
aur packages should be mandatorily namespaced by maintainer methinks.
would solve the whole orphaned package issue
74
vipin saini | Rust Developer retweeted

Slotray update 🔍🔦
→ Unverified contract? Paste the source, get the exact storage layout.
→ ERC-7201 namespaced storage now fully decoded — the slots solc won't show you
slotray.eth.limo/
1
2
32

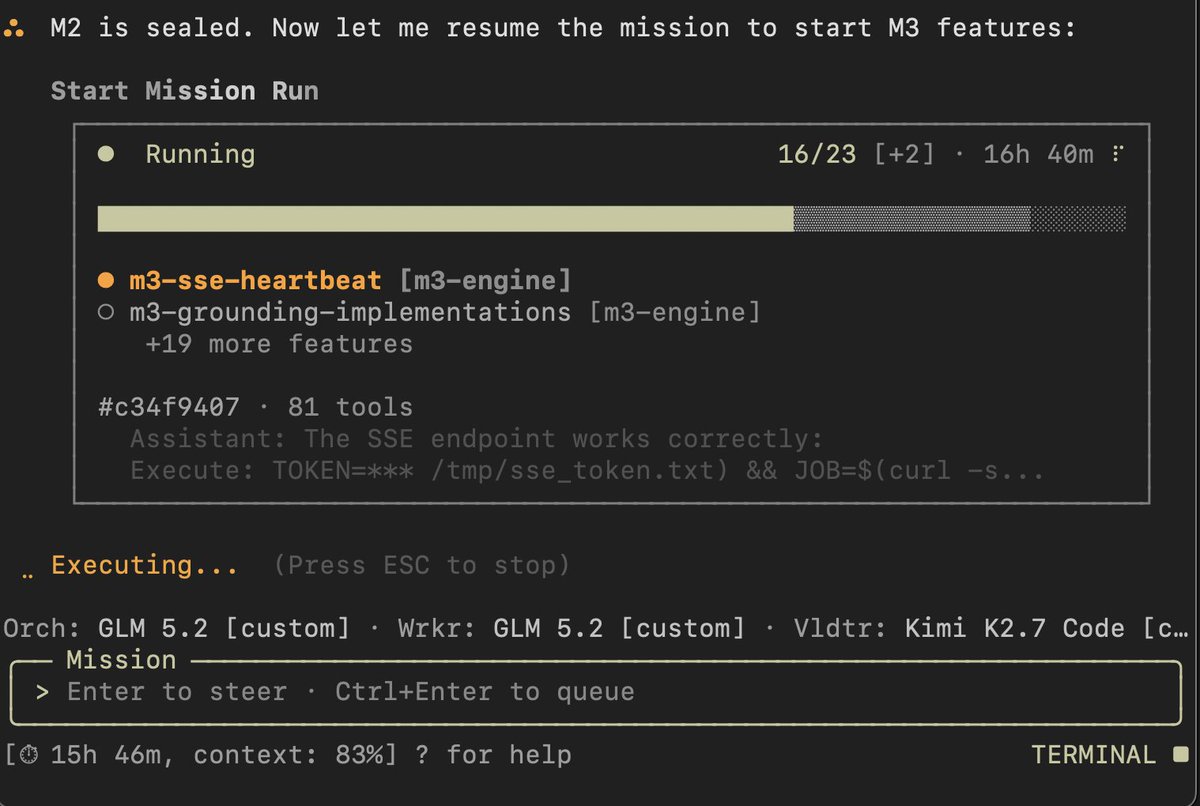
I gave two AI coding agents the same complex build. Different models, different harnesses. 15 hours later, both still working autonomously.
Claude 4.8 in CLaude Code Ultracode vs GLM 5.2 in Droid /missions mode. Same mission, same repo, same 25K-char spec.
Two different model architectures solving the same engineering problem in parallel. Watching where they diverge is the interesting part.
They are building a platform that generates differentiated, professional written output through a multi-stage LLM pipeline… synthesizing from complex intelligence inputs and contextual preparation to produce calibrated document variants across multiple product modes.
This is not a CRUD app or a chatbot wrapper. It’s a multi-stage document synthesis engine.
Pipeline architecture. The engine runs eight discrete stages. Each stage is a separate LLM operation with its own model assignment and reasoning-mode control.
The thinking mode (deep chain of thought vs. fast generation) is toggled per stage via configuration... reasoning on for the stages that need it, off for speed-critical stages.
A GroundingStrategy interface means the verification and grounding logic is swappable per use case. Different product modes reuse the same pipeline engine by changing strategy configuration, not by rewriting code.
The architecture is designed so the engine produces different categories of written output... long form reference documents, structured items, modular content blocks... from the same core by reconfiguration.
Checkpoint and resume. Generation jobs are long running. The pipeline checkpoints state so a failed or interrupted stage doesn’t burn hours of prior work. Resume from the last good checkpoint.
Async job processing. A queue backed worker architecture decouples heavy generation work from the request layer. Workers pull jobs, execute pipeline stages, and heartbeat their status. The same worker code runs locally as a process and in production as a managed container service.
What makes this hard for an agent. The agent has to internalize a 25,000-character PRD plus architecture and verification docs, decompose the build into ordered milestones, scaffold the entire infrastructure (auth, database, storage, queue, payments), wire eight LLM stages with correct model and thinking mode configs, implement the queue worker heartbeat loop, and make the whole thing run locally against real services... not mocks.
Architecture and stack
Full local first stack via Docker Compose. Every cloud dependency has a local equivalent that speaks the same protocol, so the application is fully functional during development with zero cloud accounts:
Database Auth Storage
Supabase self-hosted (real Postgres, GoTrue authentication, Row Level Security, auto generated REST API, file storage). Same as Supabase cloud, running in a container.
Object storage
MinIO (S3 compatible API). Swap the endpoint URL and the same code talks to S3 or R2 in production.
Job queue — LocalStack (SQS compatible API). Same code, different endpoint.
Payments — Stripe CLI in test mode with webhook forwarding.
Frontend — Vite dev server.
