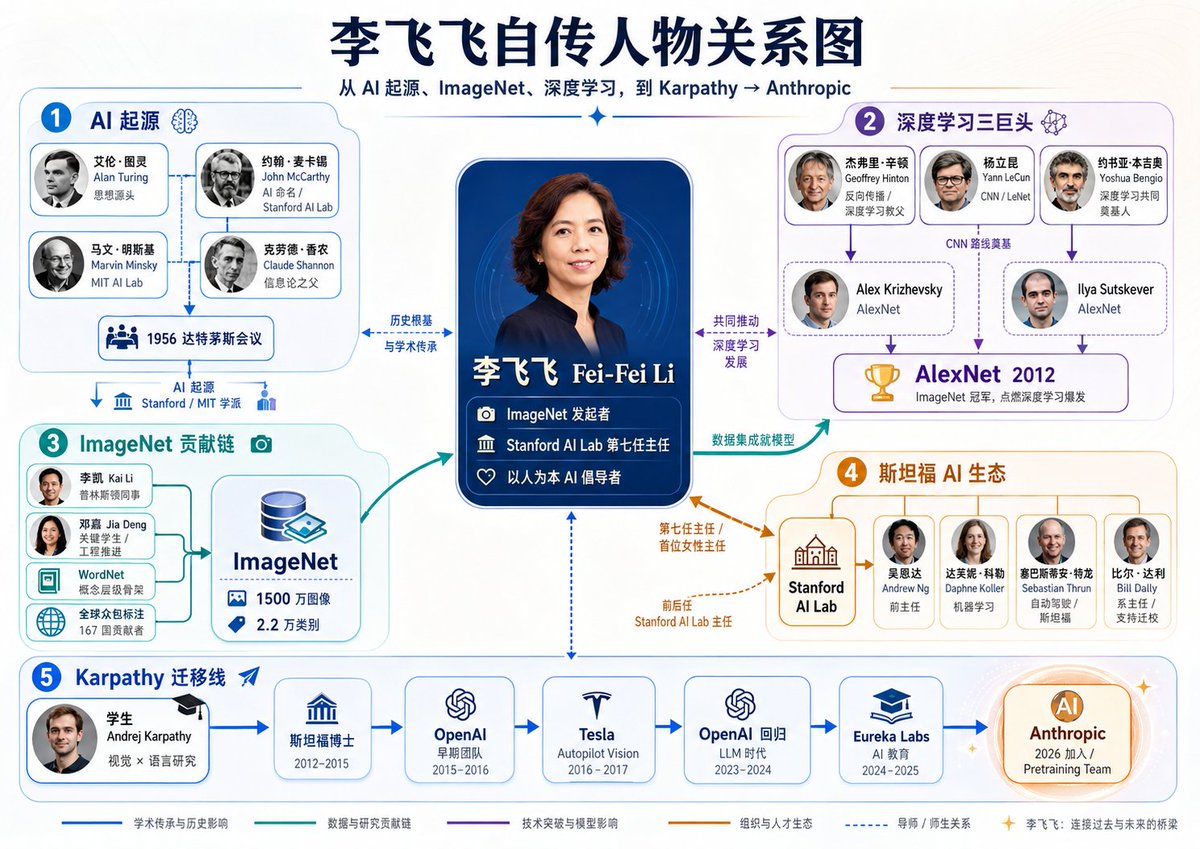
李飞飞代表 ImageNet 时代
Karpathy (李飞飞学生)代表从视觉 AI 到 LLM 时代的人才迁移,而如今又回归到企业的Reasearch岗
在《我看见的世界》原文脉络里,Karpathy 那一段的重点是,他放弃普林斯顿教职,加入当时还不知名的 OpenAI 核心工程团队,这被李飞飞写成 AI 顶级人才从学术界流向私人研究实验室的标志性时刻。
Jun 13

也许编程这一领域已经终结
对于大多数人来说,Skills早已足够
而Loop只有少数人才需要掌握
人总是高估熟能生巧的经验
又不愿意去做一些设立目标的事情,就像OKR/KPI也只有少数设定者
2
9
24
7,815
4681779198 retweeted

