
Open source should not become closed. A typo fix from a newcomer should still be easy. But a parser change in critical infrastructure should not get the same treatment. Friction should scale with: 1. contributor trust distance 2. contribution criticality
8


Engine core:
🐋 DeepSeek-V4: sparse MLA metadata decoupled from V3.2, a TRTLLM-gen attention kernel, EPLB for the Mega-MoE, selective prefix-cache retention for sliding-window KV, and detached from torch.compile
🛠️ Model Runner V2: now the default for Llama Mistral dense models (joining Qwen3), plus a FlashInfer sampler, breakable CUDA graphs, PP bubble elimination, and Gemma 4 MTP
🔌 Unified parser: reasoning and tool-call parsing now sit behind a single Parser.parse(); the Responses parser moved onto it
💾 Multi-tier KV cache offloading: an object-store secondary tier, HMA on by default for capable connectors, and a per-request offloading policy
1
3
407
vLLM v0.23.0 is out! 408 commits from 200 contributors (63 new). 🎉
Highlights: DeepSeek-V4 matures across backends (TRTLLM-gen attention kernel, sparse MLA decoupled from V3.2, EPLB for the Mega-MoE), Model Runner V2 now default for Llama Mistral dense models, Gemma 4 Unified (encoder-free) MTP, a maturing Rust frontend, multi-tier KV cache offloading with an object-store tier, and a unified reasoning tool-call parser.
Thread 👇