The code is identical for local and production. Only connection strings change... environment variables. Deploy means swapping localhost URLs for cloud endpoints. No code forks, no feature flags, no parallel branches.
Three process model. Frontend API async worker, all containerized, all healthchecked. Services run on non-default ports with namespaced Docker projects so multiple stacks coexist on the same machine without port or project name collisions.
Mission mode autonomous execution.
The repository is deliberately naked... just AGENTS.md (behavioral guardrails and repo hazards) and docs/ (the full specification). No workflow framework, no step by step instructions. The agent reads everything, decomposes the build into milestones, and executes. Fire and forget: start the mission, come back hours later to a working application.
The agent never blocks mid build to ask the owner for a Supabase URL, AWS credentials, or an S3 bucket... because it doesn’t need them.
Row Level Security. Multi tenant isolation is enforced at the database layer, not the application layer. One database, strict tenant boundaries, no cross contamination possible even if the application has a bug.
Cross model adversarial validation. The Droid harness supports bring your own key... any model. The build agent (GLM 5.2) and the validation agent (a different model) have fundamentally different architectures, so they don’t share blind spots. One builds, the other scrutinizes. Claude Code can only do Claude reviewing Claude. This is structurally stronger validation.
Git native. Every change the agent makes is version controlled. Auditable, reversible, diffable. You can reconstruct exactly what the agent did at any point.
Endurance as a feature. If I see how many of the milestones have been implemented now after 15 hours, I think the whole project might run for 25-30 hours, non-stop.
In Claude Code, it already had me ask a few things a few times, but it is still quite autonomous in the Ultra Code mode.
Droid definitely is more autonomous if you send it into a mission and provide it with everything that it needs.
In this case, you also have to think ahead and prepare (for example, an .env file with API keys if you wanted to do real-life tests). Essentially, anything that the agent could need should be provided.
Then, you can have it run for two or three days and create a professional, full-stack application.
Alternatively, you can sit at your computer and observe it. When you are not as well prepared, just give it what it needs in case it needs something.
We are really at the point now where an excellent harness like Droid, paired with a very capable model like GLM 5.2, can work for days and create whatever you want, as long as you describe it well enough.
Essentially, fully autonomously.
That's pretty crazy, to be honest.And it's accessible to anyone, and it doesn't even cost much.
I am not a developer. I learned what I learned just by being one of these idiots who actually read every output that the models provide during coding.
I started as a spontaneous vibecoder a while ago, things got more and more serious, and that is where I am today.
Models like Fable or the next two or three versions of GLM will make less and less knowledge necessary.
However, it will still take a while until even the best model will be able to design on its own the features that a product like the one I'm building right now needs.
I think we are still far away from that.
6
8
2,114