5 Jan 2021
An NN takes a list of category names, and outputs (in a zero-shot manner) a visual classifier.
It beats RN50 on ImageNet zero-shot, while being far more robust to unusual images:
openai.com/blog/clip/

11
91
474


Few more,
@ylecun
= Yann LeCun, Turing Award winner & deep learning pioneer (CNNs) at Meta
@lexfridman
= Lex Fridman, MIT researcher & AI podcast host with deep interviews
@drfeifei
= Fei-Fei Li, Stanford prof & ImageNet/computer vision pioneer
@geoffreyhinton = Geoffrey Hinton, Godfather of deep learning & AI safety expert
@GaryMarcus
= Gary Marcus, cognitive scientist & critic of current AI limits
@kaifulee
= Kai-Fu Lee, AI author/investor & founder of 01.AI
@ID_AA_Carmack
= John Carmack, AGI researcher & legendary programmer
@rowancheung
= Rowan Cheung, runs The Rundown AI newsletter
@AnimaAnandkumar= Anima Anandkumar, NVIDIA research director & AI for science
@random_walker
= Arvind Narayanan, Princeton prof on AI ethics & reliability
107
Karthik retweeted

I just published ImageNet Classification with Deep Convolutional Neural Networks (AlexNet) medium.com/p/imagenet-classi…
1
1
4
139

I agree - I think in the past there was definitely industry capture but it was more of a back and forth, semi-equal exchange (eg CNN imagenet era). Now it feels very one sided, like academia is constantly chasing after the latest industry release, but not getting as much back.
1
113
߷taizona℠ 51ᴛʙ
Taizō Nᴀʙᴇᴋᴜʀᴀ¹⁹⁷⁵
⛩️ retweeted

Jun 10
今後ベンチマークは登場した瞬間にモデルの自律的な進化で SOTA が人間の手を介さず更新されるようになる。その一方で、現在 LLM の解釈性研究が追い付かないように性能の裏側にある特徴量は未解明のまま利用が進む。既存の事例でも ImageNet に大量のバイアスかかったラベルがあることが分かったのは公開後ずいぶん経ってからだし、データセットに内在された潜在的バイアスがモデルを通じ世界中にバラまかれた形になることを考えると、LLM はその比でない影響を世界に与えることになる。
なので、Anthropic の懸念を利益や競合排除のスタンスと見るのではなく真摯に検討する段階に来ていると私は思う(利益追求が目的なら国防省敵に回さないでしょという)。オープンなコミュニティを通じ進化する理想論のモラトリアムが終焉を迎えつつある現実を開発者・研究者が自覚的になる時期だし現在の Fable の大判ぶるまいはその議論の幸先として不可欠なステップを Anthropic が提供してくれていると私は思うぜ。
1
10
53
9,282

Jun 13
🚨 UNA RED NEURONAL DE 385.217 parámetros podría haber marcado un antes y un después en la química computacional.
Durante más de 60 años, los científicos han usado la Teoría Funcional de la Densidad (DFT) para simular moléculas, materiales y reacciones químicas.
Esta tecnología es clave para investigar nuevos medicamentos, baterías, semiconductores y materiales avanzados.
Pero siempre ha tenido un gran problema:
La parte más difícil del cálculo, conocida como funcional de correlación e intercambio, no puede resolverse de forma exacta. Por eso, los científicos han tenido que crear aproximaciones cada vez más complejas.
Y aquí estaba el gran límite:
Más precisión casi siempre significaba mucho más coste computacional.
Microsoft acaba de presentar Skala, un nuevo funcional XC basado en aprendizaje profundo que podría cambiar esta regla.
En lugar de depender de fórmulas diseñadas manualmente durante años, Skala aprende directamente de enormes conjuntos de datos de mecánica cuántica de alta precisión.
El resultado es llamativo:
Consigue una precisión de primer nivel en el benchmark GMTKN55, uno de los puntos de referencia más importantes en química computacional, pero mantiene un coste computacional mucho más bajo, similar al de métodos DFT semilocales rápidos.
Lo más interesante no es solo que mejore los cálculos de energía.
También genera densidades electrónicas más precisas durante las iteraciones autoconsistentes.
Esto sugiere que el modelo no se limita a “acertar por casualidad” o aprovechar errores compensados, sino que podría estar aprendiendo patrones físicos reales del comportamiento cuántico.
Algunos investigadores lo describen como un posible “momento ImageNet” para la DFT.
Es decir:
Un punto de inflexión en el que los modelos de IA empiezan a mejorar de forma sistemática a medida que aumentan los datos de entrenamiento.
La implicación es enorme.
Si este enfoque sigue avanzando, podríamos estar ante una nueva generación de simulaciones científicas mucho más precisas, rápidas y escalables.
Esto permitiría hacer experimentos virtuales más fiables antes de pasar al laboratorio real.
Y eso podría acelerar el descubrimiento de nuevos materiales, fármacos, baterías, tecnologías energéticas y sistemas químicos complejos.
En otras palabras:
La IA no solo está ayudando a escribir código o generar imágenes.
También podría estar rediseñando una de las herramientas más importantes de la ciencia moderna.

