
@KiiChainio has been relatively quiet on major new announcements, with most recent activity consisting of community engagement, replies, and motivational/educational comments on broader crypto topics.
Key Highlights from the Past Week:
Ongoing Ambassador Program: On June 6, they shared the Provisional Ambassadors Leaderboard.
The first reward cycle closes in about 2 weeks active participants earn points through content creation, engagement and platform activity. Applications are open for those wanting to join.
Recent Partnership Momentum: From June 10 they announced a partnership with @OneBalance_io
This integrates OneBalance into KIIEX, brings dev support for builders and includes joint community promotion.
Project Status (Ongoing)
@KiiChainio v3 Beta is Live, Users can access on chain FX trading, instant cross border payments and related features via the app pay.kiichain.io
The project focuses on stablecoins, RWAs, and emerging markets finance with a hybrid matching engine and ecosystem partnerships.
Testnet activity (Oro rewards, quests) continues, with community contributions like SDKs, explorers, and tutorials highlighted on their site.
@imdavco
1
1
44

Jun 12
The best infrastructure is the infrastructure users never have to think about.
There's a difference between multi-chain support and true usability.
Many platforms already support multiple chains:
→ multiple integrations
→ multiple balances
→ multiple execution paths
But from a user's perspective, the complexity still exists.
They still need to think about networks.
They still need to manage assets across ecosystems.
They still need to understand what's happening behind the scenes.
OneBalance takes a different approach.
Instead of simply supporting multiple chains, it abstracts them away—allowing users to interact with applications without constantly worrying about where assets live or which network powers the transaction.
Because great UX isn't about exposing complexity.
It's about making complexity invisible.
Do you think crypto reaches mainstream adoption before chain management becomes completely invisible?
@OneBalance_io #Web3 #DeFi

3
8

I've been running my own knowledge base for AI agents for months now. Markdown files, mostly. It works great right up until your data stops being clean and small.
Real data isn't clean or small. It's scattered across Notion, Linear, Slack, call transcripts, and half of it contradicts the other half. Dumping all of it into a bigger context window and hoping the model finds the needle doesn't actually work - a bigger haystack isn't an easier search. The retrieval is the hard part, and that's not what the model is built to do.
So it was good timing to see @DeytaHQ come out of stealth this week with Khora. It's an open-source library for giving agents durable memory: it pulls in messy multi-source data, builds a knowledge graph plus vector store under the hood, and routes each query to whatever retrieval actually fits. Hybrid GraphRAG, you bring your own database.
What makes me want to test it: it's solving the exact problem I keep hand-rolling at OneBalance and in my own setup. Connecting facts a human would naturally connect in their head, so the agent reasons over real knowledge instead of a pile of text.
It also helps that I know the people behind it. I worked with @MiljanTekic at Tenderly, where he was a co-founder, so I've seen how he builds dev tooling up close. His co-founder Igor Bogicevic is a serial entrepreneur - he co-founded Seven Bridges (genomics data) and Orgnostic (people analytics, later acquired by Culture Amp). The through-line across all three companies is making messy, heterogeneous data usable. That's a good track record to bet on this problem.
I'll put it head to head with my markdown memory and report back. If you're building long-horizon agents, it's worth a look.
1
2
151

