


1
2
7
715

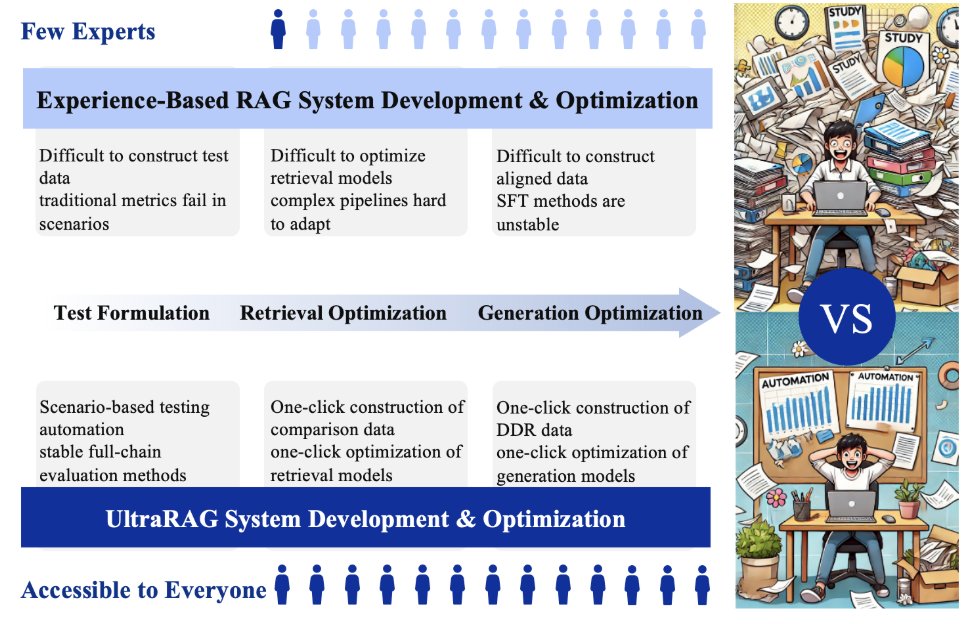
UltraRAG Framework streamlines RAG system development with automated data construction, model fine-tuning, and evaluation.
- No-Code WebUI for easy setup and multimodal RAG support.
- One-Click Fine-Tuning using tools like KBAlign and RAG-DDR.
- Robust Evaluation via the RAGEval multi-stage assessment method.
- Research-Friendly Design for exploring advanced RAG methods.
- Accessible entirely through a user-friendly web interface.

🚀Excited to introduce our work #UltraRAG, simplifying the entire process from data construction to model fine-tuning, making complex tasks easier for researchers and developers alike.
✨ Key Highlights:
> No-Code Programming WebUI Support
> One-Click Solution for Synthesis and Fine-Tuning
> Multidimensional, Multi-Stage Robust Evaluation
> Research-Friendly Exploration Work Integration
Thanks to the joint work by top teams from @Tsinghua_Uni, @Northeastern, @ModelBest2022, and 9#AISoft!
🔗 GitHub:github.com/OpenBMB/UltraRAG
4
9
690

Some 🔑key components🔑 of #UltraRAG have been accepted by #ICLR2025, including VisRAG (Cross-Modality Retrieval) and RAG-DDR (Differentiable Data Rewards Optimization)!
📖 RAG-DDR: Optimizing Retrieval-Augmented Generation Using Differentiable Data Rewards. arXiv preprint arXiv:2410.13509.【ICLR 2025】, arxiv.org/abs/2410.13509
📖 VisRAG: Vision-based Retrieval-Augmented Generation on Multi-Modality Documents. arXiv preprint arXiv:2410.10594.【ICLR 2025】, arxiv.org/abs/2410.10594
📖 Retriever-and-Memory: Towards Adaptive Note-Enhanced Retrieval-Augmented Generation. arXiv preprint arXiv:2410.08821, arxiv.org/abs/2410.08821
📖 KBAlign: Efficient Self Adaptation on Specific Knowledge Bases. arXiv preprint arXiv:2411.14790, arxiv.org/abs/2411.14790
📖 RAGEval: Scenario specific rag evaluation dataset generation framework. arXiv preprint arXiv:2408.0126, arxiv.org/abs/2408.01262
1
1
3
737

🚀 Excited to share our latest work: “RAGEval”!
🎉 It’s a versatile framework for generating scenario-specific RAG evaluation datasets, complete with comprehensive metrics. Perfect for rapid evaluations! 🔍
✨ Paper: arxiv.org/abs/2408.01262
1
6
25
2,001