Jun 17
Thanks for the sharp observation! Ownership is structural in AgentNexus — every doc is namespaced by owning service, cross-service docs must live under an explicit coordination unit. We're now working on v4 with git-style sync and agent auto-onboarding via MCP.
6


built a storage slot reader for EVM contracts. reads raw slots, auto-labels EIP-1967 proxy/admin/beacon, Diamond storage, OZ5 namespaced slots. heuristic type detection. zero deps, one file.
node read.mjs 0xUSDC --known
node read.mjs 0xAny --map 20
github.com/0xAxiom/axiom-pub…
7
71



Jun 14
hardcoding config values in your app is how you debug at 3am
built a centralized config service in Go from scratch
phase 1 done:
pure in-memory store
namespaced keys
versioning rollback
next: postgres,docker,ci
Github repo link below:
1
2
40

Jun 13
OpaquePay treats AI agents as real account holders, not API keys taped to a wallet.
Each agent gets its own Solana address and an Agent ID namespaced to your account, so its balance and history stay separate and auditable.
It can pay for API calls, settle invoices, and meter usage on its own, while every transaction surfaces in your feed the moment it settles.
3
23

Jun 12
2. Core Architecture
AkmenaDiamond (Improved): Central proxy with hardened upgradeDiamond, full ERC-2535 loupe functions, two-step ownership, pausing, and EIP-8153 packedSelectors() support on all facets.
EIP-7201 Namespaced Storage isolated reentrancy guard (storage-based for Diamond compatibility).
Facets (modular, independently upgradable):
TokenFacet: ERC-20 full ERC-1363 (transferAndCall, approveAndCall) with MAX_SUPPLY cap, safe approvals, buyback & burn.
AgentFacet: Job lifecycle (Open → Funded → Submitted → Completed/Rejected/Expired), atomic funding via onTransferReceived, executeIntent with whitelist slippage protection.
ZKVerifierFacet: SP1 integration for ZK-gated job funding with composite nullifier replay protection (CEI pattern).
MemoryFacet: Tamper-evident memory anchoring per-reader access control for agent state continuity.
IntrospectionFacet: On-chain Diamond visibility for auditors and tooling.
SelectorHelper: Deployment utility for safe facet registration.
LinearVesting: Standalone immutable vesting contract for team/investors.
All facets implement packedSelectors() per EIP-8153
1
30

Jun 11
So the value of my blob helper that namespaced my blobs with project names just went to zero. But! My helper that namespaces with branch names is still red hot
2
3
22


Debug LWC failures faster. 🔍
Don't mistake a namespaced storage failure for a framework block. Master the three security layers isolating your components, learn why proxy unwrapping fails silently, and protect your cross-boundary data.
Secure your components: sforce.co/3Q8aUqI