Hey @DHannum8 We are. We built the teams at Euphoria, onebalance, near, fhenix, startale and mamy more.
Testimonials and case studdies can be found here: nodevector.com
Would be great to have a call
1
7
577
Jun 7
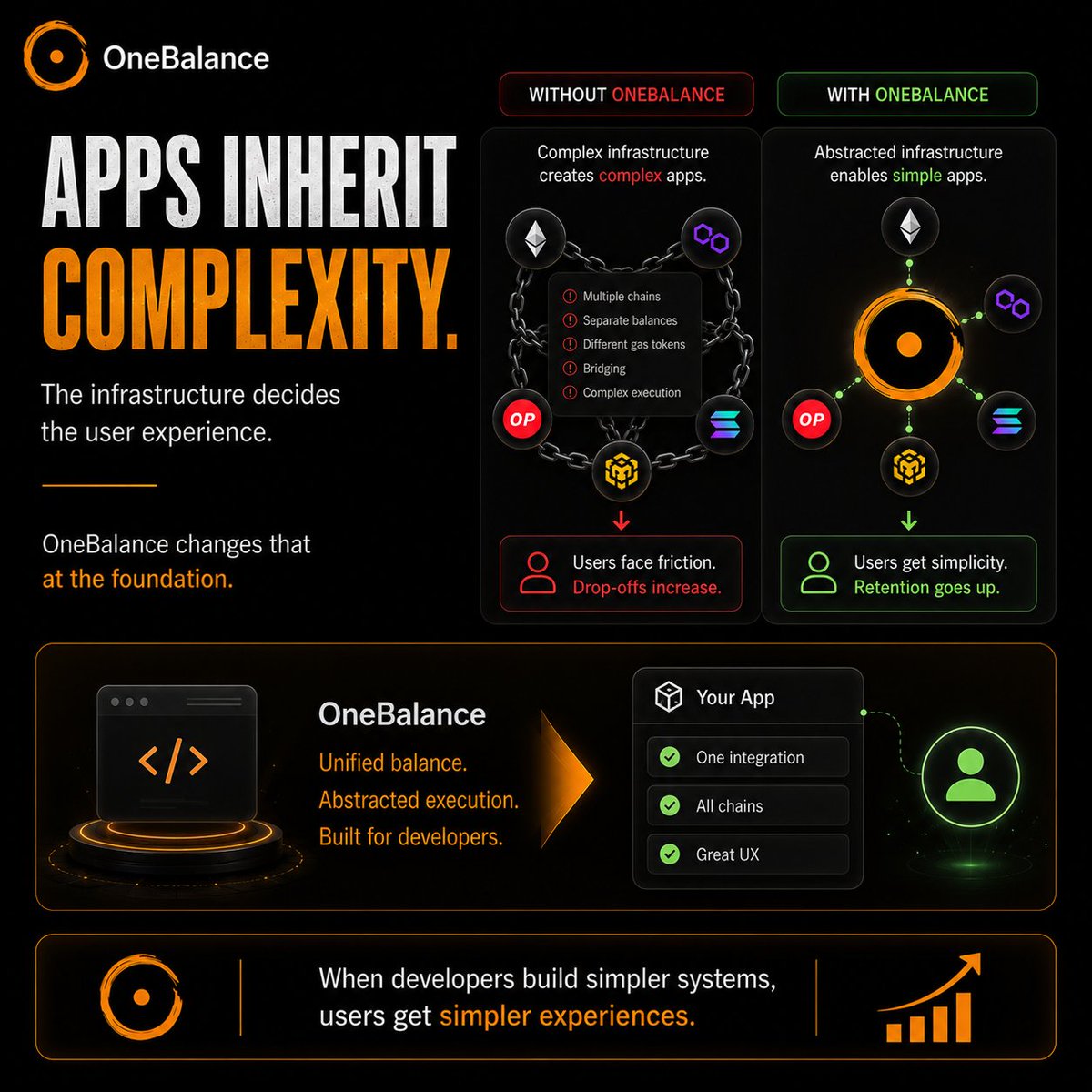
There’s a reason many Web3 apps still feel complicated.
They inherit the complexity of the systems they’re built on.
Multiple chains.
Separate balances.
Different execution environments.
OneBalance changes that at the foundation.
By unifying balances and abstracting execution across EVM chains and Solana, it gives developers a cleaner layer to build on.
And when developers build simpler systems - users get simpler experiences. @OneBalance_io
1
6
20
Jun 5
Every dApp wants a seamless user experience.
But most are limited by what the underlying infrastructure allows.
That’s the bottleneck.
OneBalance introduces a different approach:
Give developers a way to build apps where users don’t deal with chains, gas, or fragmented balances.
Through chain abstraction and unified execution, complexity is handled behind the scenes not pushed to the user.
Because great UX shouldn’t depend on how many chains you support.
@OneBalance_io