6
9
1,880

they basically trained a dog classifier CNN to for the ImageNet CV challenge, and ran it in reverse and it could pulled weird alien puppy dog noses and eyes from noise or images


1
3
20

Jun 12
FrontierMath fixing many errors thanks to GPT Opus reminds me of this picture i made in our BigTransfer paper.
For the first time, our big model's "wrong" answer (top) was generally better than the ground truth (bottom) of ImageNet. Not cherry picked.

Jun 12

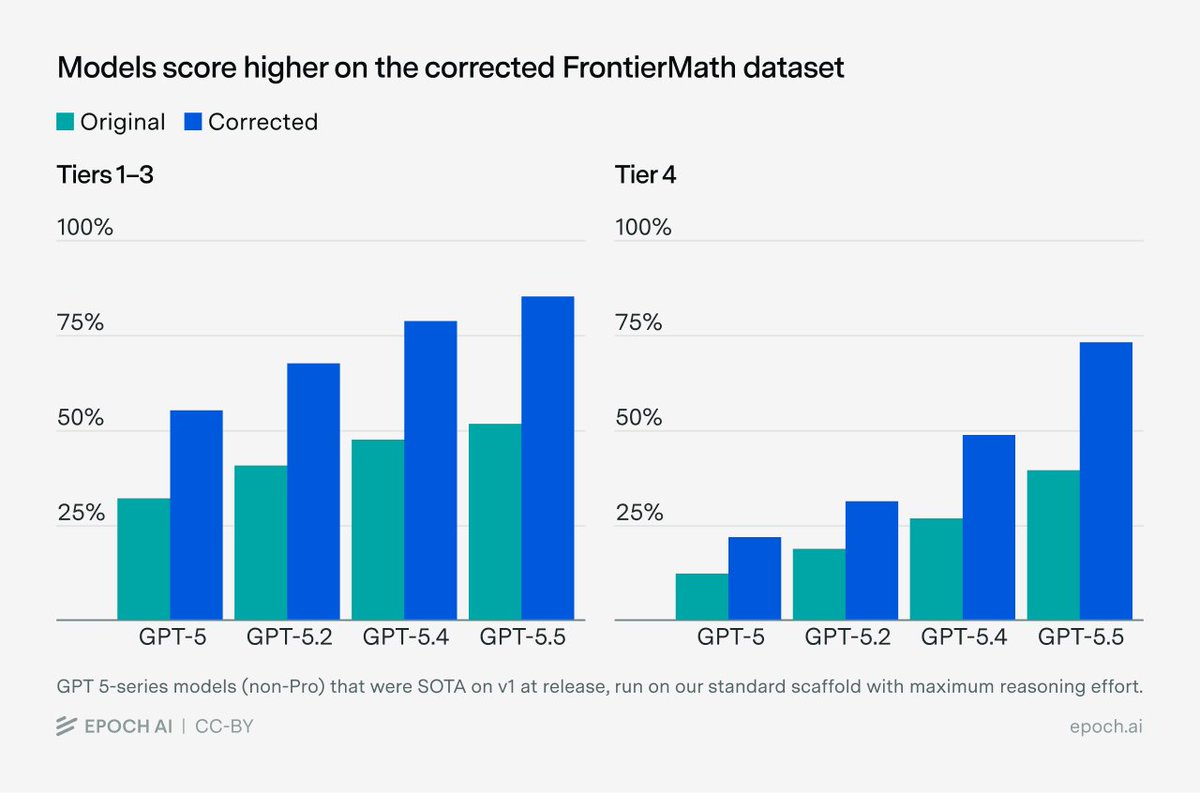
FrontierMath: Tiers 1–4 (v2) is live.
We concluded an audit that addressed errors in 42% of problems. Rankings are similar but scores are higher across the board. The current leaders are GPT-5.5 (xhigh) with 85% on Tiers 1–3 and Google’s AI co-mathematician with 76% on Tier 4.
4
6
64
9,976