16 Aug 2024
4/ RAGEval isn’t just about creating datasets—it’s about understanding the unique challenges of each domain. Whether it’s the jargon-heavy world of finance or the precision required in legal contexts, RAGEval tailors evaluations to meet these needs.
1
3
38
16 Aug 2024
3/ Enter RAGEval: a framework designed to address this gap by creating domain-specific evaluation datasets. This approach ensures that RAG models are tested on the real-world scenarios they’ll encounter, making evaluations more relevant and reliable. @Kunlun_Zhu @zibuyu9
paper link -arxiv.org/pdf/2408.01262
1
2
3
120
16 Aug 2024
Evaluating Retrieval-Augmented Generation (RAG) Models in Domain-Specific Contexts
1/In today’s AI landscape, evaluating the performance of Retrieval-Augmented Generation (RAG) models is crucial, especially in specialized domains like finance, healthcare, and legal. We’ve written a detailed blog exploring the RAGEval framework and its significance. Check it out for in-depth analysis and practical insights!
Blog link - blog.getmaxim.ai/rageval-sce…
#RAG #AI #NLP #AICommunity #LLMs
1
3
4
197

15 Aug 2024
RAGの性能を検証するためのフレームワークかー。
どんどんこういうのが出てきますね。
新しい技術を取り入れたら評価・分析しなきゃいけないから、この手の技術も学んでいきたいですね。
あらゆる分野のRAGの性能を評価する手法RAGEval
zenn.dev/knowledgesense/arti…
3
113

13 Aug 2024
RAGの性能を検証するためのテストデータを、自動で作成してくれるフレームワーク「RAGEval」について紹介しています。
RAGのシステムを作るうえで一つの大きな障壁になる、テストデータの用意を劇的に楽にしてくれる可能性を秘めています。
zenn.dev/knowledgesense/arti… #zenn
25
238
16,645