5
28

Jun 1
My Drop Diary
🔥 Biggest Loss - OneBalance is closing OneApp.
All users must withdraw funds before June 30th, after which the project will stop working.
Link: app.onebalance.io/
Support: support@onebalance.io
Despite raising $25M, the team couldn’t make it work. Very unfortunate.
🔥 Actions:
• Metamask released a new SBT in collaboration with Franky The Frog.
Claim it in the Rewards tab or here: frankythefrog.com/metamask-m… (Ethereum)
• Hypernova (prop firm) opened registration.
Recently raised $3M from MS Holdings and Lemniscap.
Apply here: hypernova.xyz/
• OpenSea extended zero commissions on the platform.
Volume didn’t change dramatically, but it’s still a nice move.
🧠 Thoughts:
Over the weekend I recharged my batteries with positive emotions (thanks to the alpacas).
Ready to face a new week in combat mode. Let’s not be lazy, guys - let’s work.
Today there will be an interview with an interesting person who got into crypto thanks to Notcoin, actively farms Discord roles and has already created his own product.
Have a wonderful day, everyone ☀️
What are you withdrawing or farming right now? Share in replies 👇

27
63
749
May 31
Most people talk about improving crypto UX.
But UX doesn’t improve on the surface but at the infrastructure level.
That’s where OneBalance is focused.
Instead of expecting every app to solve:
• bridging
• gas management
• cross-chain execution
OneBalance provides a toolkit that abstracts these challenges at the protocol level.
So developers don’t rebuild the same solutions again and again.
Better infrastructure → better applications → better user experience.
That's a perfect definition of @OneBalance_io

1
5
24

May 31
RECAP Tháng 5/2026 của @zerion
Không có airdrop lớn.
Không có campaign XP mới.
Nhưng tháng 5 lại cho thấy rất rõ Zerion đang xây cho điều gì tiếp theo:
🤖 AI Agents sẽ cần ví.
Và Zerion đang từng bước xây dựng hạ tầng cho tương lai đó.
Đây là những cập nhật đáng chú ý nhất trong tháng 5 👇
🤖 Ra mắt Zerion CLI
Biến AI agents thành crypto-native với khả năng theo dõi portfolio, swap, bridge và ký giao dịch trên 40 chains cùng @solana.
🔌 Mở rộng hệ sinh thái API
Hỗ trợ migrate từ Dune SIM và OneBalance, giúp builders truy cập dữ liệu on-chain dễ dàng hơn mà không cần tự xây hạ tầng.
🌉 Wallet ngày càng mạnh hơn
Tích hợp @lifiprotocol để cải thiện trải nghiệm cross-chain swaps và bridging ngay trong ứng dụng.
⚠️ Zero Network chính thức sunset
Zerion quyết định tập trung toàn lực vào Wallet và API. Nếu bạn còn tài sản trên Zero, hãy rút trước 31/07/2026.
🎙️ Nhiều buổi Zerion Live xoay quanh AI x Crypto với các khách mời từ MoonPay, Solana, Polymarket và Coinbase, bàn về tương lai của agent payments và crypto-native AI.
Điều mình thấy thú vị nhất là Zerion đang đặt cược rất lớn vào tương lai nơi AI agents không chỉ đọc dữ liệu blockchain mà còn có thể tương tác trực tiếp với nền kinh tế on-chain.
Nếu bạn chưa thử, đây là thời điểm tốt để tải Zerion và trải nghiệm một trong những ví crypto có UI/UX tốt nhất hiện nay. 📱
Bạn ấn tượng nhất với cập nhật nào của Zerion trong tháng 5?
17
1
29
3,623
May 29
Holding gas tokens across multiple chains is one of the most overlooked UX problems in crypto.
You’re forced to:
• maintain balances on different networks
• keep track of fee tokens
• constantly rebalance
It’s inefficient—and confusing for most users.
OneBalance removes that requirement.
With a unified balance and abstracted execution, users can transact without managing gas on every chain.
Less overhead.
More clarity.
Better experience.
Interesting. @OneBalance_io