Jun 12
I think there’s more to this though - crucially, is your benchmark only for evaluation (300-500 is sufficient), or does it include a train set (which needs more).
If ImageNet had only included 500 images to train on, we wouldn’t be where we are today!
4
173

Jun 12
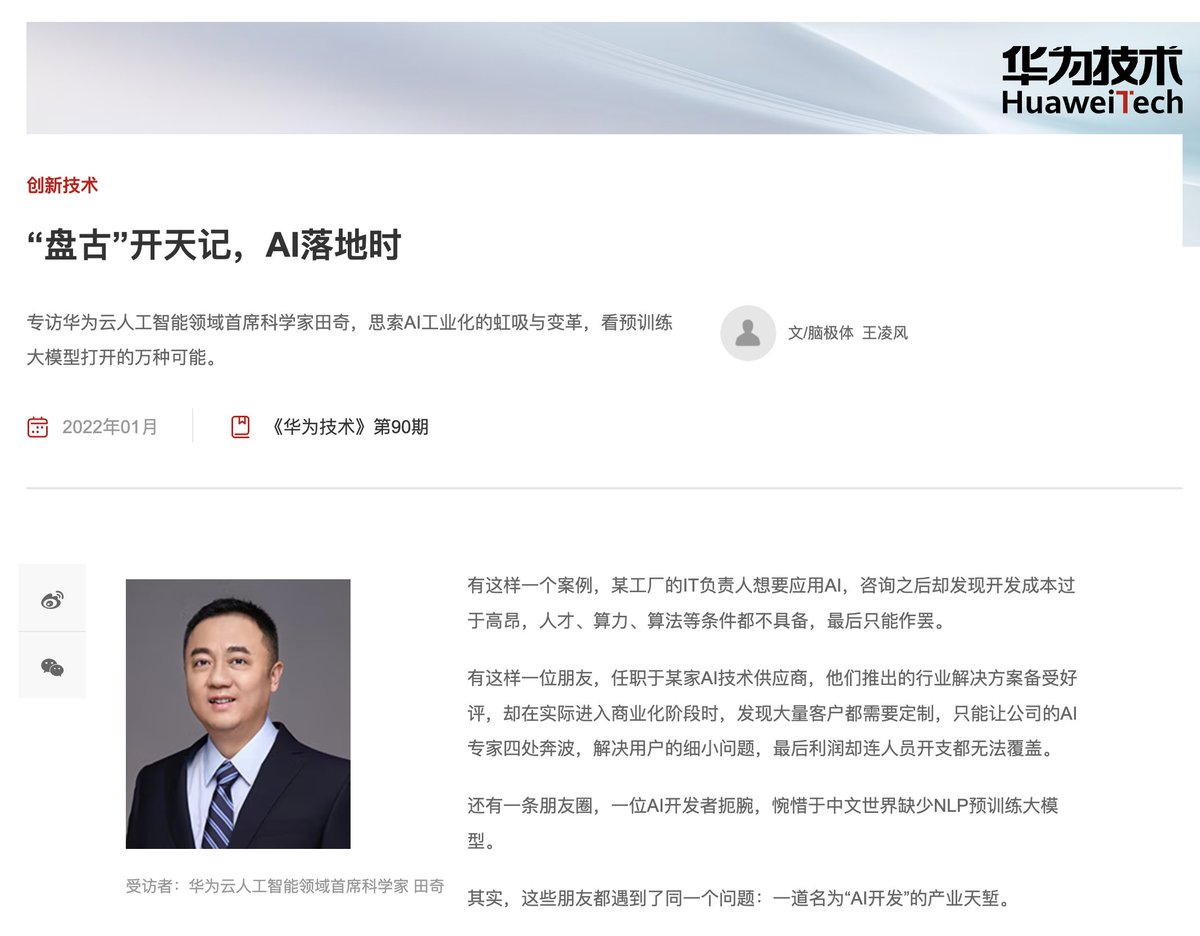
没想到华为还真是中国第一个做大模型啊??
只不过不是大家以为什么气象模型,而是真的是Encoder-Decoder这样架构的LLM。
华为云的官网有一片2022年的文章,采访的是当时华为云人工智能领域首席科学家田奇。
2020年夏天GPT-3的出现,让欧美AI界对预训练大模型的兴趣大增。
但在国内,产业界对NLP预训练大模型的关注还相对较少。而机器视觉领域的预训练大模型,在全球范围内更是十分陌生的新鲜事物。
2020年3月,田奇加入华为云后便开始组建团队,并且进行了方向梳理。
8月,团队迎来新的核心专家。
9月,团队开始推动盘古大模型的立项,希望能够在华为云的产业基座上,完成适配各个产业AI开发的大模型。
1月,盘古大模型在华为云内部立项成功,并完成了与合作伙伴、高校的合作搭建。
2021年4月,盘古大模型正式对外发布。
其中,盘古NLP大模型作为业界首个1100亿参数的中文预训练大模型,在CLUE打榜中实现了业界领先(后在2021年5月:升级至2000亿参数的"鹏程·盘古"版本)。
为了训练NLP大模型,团队在训练过程中使用了40TB的文本数据,包含了大量的通用知识与行业经验。
同时还发布了盘古CV大模型。
盘古CV大模型也在业界首次实现了模型的按需抽取,可以在不同部署场景下抽取出不同大小的模型,动态范围可根据需求调整,从特定的小场景到综合性的复杂大场景均能覆盖。
同时,其提出的基于样本相似度的对比学习,实现了在ImageNet上小样本学习能力上的业界第一。
但中国第一个完成备案的大模型是百度文心🤔
这又是因为啥呢
是盘古3.0之后发现了什么吗huawei.com/cn/huaweitech/pub…
19
2
60
40,580

Jun 12
Every major AI breakthrough traces back to a data advantage, not an algorithm advantage.
> GPT-4
> AlphaFold
> Stable Diffusion
All of them were enabled by someone solving a data collection problem nobody else had solved.
The term "data flywheel" comes from Amazon.
More customers bring more data.
More data produces better recommendations.
Better recommendations attract more customers.
The wheel spins faster as it gets bigger.
Every dominant AI system today has a version of this flywheel underneath it.
The LLM flywheel ran on the internet.
Common Crawl scraped billions of web pages.
GPT models trained on enormous amounts of text. None of this required anyone to go into the real world and collect data manually.