4
7
63
4,860

AI半導体投資日報_260615_昼刊
■昼刊の見取り図
・米国1は、Broadcom、Apollo、BlackstoneのAI XPV Platformを見落とし分として採用した。AI半導体需要が、チップ、ネットワーク、データセンター、private creditを一体化している点が重要。
・米国2は、Palantir CEO Alex Karpの発言を採用した。企業AIアプリの勝敗は、token消費ではなく、現場導入、FDE、task completion、社会的受容で決まる。
・日本とアメリカ以外2は、Alibaba CloudとZTEの公式更新を採用した。agent memory、harness、observability、AI networkは、GPUとHBM以外の企業AI支出を読む材料。
・関連公式系資料として、Satya Nadella投稿も重要。企業AIの価値は、外部モデルではなく、private eval、knowledge base、学習ループへ蓄積される。
・前日米国枠のNVIDIAとAMDによるMiniMax M3公式技術更新は、長文・マルチモーダル・agentic推論がserving stack競争に入った材料。
・日本1、日本2、日本とアメリカ以外1は、今回の昼刊作成時点で当日ログ上の新規採用を確認できなかった。NTT東日本IOWN、NTTデータ製造DX、Kioxia SSD、Sony Semiconductor X線CMOSは継続監視対象。
■AI計算資源はチップ金融へ広がる
・Broadcom、Apollo、BlackstoneのAI XPV Platformは、AI compute需要を半導体企業の受注だけで読めないことを示した。
・報道ベースでは、初期規模は350億ドル。Anthropicの1GW超のcompute infrastructure拡張を支える枠組みとされる。2028年までに20GW超のcompute capacityを可能にする構想として説明されている。
・投資上の焦点は、Broadcomのcustom AI acceleratorsとAI networkingが、Google TPU、Anthropic、データセンターリース、private creditへ接続する点にある。
・強気材料は、BroadcomがAI ASICとネットワーク半導体の供給者にとどまらず、AI labの計算資源拡張を金融資本と結ぶ位置へ入ること。
・注意点は、需要の一部がSPV、lease payments、chip collateral、Broadcom backstopに依存すること。AI半導体需要を見る際は、誰が債務を負い、誰が旧世代チップ価値の下落を負担するかを分ける必要がある。
■企業AIは現場成果で測る
・Palantir CEO Alex Karpの発言は、AIアプリ企業の価値を「強いモデルを持つこと」ではなく、「顧客業務に入り、成果を出すこと」から見る材料になった。
・PalantirのFDE型モデルは、顧客データ、業務フロー、意思決定、運用へ深く入る。これはAIアプリの価格決定力を作る。一方で、人的導入支援のコスト、粗利、導入速度が制約になる。
・Karpのtokenmaxxing批判は、Nadellaの問題意識とも接続する。AI需要をtoken量だけで読むと、顧客ROI、human rework、再試行、監査、社会的受容を見落とす。
・半導体投資の観点では、AIアプリ企業の成長をGPU需要へ直線変換しない。業務AIの需要は、クラウドGPU、CSP内製AI ASIC、CPU、セキュアクラウド、データベース、監査基盤へ分かれる。
■agentの本番化はDBと監査を買う
・Alibaba Cloudの公式ブログ群は、agentic AIの本番化を、長期記憶、agent harness、observability、auditへ分解した。
・PolarDB Mem0は、会話履歴を丸ごとcontextへ入れるのではなく、ユーザーの好み、関係、制約、過去状態を抽出し、次回の判断に使う層として説明される。
・Natural-Language Harnessは、agentがいつモデルを呼び、どう検証し、失敗時にどう再試行するかを制御する実行戦略である。モデル性能が高くても、harnessが弱いとtask completion単価は上がる。
・Agent Observabilityは、LLM invocation、tool execution、file access、command execution、token costをtraceする。企業がagentを許可するには、誰が何を読んで何を実行したかを追える必要がある。
・ZTEのAI-powered network発表は、AI需要が通信インフラ側にも広がる入口である。ただし受賞発表であり、契約額、基地局出荷、通信事業者capexは未確認。
■token capitalは社内学習ループで決まる
・Nadella投稿は、企業AIの価値が外部モデルの選定ではなく、人間資本とtoken capitalを結ぶ学習ループに蓄積されるという論点を出した。
・重要な部品は、private eval、private reinforcement learning environment、knowledge base、institutional memory、model replaceabilityである。
・この論点はMicrosoftに有利な戦略的主張でもある。投資判断では、企業が本当に社内traceを評価と改善に使い、業務KPI、継続率、クラウド支出、AIアプリ売上へ変換しているかを確認する必要がある。
・半導体需要への影響は両義的。学習ループの運用が増えれば、推論、評価、検索、ログ、追加学習、監査の需要は増える。一方で、knowledge baseとmodel routingが進むと、高価なフロンティアモデルの過剰利用は減る。
■長文agent推論はGPUスタック競争へ入る
・NVIDIAとAMDのMiniMax M3公式更新は、長文・マルチモーダル・agentic推論が、GPU単体ではなくserving stackの競争になったことを示す。
・MiniMax M3は、1M context、MoE、native multimodal input、tool-call parserを持つopen-weight modelとして扱われた。
・NVIDIAはTensorRT LLM、SGLang、vLLM、Dynamo、NeMoを通じ、Blackwell上で本番推論へ載せる導線を強調した。
・AMDはROCm、vLLM、SGLang、MI300 / MI350、OpenAI-compatible serving、MXFP8対応を示し、open-weight frontier modelのday-zero対応を訴求した。
・投資上は、NVIDIA対AMDの勝敗だけではなく、prefill、KV cache、MoE、routing、tool-call parser、vision encoder、SLO、クラウド価格を確認する必要がある。
■昼刊のまとめ
・今日の企業発表系材料は、AI需要が「GPUを何台買うか」だけでは読めないことを強く示した。
・上流ではBroadcomのAI XPV Platformが、AI ASIC、ネットワーク、データセンター、private creditを結んだ。
・中流ではNVIDIAとAMDが、長文agent推論をserving stack競争にした。
・下流ではAlibaba Cloud、Palantir、Nadella投稿が、企業AIの本番価値を、記憶、監査、現場導入、社内学習ループへ分解した。
・投資で見るべき次の軸は、capex総額ではなく、誰が支払い、どの層へ売上が落ち、task completionあたりの原価と成果が改善しているかである。

1,873


Dev tools on OpenNomos: timestamp converter (auto-detect s/ms, two-way) JSON parser (prettify/minify, error highlight). Clean, fast, free → json.opennomos.com
2
27

llama.cpp b9637 added a dedicated Cohere2MoE / North Code chat parser. This is the unglamorous part of local model support: the runtime absorbs tokenizer and chat-template quirks so users are not debugging prompt formats by hand.
6