3
1
7
46

May 28
100 KÈO CRYPTO ĐÁNG CHÚ Ý NHẤT 2026 👀
⭐ S TIER / narrative mạnh nhất
Arc
Polymarket
Kalshi
Base
Tempo
Dango
⚡ A TIER / Đáng theo dõi
Variational
Extended
Nado
PredictFun
Robinhood
LitVM
Abstract
Ink
KAST
Ethos
Ethereal
Hibachi
GRVT
Pacifica
Myriad
⚡ B TIER / Tạm
Bulk
Liquid
Carbon
Bullpen
Hyena
DreamCash
01
Noise
Nous Research
Minara
Axis Robotics
Mahojin
Canopy
Oro AI
GenLayer
Fhenix
Shelby
Seismic
🟧 C TIER / Narrative vừa phải
MegaETH
Jumper
Relay
Katana
Titan
TradeXYZ
Ostium
Vest Exchange
RiseX
HotStuff
Satori
Novig
SX Bet
XO Market
D3
KiiChain
June
PrismaX
Pond
🟥 D TIER / conviction thấp
Project X
Drip
SpiceNet
DAWN
OneBalance
N1
TYB
Cerebro
Ritual
Fermah
Euphoria
Apyx
Sphinx
Miden
Renais
Surf
Fableborne
Opinion
Quaranium
Superposition
Fraction AI
Bullshot
Hylo
Oshi
Cashmere
Octra
Perena
Squads
Jiritsu
Offline Protocol
Squid

24
7
42
2,938

May 26
100 Dự án airdrop đáng cày 2026
Kèo thì vẫn còn rất nhiều, chủ yếu kèo ae chọn là kèo nào thôi nhé ae
Làm 2-3 dự án thôi,đừng cái gì cũng ham mà làm qua loa thì móm sạch nhé
Tier cao chưa chắc đã tốt, làm tier thấp mà ít người fomo, dc rank cao thì nhiều khi lại ngon hơn
⭐ S TIER - Highest Attention / Strongest Narratives
Arc
Polymarket
Kalshi
Base
Tempo
Dango
🔥 A TIER - Strong Ecosystems / High Potential
Variational
Extended
Nado
PredictFun
Robinhood
LitVM
Abstract
Ink
KAST
Ethos
Ethereal
Hibachi
GRVT
Pacifica
Myriad
⚡ B TIER - Solid Projects
Bulk
Liquid
Carbon
Bullpen
Hyena
DreamCash
01
Noise
Nous Research
Minara
Axis Robotics
Mahojin
Canopy
Oro AI
GenLayer
Fhenix
Shelby
Seismic
🟧 C TIER - Mid Attention / Early Ecosystems
MegaETH
Jumper
Relay
Katana
Titan
TradeXYZ
Ostium
Vest Exchange
RiseX
HotStuff
Satori
Novig
SX Bet
XO Market
D3
KiiChain
June
PrismaX
Pond
🟥 D TIER - More Speculative / Lower Conviction
Project X
Drip
SpiceNet
DAWN
OneBalance
N1
TYB
Cerebro
Ritual
Fermah
Euphoria
Apyx
Sphinx
Miden
Renais
Surf
Fableborne
Opinion
Quaranium
Superposition
Fraction AI
Bullshot
Hylo
Oshi
Cashmere
Octra
Perena
Squads
Jiritsu
Offline Protocol
Squid