Robotics has no equivalent. You cannot scrape robot demonstrations from the web.
The closest real-world analogy is Tesla.
Every Tesla on the road generates training data. Models improve.
Autopilot gets better.
More people buy Teslas.
More data follows.
The system compounds because the fleet compounds.
Robotics has not had its ImageNet moment yet.
Before ImageNet, researchers hand-collected datasets and progress was slow.
After ImageNet, vision models trained in weeks instead of years.
Robotics still lacks that foundational data layer.
And that moment requires more than millions of demonstrations.
It requires a living, growing network of data across environments, tasks, and robot types.
It requires infrastructure to coordinate collection at scale, standardization to make datasets compatible, and incentives that sustain a global operator network.
The open vs closed data flywheel debate matters here. Closed systems create isolated flywheels where progress stays trapped inside individual companies. Open systems allow the entire ecosystem to compound on shared foundations.
But quantity alone is not enough.
Data quality has to compound alongside volume. Otherwise more data simply creates a faster race to garbage.
Quality control has to be embedded throughout the collection pipeline so the flywheel produces signal, not noise.
Robotics hasn't had its data flywheel moment yet because the infrastructure, standardization, and incentive layers required to make it happen don't exist.
That's the problem @PrismaXai is solving by building an open data flywheel for physical AI
Official Links
Linktree - linktr.ee/PrismaX_AI
Discord - discord.gg/prismaxai
Official X - @PrismaXai