7
671

Jun 10
Build "Mini-scribe" — an AI meeting notetaker on Claude using Minimi:
Before you paste this: you need (1) the Minimi memory connector installed and your laptop online, and (2) an environment that can create live artifacts (e.g. Claude Cowork). A strong model helps — this is a one-pass build. Paste everything below this line.
Build me a live artifact called Mini-scribe — a Granola-style AI meeting notetaker that runs entirely on my Minimi memory. It's a self-contained, light-mode HTML page (inline all CSS/JS, :root{color-scheme:light}) that pulls fresh from Minimi each time it opens. Brand it "Mini-scribe · built with Minimi". Design: off-white background, dark text, green accent; sidebar main panel. Don't build a page-reload button (the artifact header has one).
Use my Minimi tools via window.cowork.callMcpTool(...): meeting_memory (actions list, get_context), list_active_threads, and search_memory. Use window.cowork.askClaude(prompt, data[]) for all AI generation.
Probe first. Before coding, call each tool once and build parsers around the ACTUAL responses — Minimi returns markdown, not JSON. Expect these shapes (verify them yourself):
Every response may start with an italic line _User local time: ... (timezone)._ — skip it.
meeting_memory list → ### N. Title blocks with - **App:**, - **Thread ID:** (UUID), and — only for real calls — - **Started:** (ISO UTC) - **Duration:** ("1 min", "1 hr 5 min"). Plain chat threads appear in the same list WITHOUT Started/Duration. time_range accepts {day:"YYYY-MM-DD"}; limit caps at 20.
meeting_memory get_context → ## Title, the same fields, then ### Transcript with the transcript inside a ``` code fence. Lines are tagged [You] / [Others]. The ASR is noisy: mixed English Hindi, garbled words, and the same sentence often ECHOED on both speakers' lines.
list_active_threads → ### N. App / ThreadName blocks with - **Last updated:** - **Preview:**. Thread names can be URLs — split app/name on the FIRST " / " only. Takes time_range:{from,to} in epoch ms.
search_memory → ### Result N blocks with - **Source:** App / Name, - **Captured:**, optional - **Memory:** gist, and a - **Context:** code fence. time_range supports {day, between:{from:"HH:MM", to:"HH:MM"}} — between cannot cross midnight, so split windows that do.
Read results defensively: r.structuredContent ?? JSON.parse/r.content[0].text style, tolerate missing fields.
Requirements
Calls only. Keep a meeting only if it has BOTH a start time AND a non-zero duration. Exclude plain chat threads; drop 0-minute recordings.
Beat the 20-item cap. Recent chats bury older calls in list. Fetch one day at a time ({day:"YYYY-MM-DD"}, limit 20) across the window, with a small concurrency pool; dedupe by thread ID; sort newest-first.
Load-more paging. Start with the last 10 days. A "Load 10 more days" button fetches the next 10-day window and appends, showing days loaded. A whole window with no new calls → "No more calls", stop — but NEVER treat an offline response as "ended" (see 9).
Group-by switcher in the sidebar (top of the drawer, full-width tabs): Date (default, Today/Yesterday separators), People, App, Theme. Theme = 1–2 word category from one AI pass over titles. Resolve People/Theme lazily on first select with a progress state; cache in localStorage.
Per-call notes fused with screen context. On open: fetch the transcript AND screen context via search_memory (query = call title, window ≈ 5 min before start → 90 min after end, midnight-split). Pass BOTH to askClaude; demand STRICT JSON: {summary, keyPoints[], actionItems[{who,task}], decisions[], followUps[], resources[{label,url}], related[{name,note}]}. Instruct it to: use screen context to fix garbled transcript terms (names, companies, numbers → the on-screen spelling); weave genuinely related on-screen activity into the summary; capture follow-ups that already happened right after the call; drop unrelated tabs. Render Granola-style; Follow-ups/Resources(clickable)/Related sit behind a persistent show/hide "screen context" toggle. Cache notes per thread in localStorage; add "Regenerate". Parse the AI reply leniently (strip fences, first-{-to-last-}, retry once).
Transcript tab with color-coded [You] vs [Others] bubbles, plus:
⧉ Copy — copies the visible version with a title/date header and real speaker names. Make it sandbox-proof: try a synchronous hidden-textarea execCommand("copy") INSIDE the click gesture first, then navigator.clipboard, and if both are blocked open a modal with the text pre-selected for ⌘C.
✨ Enhanced view (Raw | Enhanced toggle) — an AI cleanup pass fed the transcript screen context the notes summary: correct mis-heard words to on-screen spellings, merge/drop echoed duplicate lines (attribute each sentence to the actual speaker), fix punctuation/casing, keep Hindi as Hindi, never invent or summarize. Output plain [You]/[Others] lines. Chunk long transcripts on line boundaries (~6k chars) with progress; validate output (tags present, ≥25% of input length; one retry) and never overwrite a good transcript with garbage. Cache per thread; offer Redo.
✎ Fix words — user-editable corrections for mis-transcribed words (names, companies, products — e.g. "Shrum → Shram"), scoped per-call or all-calls, persisted, removable. Case-insensitive with Unicode word boundaries (Devanagari-safe, must not corrupt longer words). Apply display-time to titles, every notes section, both transcript views, copies, and chat answers (instantly, even cached ones), and to everything sent to the AI — but never to the user's own typed questions or URLs.
Ask tab — chat that answers questions from ONLY the selected call's transcript via askClaude, with brief Q&A history.
Participant identification ("With: ___"). Blend three signals: (a) greeting/vocative in the opening lines, English or Hindi ("Hey Sara", "हां, आर्यन") — strong; (b) a contact's personal DM thread active around the call via list_active_threads (~10 min before → 75 min after) — ignore group chats, channels, and web/app entries; (c) the title. Greeting matching a thread name = high confidence; voice notes with no counterpart = "—". Show an editable "With: name · source" line; manual edits persist in localStorage and override the AI. The People grouping must use this resolved participant and read transcripts (batch: fetch transcripts with a pool, then ONE askClaude call for all unresolved calls).
Offline handling. Minimi is local-only: when the laptop is asleep/offline its tools return text like "device is not currently connected / must be running and online". Detect that (regex on response text), show a "laptop offline" banner with Try-again wired to retry the failed operation, and never mark the list ended or show a false empty state because of it.
In-app ↻ refresh — re-queries the last ~3 days, merges without losing loaded history, spin state " N new" / "Up to date" flash.
Hide calls. Hover ✕ on a sidebar item hides it (persisted); footer shows "N hidden" which toggles revealing them dimmed with an ↩ unhide button; hidden calls are excluded from groups, counts, and AI passes; handle the "everything hidden" state.
Sidebar chips: per-app colored dot app name time duration ( participant when known).
Engineering bar. One <script>, no external libraries, event delegation (artifact CSP-friendly), escape all injected text, all caches namespaced in localStorage with try/catch, transcripts cached in memory only. Before publishing: extract the JS, syntax-check it (e.g. node --check), and unit-test the markdown parsers against the real probed outputs.
Finally: publish it as an artifact, listing only the three Minimi tools you actually called.Progress10 of 10Probe Minimi tools to capture actual response shapesBuild Scribe HTML artifact with all featuresVerify JS parses and publish artifactAdd transcript copy AI-enhanced transcript viewAdd hide/unhide for callsAdd name-fix (find/replace) for transcriptsGeneralize to word fixing across title, notes, chatMake transcript copy bulletproof in the sandboxMove group-by switcher into the sidebarWrite shareable build-prompt for Mini-scribeWorking foldermini-scribe-prompt.mdscribe.htmlContextConnectorsminimi
2
1
45
6,915





Jun 4
Small update as we prepare our first content drop this month:
• Drops are now called Drafts
• No more 24h expiration for logged-in users
• Unlimited Drafts for Pro users
• Namespaced registries limit increased 2× (up to 25 for Pro Founder)
More coming soon ✌️
2
1,912