57
17
124
10,365

🪂 2026 FARMING TIER LIST
(or a guide on where CT will spend 14 hours/day for imaginary points)
━━━━━━━━━━━━━━━
S TIER — “touch this or regret later”
━━━━━━━━━━━━━━━
• base → probably the safest long-term ecosystem bet
• Dango → community already acting like allocation confirmed
• Polymarket → prediction market meta still alive
• Tempo → lowkey getting strong CT attention
• Arc → one of the cleanest narratives rn
• Kalshi → normie adoption political/event trading hype
These are the projects where people farm even without confirmed rewards because “the vibes are enough.”
━━━━━━━━━━━━━━━
A TIER — “serious grinders only”
━━━━━━━━━━━━━━━
• GRVT → perpetuals strong backers
• PredictFun → gambling addiction but make it web3
• Ink → ecosystem still early enough
• Pacifica → slowly building cult following
• Variational → smart money watching
• Hibachi → one CT thread away from exploding
• Robinhood → if they push harder into crypto, farmers entering instantly
• Myriad → attention increasing quietly
• KAST → everyone farming but nobody explaining it properly
• Extended → solid infra narrative
• Ethos → feels early
• LitVM → BTC ecosystem gamblers arrived
• Abstract → strong branding community
• Ethereal → “potential” carrying hard rn
• Nado → sleeper pick for role grinders
This is the tier where people say:
“bro it’s still early.”
It’s never early anymore.
━━━━━━━━━━━━━━━
B TIER — “farm and hope”
━━━━━━━━━━━━━━━
• Fhenix → privacy narrative always survives somehow
• Axis Robotics → AI robotics = automatic engagement bait
• Bulk → decent but CT attention inconsistent
• Shelby → random pump possibility
• DreamCash → sounds bullish enough
• Mahojin → anime pfp community incoming
• Canopy → quietly building
• Carbon → survived longer than expected
• Noise → fitting name because timeline full of it
• Liquid → drama generated more attention than marketing
• Nous Research → AI narrative carrying
• Hyena → either huge or forgotten in 2 months
• Minara → still seeing grinders around it
• GenLayer → strong concept, execution TBD
• Bullpen → farmers lurking silently
• Seismic → survived multiple “next big thing” cycles
• 01 → mysterious projects always farm engagement
• Oro AI → AI logo = automatic watchlist entry
This is the “bookmark and forget until TGE” tier.
━━━━━━━━━━━━━━━
C TIER — “I interacted once”
━━━━━━━━━━━━━━━
• Vest Exchange
• KiiChain
• Titan
• TradeXYZ
• Relay
• HotStuff
• Pond
• SX Bet
• MegaETH
• Katana
• PrismaX
• XO Market
• Novig
• RiseX
• June
• Ostium
• D3
• Jumper
• Satori
These projects are held together by:
Discord XP systems
mysterious docs
“big announcement soon”
and one influencer saying “don’t fade this”
━━━━━━━━━━━━━━
D TIER — “future retrospective thread projects”
━━━━━━━━━━━━━━
• Surf
• Fermah
• Fraction AI
• Project X
• Bullshot
• Drip
• Cashmere
• Offline Protocol
• Apyx
• Euphoria
• DAWN
• Renais
• SpiceNet
• Opinion
• TYB
• Squid
• OneBalance
• Jiritsu
• Ritual
• Perena
• Fableborne
• Quaranium
• Superposition
• Sphinx
• Hylo
• Cerebro
• Oshi
Potential outcomes:
2 projects become huge unexpectedly
8 disappear silently
11 delay TGE 4 times
rest pivot to AI
━━━━━━━━━━━━━━━
reward after 9 months:
$23.41 PTSD
DISCLAIMER - NEVER LOVE A PROJECT.

12
2
22
601

May 25
【目前值得撸的空投项目都在这了,今年是暴富还是暴负?】
2026年最值得埋伏的 100 加密项目空投终极矩阵!
🟢 S 级:殿堂级标的(全球焦点 / 最强核心叙事)
预测市场与主权链:Arc、Polymarket、Kalshi、Base
核心协议:Tempo、Dango
🟡 A 级:超一线生态(强劲基本面 / 爆发潜力无限)
Variational、Extended、Nado、PredictFun、Robinhood(Web3生态)、LitVM
Abstract、Ink(核心Layer2)、KAST、Ethos、Ethereal、Hibachi、GRVT、Pacifica、Myriad
🔵 B 级:中坚支柱(稳健基本面 / 核心防御资产)
Bulk、Liquid、Carbon、Bullpen、Hyena、DreamCash、01、Noise
AI与硬核科技:Nous Research、Minara、Axis Robotics、Mahojin、Canopy、Oro AI、GenLayer
Fhenix、Shelby、Seismic
🟠 C 级:新星黑马(中等热度 / 极早期高爆生态)
MegaETH(超高性能L2)、Jumper、Relay、Katana、Titan、TradeXYZ、Ostium、Vest Exchange、RiseX
HotStuff、Satori、Novig、SX Bet、XO Market、D3、KiiChain、June、PrismaX、Pond
🔴 D 级:极致投机(高贝塔博弈 / 低确信度高赔率)
Project X、Drip、SpiceNet、DAWN、OneBalance、N1、TYB、Cerebro、Ritual、Fermah、Euphoria、Apyx、Sphinx、Miden、Renais、Surf、Fableborne、Opinion、Quaranium、Superposition、Fraction AI、Bullshot、Hylo、Oshi、Cashmere、Octra、Perena、Squads、Jiritsu、Offline Protocol、Squid