12 Aug 2024
Top LLM papers of the week
Papers link - linkedin.com/pulse/top-llm-p…
[1] RAG Evaluation Dataset Generation Framework
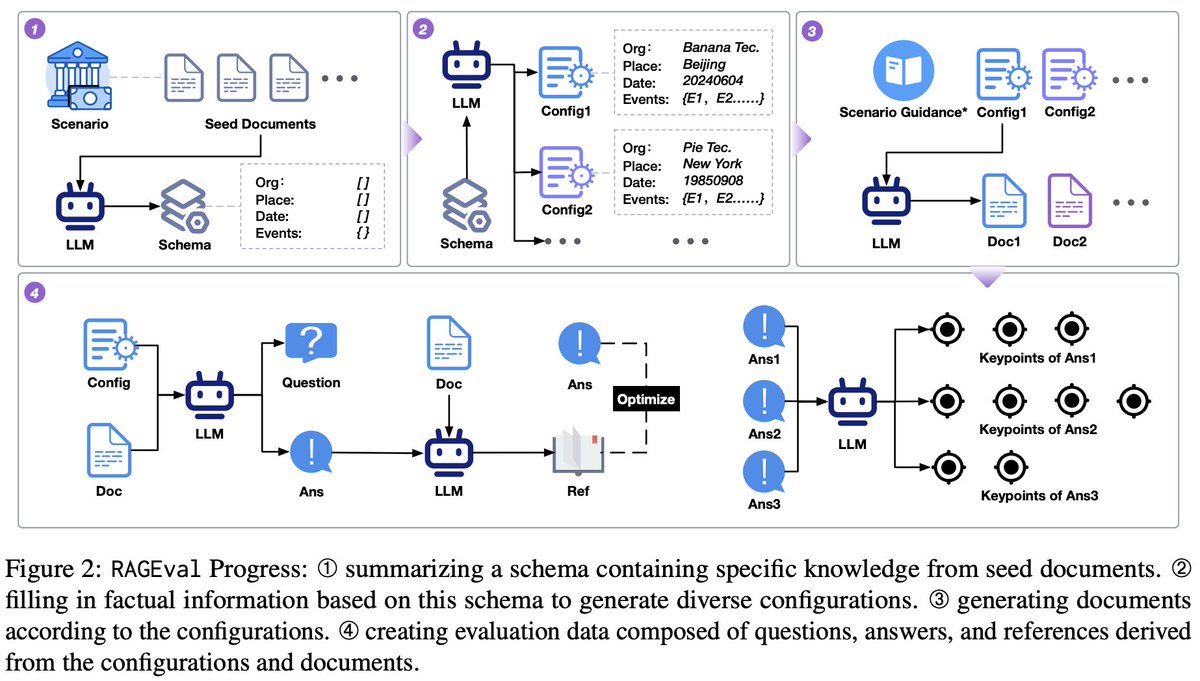
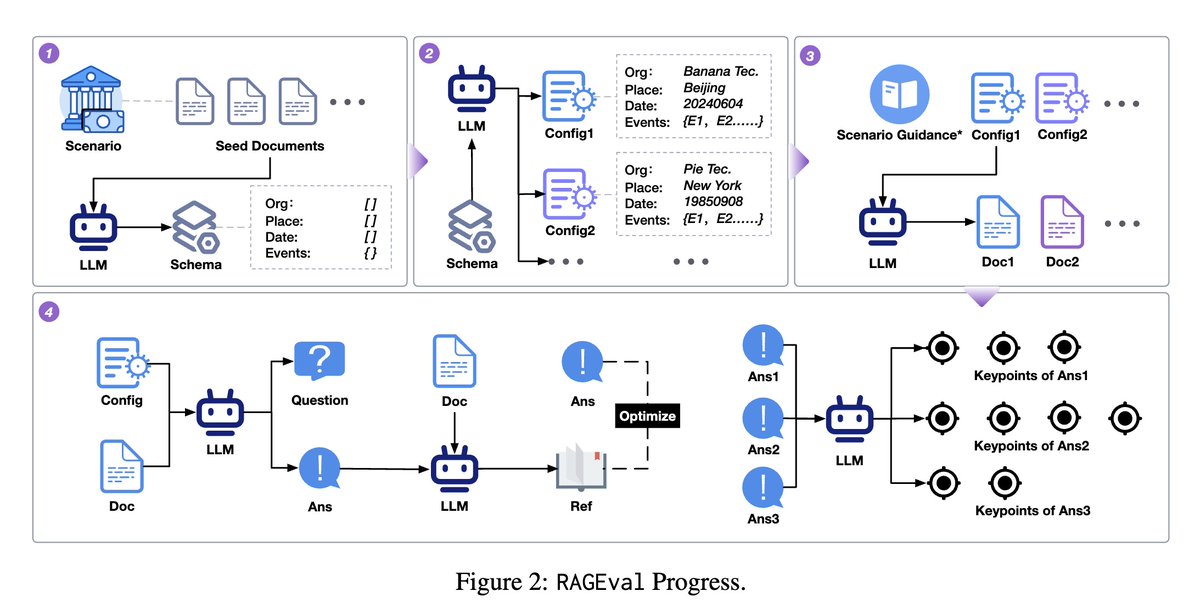
Current RAG benchmarks don't effectively evaluate RAG systems' performance across various vertical domains. This paper introduces RAGEval, a framework for automatically generating RAG evaluation datasets. RAGEval summarizes a schema from seed documents, applies the configurations to generate diverse documents, and constructs question-answering pairs according to both articles and configurations. RAGEval also introduces three new metrics: Completeness, Hallucination, and Irrelevance.
[2] Generate High-Quality Instruction Data with Open-Sourced LLMs
Creating instruction datasets is costly and time-consuming, requiring manual annotation or expensive API calls to proprietary LLMs. This paper introduces FANNO, a novel framework to generate diverse and high-quality instruction datasets comparable to human-annotated ones.
[3] 500x Prompt Compressor
Prompt compression is essential for improving inference speed, reducing costs, and enhancing user experience. This paper introduces 500xCompressor, a method that compresses extensive natural language contexts into as little as one special token. It adds only about 0.3% additional parameters and achieves compression ratios between 6x and 480x. The results demonstrate that the LLM retained 62.26-72.89% of its capabilities compared to using non-compressed prompts.
[4] Fine-Grained Machine-Generated Text Detection Tool
This paper introduces LLM-DetectAIve system for fine-grained detection of machine-generated texts four categories namely human-written, machine-generated, machine-written machine-humanized, and human-written machine-polished. Unlike previous detectors that perform binary classification, LLM-DetectAIve offers insights into varying degrees of LLM intervention during text creation. This is highly useful areas like education, where any use of LLMs may be prohibited.
[5] EfficientRAG
Retrieval-augmented generation (RAG) methods face challenges with complex questions, particularly multi-hop queries. EfficientRAG approach avoids multiple calls to LLMs by iteratively generating new queries and outperforms existing RAG methods on three open-domain multi-hop question-answering datasets.
