
Tathagata M. retweeted

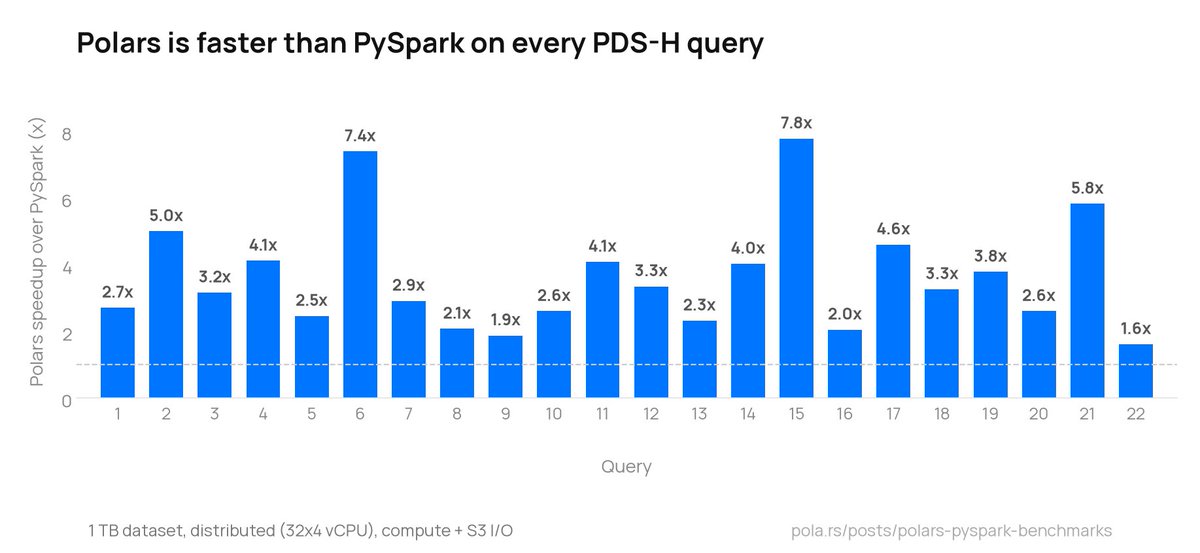
Distributed Polars is up to 7.8x faster than Spark on the PDSH benchmark, averaging to a 3x speedup on all queries.
We ran the PDS-H benchmark (TPC-H derived, 1 TB-scale dataset) against PySpark 4.0.1 on two setups.
- Distributed (32 × 4 vCPU workers): Polars averaged 3.2x faster, ranging from 1.6x to 7.8x per query.
- Single node (128 vCPUs, same total resources): Polars averaged 6.4x faster, with one query finishing 38x quicker.
Read the full benchmark post here: pola.rs/posts/polars-pyspark…
4
22
921

Julian Morrow retweeted

Écrivain de polars remarquable.
May 27

RIP Robert Daley, Writer/Publicist, Police Officer
NYPD
Publicity Director for the New York Giants
The New York Times
Novels adapted to Film:
Prince of the City, Year of the Dragon
Tainted Evidence (Film: Night Falls on Manhattan)
#InMemoriam #RIP




2
1
9
614
Annie Larche retweeted

Jun 15
Nicolas Demorand raconte comment il a réussi à “renouer avec le plaisir” grâce à la lecture de polars, sous les bons conseils du journaliste Philippe Lançon, qui marque le début de sa sortie de la dépression.
➡️ radiofrance.fr/franceinter/p…
5
28
116
19,498

que els introdueixin vestits amb uniformes polars

I qui dia passa, any empeny.
Aquest és el #TOP10 de la vergonya d'ahir.
Ara comencen a obrir els centres educatius i podeu veure totes les temperatures en directe al mapa:
aulesquecremen.cat/mapa
Fins on arribarem avui?

15



Fa sol! No tant fort com a la zona equatorial ni tan fluix com als cercles polars.
4

J-2 ! Si vous aimez les polars et la politique LA CAMPAGNE ENSANGLANTÉE est pour vous. Idéal pour l’été et la plage #polar #politique #crime
19
I AM BIG DEER 🦌 retweeted

30 Oct 2024
New videos of hands-free smelling Santa bears man hole are up on onlyfans.com/bearsorlando polars bears in their natural habitat @stephen39399324
8
159
1,125
158,116

but that just moves you along the software chain, surely someone will pop into say 'Python/Pandas' then someone else will pop in to say "well akchully Polars..."
xkcd.com/378/
Meanwhile I used Gretl for my MSc panel data and it was a perfectly cromulent software :)
1
26