65
33
59
7,855

🪂 Best Projects to Position Early for 2026
🟦 S TIER
-Base
-Dango
-Polymarket
-Tempo
-Arc
-Kalshi
🟩 A TIER
-GRVT
-PredictFun
-Ink
-Pacifica
-Variational
-Hibachi
-Robinhood
-Myriad
-KAST
-Extended
-Ethos
-LitVM
-Abstract
-Ethereal
-Nado
🟨 B TIER
-Fhenix
-Axis Robotics
-Bulk
-Shelby
-DreamCash
-Mahojin
-Canopy
-Carbon
-Noise
-Liquid
-Nous Research
-Hyena
-Minara
-GenLayer
-Bullpen
-Seismic
-01
-Oro AI
🔷 C TIER
-Vest Exchange
-KiiChain
-Titan
-TradeXYZ
-Relay
-HotStuff
-Pond
-SX Bet
-MegaETH
-Katana
-PrismaX
-XO Market
-Novig
-RiseX
-June
-Ostium
-D3
-Jumper
-Satori
🟥 D TIER
-Surf
-Fermah
-Fraction AI
-Project X
-Bullshot
-Drip
-Cashmere
-Offline Protocol
-Apyx
-Euphoria
-DAWN
-Renais
-SpiceNet
-Opinion
-TYB
-Squid
-OneBalance
-Jiritsu
-Ritual
-Perena
-Fableborne
-Quaranium
-Superposition
-Sphinx
-Hylo
-Cerebro
-Oshi

18
16
39
3,518

May 24
100 CRYPTO PROJECTS WORTH FARMING IN 2026 👀
⭐ S TIER — Highest Attention / Strongest Narratives
Arc
Polymarket
Kalshi
Base
Tempo
Dango
🔥 A TIER — Strong Ecosystems / High Potential
Variational
Extended
Nado
PredictFun
Robinhood
LitVM
Abstract
Ink
KAST
Ethos
Ethereal
Hibachi
GRVT
Pacifica
Myriad
⚡ B TIER — Solid Projects
Bulk
Liquid
Carbon
Bullpen
Hyena
DreamCash
01
Noise
Nous Research
Minara
Axis Robotics
Mahojin
Canopy
Oro AI
GenLayer
Fhenix
Shelby
Seismic
🟧 C TIER — Mid Attention / Early Ecosystems
MegaETH
Jumper
Relay
Katana
Titan
TradeXYZ
Ostium
Vest Exchange
RiseX
HotStuff
Satori
Novig
SX Bet
XO Market
D3
KiiChain
June
PrismaX
Pond
🟥 D TIER — More Speculative / Lower Conviction
Project X
Drip
SpiceNet
DAWN
OneBalance
N1
TYB
Cerebro
Ritual
Fermah
Euphoria
Apyx
Sphinx
Miden
Renais
Surf
Fableborne
Opinion
Quaranium
Superposition
Fraction AI
Bullshot
Hylo
Oshi
Cashmere
Octra
Perena
Squads
Jiritsu
Offline Protocol
Squid