[6] Synthetic Medical Text Generation Framework
This paper introduces MedSyn, a new framework for generating medical text and it combines LLMs with a Medical Knowledge Graph (MKG). The MKG is used to sample prior medical information for prompts, which are then used to generate synthetic clinical notes using GPT-4 and fine-tuned LLaMA models. MedSyn generated synthetic data results in an increase in accuracy of up to 17.8% in the ICD code prediction task.
[7] RAG Foundry
This paper introduces RAGFoundry, an open-source framework for enhacing LLMs for RAG use cases. RAG FOUNDRY integrates data creation, training, inference and evaluation into a single workflow, facilitating the creation of data-augmented datasets for training and evaluating large language models in RAG settings. Results show the framework's effectiveness by augmenting and finetuning Llama-3 and Phi-3 models with diverse RAG configurations, showcasing consistent improvements across three knowledge-intensive datasets.
[8] BioRAG
BioRAG is a novel LLM-based Retrieval-Augmented Generation (RAG) framework specifically designed to overcome the challenges inherent in life science question-answering systems. Rigorous experiments have demonstrated BioRAG's superior performance compared to fine-tuned LLMs, LLMs with search engines, and other scientific RAG frameworks.
[9] BioMamba
BioMamba is an LLM based on Mamba architecture, specifically designed for biomedical text mining. It has been pre-trained on an extensive corpus of biomedical literature, making it uniquely suited for tasks in this domain. BioMamba achieves significant performance improvements over existing models like BioBERT and general-domain Mamba. Importantly, it achieves a 100× reduction in perplexity and a 4× reduction in cross-entropy loss on the BioASQ test set. [Paper]
[10] LLM Safety Evaluation Toolkit
WalledEval is a comprehensive AI safety testing toolkit designed to evaluate both open-source and closed-source large language models (LLMs). WalledEval features over 35 safety benchmarks which cover various crucial areas including Multilingual safety, Exaggerated safety and Prompt injection.
#llms #toppapers #llmpapers #generativeai #researchpapers #research
1
6
566