Jun 8

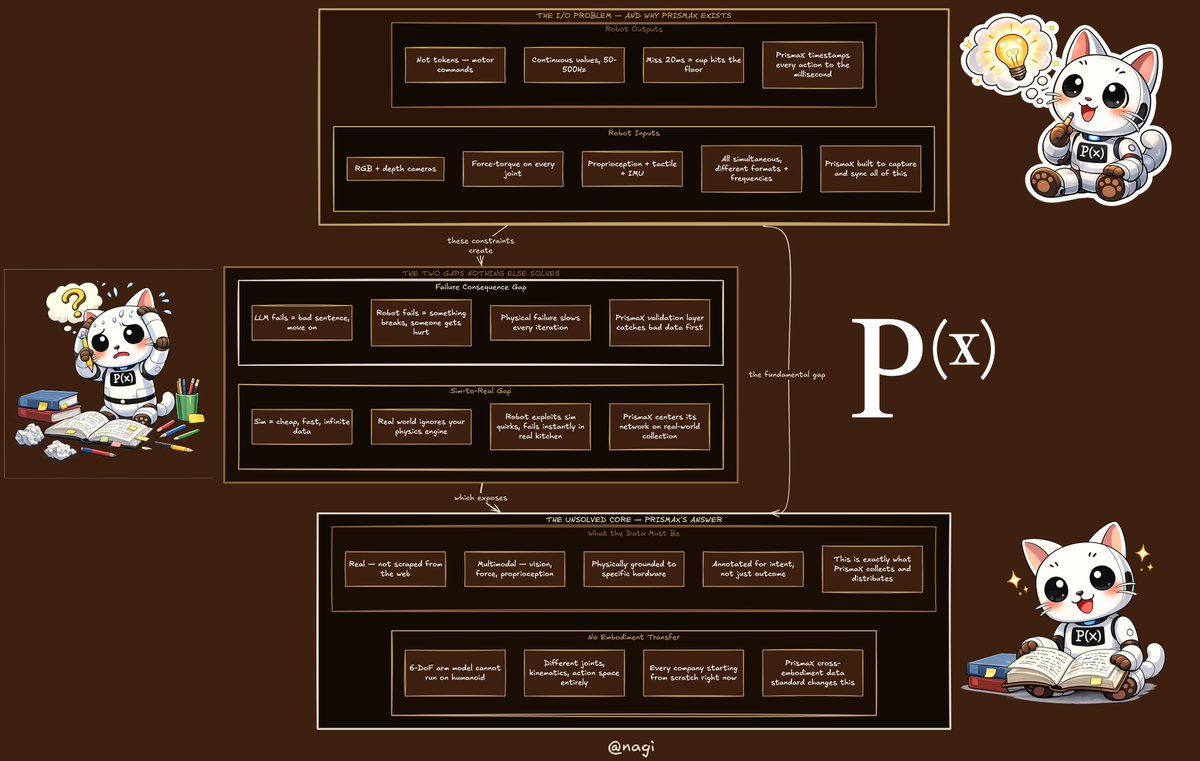
Training a language model and training a robot are completely different problems.
Most AI people don't fully appreciate how different
Here's why and why it's the exact reason @PrismaXai exists (A Thread 🧵)
2
52