What if the fastest JS/TS linter written by Zig and Codex 5.5?
utoo lint, based on Yuku, the fastest JavaScript parser by @arshadyaseeen
-> 108x faster than eslint
-> 3-5x faster than oxlint, biome & others on Node.js
-> 300 lint rules supported
github.com/fireairforce/utoo…
1
7
415


🔍 A roundup of the Ruby performance improvements that quietly shipped over the last year, from faster string operations and file I/O to parser, GC, and JIT optimizations. #Ruby mensfeld.pl/2026/06/ruby-per…
1
5
233


BestBlogs Daily · 06-15
# Martin Fowler / Software Architecture Guide / GPU Time-Slicing / Kubernetes / p99 Latency
[1] ★ Deep Dive · Software Architecture Guide
Martin Fowler reframes architecture as 'the important stuff' — decisions senior engineers must get right early, since high quality compounds by cutting rework. The guide maps application and enterprise architecture with deep-dives on martinfowler.com, echoing EP82's 'Loop Engineering' and EP85's 'model eats the harness' on what 'important' means once agents absorb execution.
Source: Hacker News
bestblogs.dev/article/6ce856…
[2] ★ Deep Dive · The hidden pattern behind successful products | Mark Pincus (FarmVille, Words with Friends, & more) [Video]
Mark Pincus (Zynga founder) argues successful products rarely start from pure originality. His 'Proven Better New' framework: find a proven user behavior, add one clearly better improvement, then test it with humility. He warns against ego-driven ambition, distinguishing 'belief' from 'hope'. Echoes EP81's Tony Fadell: veteran builders copy proven patterns precisely, then layer one honest improvement.
Source: Lenny's Podcast
bestblogs.dev/video/4540937
[3] ★ Deep Dive · GPU Time-Slicing for Concurrent LLM Agents on Kubernetes
A controlled experiment finds Kubernetes GPU time-slicing for concurrent LLM agents keeps throughput and median latency flat, but p99 latency for a worker pod spikes 66% under contention — invisible on typical dashboards. Production agents fighting over shared GPUs hit exactly this tail-latency trap, extending EP80's cache-invalidation warning: capacity planning needs p99-aware testing before GPU sharing ships.
Source: Towards Data Science
bestblogs.dev/article/07cfce…
[4] Epigrams in Programming
A collection of 120 epigrams by Alan J. Perlis that distill profound, often paradoxical, truths about programming, software engineering, and the nature of computation.
Source: Hacker News
bestblogs.dev/article/d99a46…
[5] Formal methods and the future of programming
Jane Street shifts from skepticism to excitement about formal methods, driven by agentic coding's potential to lower costs and increase benefits, and is building a dedicated team.
Source: Hacker News
bestblogs.dev/article/c15f79…
[6] Detailed Analysis of the Anthropic Fable Export Control Incident
A comprehensive thread analyzing the events leading to the U.S. government's export controls on Anthropic's Fable 5 model, including the jailbreak, government response, and implications.
Source: prinz(@prinzeugen____)
bestblogs.dev/status/2065651…
[7] Don't just aim for Frontier Labs — LessWrong
This essay argues that AI safety and security competency must be distributed across every organization that deploys AI, not concentrated solely in frontier labs, drawing on precedents from cybersecurity, aviation, finance, and other safety-critical industries.
Source: LessWrong
bestblogs.dev/article/bb19db…
[8] How to Run Private Text-to-Speech on Your Own Hardware Using QVAC
This article provides a practical guide to implementing offline, high-fidelity Text-to-Speech in a React Native app using the QVAC SDK, covering model selection, audio packaging, and state management.
Source: freeCodeCamp
bestblogs.dev/article/220635…
[9] Vision LLMs are PDF Parsers Too: Reading Charts and Diagrams for RAG
This article argues that vision LLMs can serve as a full PDF parser for RAG, uniquely capable of making charts and diagrams searchable, while honestly assessing the trade-offs in cost, exactness, and completeness compared to traditional text-based parsers.
Source: Towards Data Science
bestblogs.dev/article/ee35a4…
[10] Can a stronger model fake being a weaker one? Mostly not — LessWrong
This paper tests whether frontier AI models can imitate weaker predecessors and finds they can match capability levels but not specific model identities, with chain-of-thought reasoning serving as an effective mitigant.
Source: LessWrong
bestblogs.dev/article/af0dc1…
---
BestBlogs.dev · Discover high-quality content that truly fits you
BestBlogs is an AI-powered personal reading assistant that helps you build a stable, trusted, and personalized flow of high-quality information. Follow the sources and topics you care about, and get a daily brief that fits your reading rhythm.
Read online: bestblogs.dev/en/explore/bri…