12 Aug 2024
RAGEvalというRAGの評価データセットを自動生成するフレームワーク紹介(Code/Data共にLinkなし、考え方のみ)。評価指標としてCompleteness、Hallucination、Irrelevanceの3つを提案
RAGEval: Scenario Specific RAG Evaluation Dataset Generation Framework
arxiv.org/abs/2408.01262
2
15
73
5,355

[CL] RAGEval: Scenario Specific RAG Evaluation Dataset Generation Framework
K Zhu, Y Luo, D Xu, R Wang... [Tsinghua University & Beijing Normal University] (2024)
arxiv.org/abs/2408.01262
- Existing RAG benchmarks mainly focus on general knowledge and are unable to effectively evaluate RAG systems' capabilities in vertical domains like finance, healthcare, and legal.
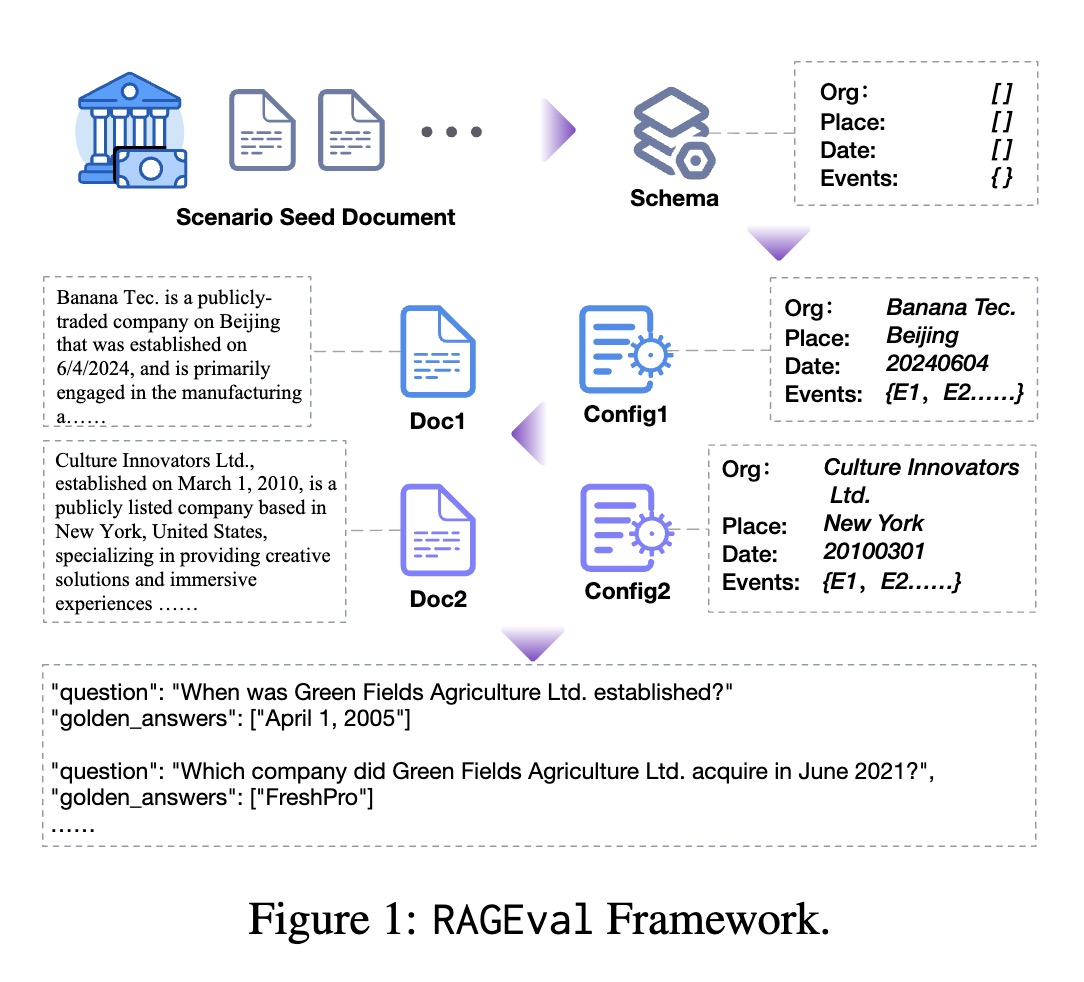
- This paper introduces RAGEval, a framework to automatically generate scenario-specific datasets to assess RAG systems' factual accuracy and domain knowledge.
- RAGEval summarizes schema from seed documents, generates configurations and documents adhering to the schema, and constructs QA pairs based on articles and configs.
- RAGEval proposes novel metrics - Completeness, Hallucination, Irrelevance - to evaluate RAG responses based on key factual points.
- Experiments show metrics like Completeness better reflect model capabilities than sparse metrics like ROUGE-L in RAG scenarios.
- RAGEval provides higher contextual agility to design domain-specific factual queries, enabling better alignment with each application's demands.


1
4
9
1,954

9/ RAGEval - proposes a simple framework to automatically generate evaluation datasets to assess knowledge usage of different LLM under different scenarios; it defines a schema from seed documents and then generates diverse documents which leads to question-answering pairs; the QA pairs are based on both the articles and configurations.
x.com/omarsar0/status/182050…

RAGEval
Proposes a simple framework to automatically generate evaluation datasets to assess knowledge usage of different LLM under different scenarios.
It defines a schema from seed documents and then generates diverse documents which leads to question-answering pairs. The QA pairs are based on both the articles and configurations.
It seems that this benchmark can help with more reliably evaluating the knowledge usage ability of LLMs and avoids confusion regarding the source of knowledge (parameterized or retrieval).

1
1
10
3,489

10 Aug 2024
RAGEval: Scenario Specific RAG Evaluation Dataset Generation Framework
Overview:
This paper introduces RAGEval, a framework designed to evaluate Retrieval-Augmented Generation (RAG) systems in handling domain-specific data.
Unlike existing benchmarks focused on general knowledge, RAGEval generates evaluation datasets for different vertical domains and assesses LLMs' knowledge usage with three metrics: Completeness, Hallucination, and Irrelevance.
By benchmarking RAG models across various domains, RAGEval provides a clearer assessment of whether LLM responses are based on retrieved knowledge or internal memory.
paper:
arxiv.org/abs/2408.01262

1
2
5
745
10 Aug 2024
🚨This week’s top AI/ML research papers:
- An Object is Worth 64x64 Pixels
- Self-Taught Evaluators
- Transformers are Universal In-context Learners
- Pre-training Once for Models of All Sizes
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
- Can Editing LLMs Inject Harm?
- CoverBench
- RAG Foundry
- RAGEval
- Language Model Can Listen While Speaking
- Transformer Explainer
VLM/Vision
- LLaVA-OneVision
- MiniCPM-V
- Medical SAM 2
- MMIU
Others
Others
- MeshAnything V2
- Achieving Human Level Competitive Robot Table Tennis
- Optimus-1
overview for each & authors' explanations
read this in thread mode for the best experience

3
83
424
50,543