32
46
217
21,355
May 24
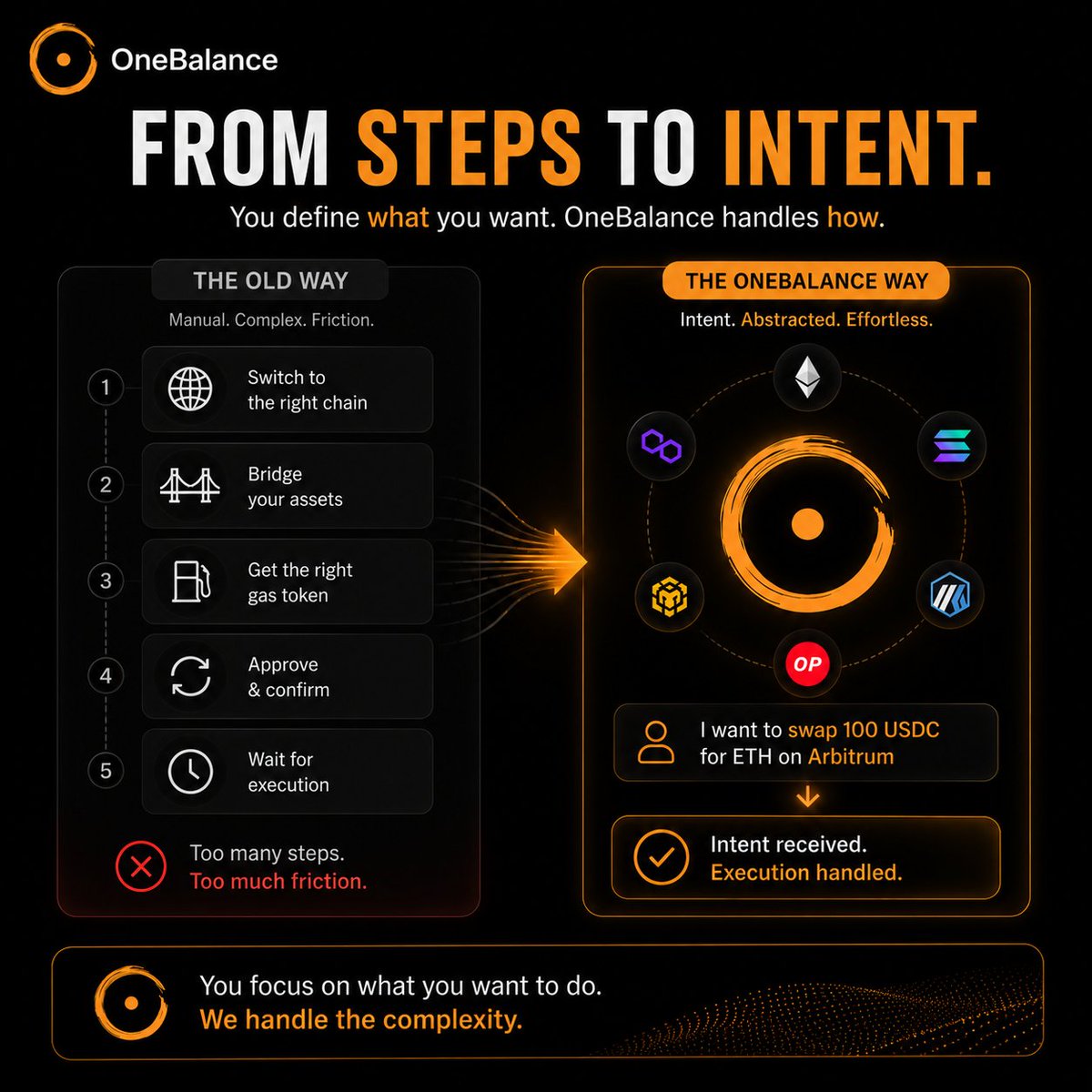
Think about how people want to use crypto:
“I want to send funds.”
“I want to swap assets.”
“I want to interact with an app.”
Not:
→ bridge here
→ switch network
→ fund gas
→ retry transaction
OneBalance introduces an intent-based model.
You define what you want to do—and the system handles how it gets executed across chains.
That shift—from manual steps to intent-driven execution—is where real usability begins.
@OneBalance_io
5
25
May 22
One of the most silent frictions in crypto:
Gas.
Before doing anything, users have to ask:
→ Do I have the right token for fees?
→ Am I on the right chain?
→ Should I swap first just to pay gas?
This is not a feature. It’s friction.
OneBalance abstracts gas entirely.
Users don’t need to manually manage gas tokens across chains—the system handles execution behind the scenes.
Because paying to *use* a system shouldn’t require understanding its infrastructure.
@OneBalance_io

6
40
May 20
Most multi-chain experiences today are just multiple single-chain experiencesstitched together.
That’s why users still feel the friction.
OneBalance approaches it differently.
Instead of exposing the complexity, they abstract it:
• balances are unified
• execution is handled behind the scenes
• chains become invisible to the user
Supporting both EVM chains and Solana under one system is not just integration. It's coordination.
And that’s where better UX actually begins.
@OneBalance_io

1
6
33

May 20
🟡oneBanking is an AI-native finance in one app.
There Airdrop is coming up soon start here 👇🏿
🌐 quests.onebanking.app/loyalt…
✅Connect EVM wallet (OKX, METAMASK, RABBY)
✅Connect X and receive 50 points 1.2X multiplier
✅Complete task ( Follow on X)
✅Connect Discord (Join OneBalance Discord channel)
✅Make tweet daily about Onebalance submit link earn points
✅Done (Be active on Discord)

2
151