1
101


Sometimes I like to go to the wasm julia parser website we built together just to feel like Fable is still with us (kenoaistaging.github.io/expe…).
1
171


Are you talking about original vanilla? 2004? Yeah because back then people were legitimately dogshit. You send a green parser today back to 2004 classic and they'd be a top player.
15

writing a complex peg parser necessitates so many negative lookaheads this shit exactly like my outlook on life
3
68

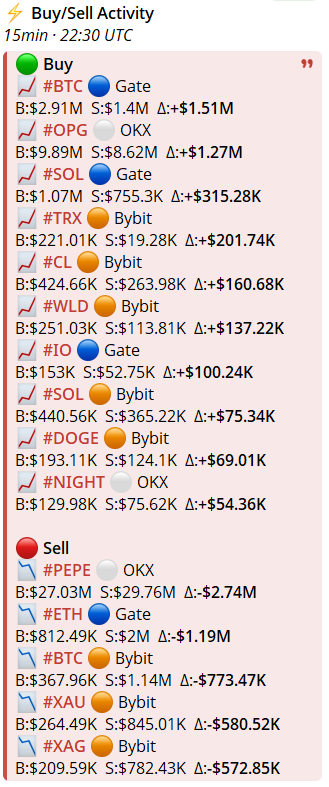
Parser which follow for me each 15m t⚡ How systematic market monitoring looks like
Instead of manually flipping through hundreds of charts, my parser tracks real-time volume and delta anomalies across multiple exchanges every 15 minutes. The best opportunities on the marker
If you interested just
⚡️ Buy/Sell Activity
15min · UTC
🟢 Buy
📈 #BTC 🔵 Gate
B:$2.91M S:$1.4M Δ: $1.51M
📈 #OPG ⚪️ OKX
B:$9.89M S:$8.62M Δ: $1.27M
📈 #SOL 🔵 Gate
B:$1.07M S:$755.3K Δ: $315.28K
📈 #TRX 🟠 Bybit
B:$221.01K S:$19.28K Δ: $201.74K
📈 #CL 🟠 Bybit
B:$424.66K S:$263.98K Δ: $160.68K
📈 #WLD 🟠 Bybit
B:$251.03K S:$113.81K Δ: $137.22K
📈 #IO 🔵 Gate
B:$153K S:$52.75K Δ: $100.24K
📈 #SOL 🟠 Bybit
B:$440.56K S:$365.22K Δ: $75.34K
📈 #DOGE 🟠 Bybit
B:$193.11K S:$124.1K Δ: $69.01K
📈 #NIGHT ⚪️ OKX
B:$129.98K S:$75.62K Δ: $54.36K
🔴 Sell
📉 #PEPE ⚪️ OKX
B:$27.03M S:$29.76M Δ:-$2.74M
📉 #ETH 🔵 Gate
B:$812.49K S:$2M Δ:-$1.19M
📉 #BTC 🟠 Bybit
B:$367.96K S:$1.14M Δ:-$773.47K
📉 #XAU 🟠 Bybit
B:$264.49K S:$845.01K Δ:-$580.52K
📉 #XAG 🟠 Bybit
B:$209.59K S:$782.43K Δ:-$572.85K
1
43