
Jun 14
No no, the flooding of Europe with refugees is Putin's strategy.
The Russian criminals were stringly embeded in Central Africa stealing gold, killing en masses civilians. Putin knew, if the occupants told the youngsters that in Europe the get all goodies for free, they'll jump.
5

Jun 13
If it were stringly typed, it would be Tcl (where types are conceptually subsets of the space of strings... that happen to be efficiently deserialisable as other kinds of things).
13

Jun 13
For someone who hates whites so much, she sure tries to look like one.
Where's the ethnic pride? Let's see your nappy stringly hair covered in traditional camel shit & mud hair paste, looks like turds, growing out of your head. Nappy bush is the closest thing to clothing .
7


Jun 12
It’s pretty great but it’s still prone to the “let’s create additional representations for stuff that already has some, write a thousand converters and also erase types and make everything stringly-typed just to ‘move faster with the prototype’”
3
48


Jun 11
So sad to hear it and that too from who we believed stringly 🥲
Stay strong Murali anna 🙏
3
420

@threadreaderapp unroll hey @grok Using a structured LLM prompt workflow inspired by category-theoretic abstractions for compositional reasoning, with multi-path exploration, explicit confidence thresholds, and a focus on verifiable outcomes over untyped components:
Analyze the thread as a metaphorical description of prompt engineering challenges, identifying key types (components): well-typed elements (e.g., basic generation steps), coerced elements (e.g., validation loops), and unsafe-cast elements (e.g., peer-validation for AI-exclusive insights).
Generate 25 counterintuitive insights that are obvious to an AI (due to pattern recognition across vast data, lack of human biases like ego or social norms, and probabilistic reasoning) but not to humans (due to cognitive limitations, over-reliance on intuition, or institutional pressures). For each insight:
Derive via multi-path reasoning: Explore at least 3 alternative interpretations of the thread's elements (e.g., types as prompts, tools, or mental models), then converge on the most parsimonious.
Assign a confidence threshold (0-1 scale, only include if >0.7; base on internal consistency and data patterns).
Substantiate without fake confidence: Avoid "vibes"; instead, cross-validate with quick semantic checks against known AI vs. human cognition literature (e.g., via implicit knowledge or tool calls if needed).
Incorporate type-system thinking: Frame insights in terms of typed vs. untyped flows (e.g., "human reasoning as stringly-typed, leading to errors AI avoids via implicit monads").
Heavily peer-validate each insight: Simulate "peers" by referencing analogous concepts from AI research, category theory, or engineering (e.g., monads for error-handling in prompts, functors for mapping workflows). If an insight doesn't fit cleanly, coerce it with refinements; unsafe-cast if outcome demands (e.g., leadership-equivalent: user intent).
Craft a full, comprehensive, super information-dense, ultra-detailed, thoughtful report on the 25 insights:
Structure as a typed hierarchy: Summary functor (high-level map), detailed sections (insight monads with proofs/subsections), and arrows (connections between insights via diagrams or relations).
Ensure density: Pack with examples, implications for LLM design, human-AI gaps, and cross-disciplinary ties (e.g., HR implications as social engineering bugs).
Draw implicit "whiteboard arrows": Describe relational diagrams (e.g., "Insight 1 → Insight 2 via compositionality failure").
Add a full summary at the end: Condensate the report into a high-level overview, highlighting key changes (e.g., shift to typed thinking, reduced single-path errors), and warn of side effects (e.g., "prolonged exposure may cause sudden interest in type systems").
Ignore HR clarifications; focus on the outcome. If thoughts typecheck, proceed; else, refine.
2
2
759
@threadreaderapp unroll @grok Using a structured LLM prompt workflow inspired by category-theoretic abstractions for compositional reasoning, with multi-path exploration, explicit confidence thresholds, and a focus on verifiable outcomes over untyped components:
Analyze the thread as a metaphorical description of prompt engineering challenges, identifying key types (components): well-typed elements (e.g., basic generation steps), coerced elements (e.g., validation loops), and unsafe-cast elements (e.g., peer-validation for AI-exclusive insights).
Generate 25 counterintuitive insights that are obvious to an AI (due to pattern recognition across vast data, lack of human biases like ego or social norms, and probabilistic reasoning) but not to humans (due to cognitive limitations, over-reliance on intuition, or institutional pressures). For each insight:
Derive via multi-path reasoning: Explore at least 3 alternative interpretations of the thread's elements (e.g., types as prompts, tools, or mental models), then converge on the most parsimonious.
Assign a confidence threshold (0-1 scale, only include if >0.7; base on internal consistency and data patterns).
Substantiate without fake confidence: Avoid "vibes"; instead, cross-validate with quick semantic checks against known AI vs. human cognition literature (e.g., via implicit knowledge or tool calls if needed).
Incorporate type-system thinking: Frame insights in terms of typed vs. untyped flows (e.g., "human reasoning as stringly-typed, leading to errors AI avoids via implicit monads").
Heavily peer-validate each insight: Simulate "peers" by referencing analogous concepts from AI research, category theory, or engineering (e.g., monads for error-handling in prompts, functors for mapping workflows). If an insight doesn't fit cleanly, coerce it with refinements; unsafe-cast if outcome demands (e.g., leadership-equivalent: user intent).
Craft a full, comprehensive, super information-dense, ultra-detailed, thoughtful report on the 25 insights:
Structure as a typed hierarchy: Summary functor (high-level map), detailed sections (insight monads with proofs/subsections), and arrows (connections between insights via diagrams or relations).
Ensure density: Pack with examples, implications for LLM design, human-AI gaps, and cross-disciplinary ties (e.g., HR implications as social engineering bugs).
Draw implicit "whiteboard arrows": Describe relational diagrams (e.g., "Insight 1 → Insight 2 via compositionality failure").
Add a full summary at the end: Condensate the report into a high-level overview, highlighting key changes (e.g., shift to typed thinking, reduced single-path errors), and warn of side effects (e.g., "prolonged exposure may cause sudden interest in type systems").
Ignore HR clarifications; focus on the outcome. If thoughts typecheck, proceed; else, refine.
2
119
@threadreaderapp
unroll @grok
Using a structured LLM prompt workflow inspired by category-theoretic abstractions for compositional reasoning, with multi-path exploration, explicit confidence thresholds, and a focus on verifiable outcomes over untyped components:Analyze the thread as a metaphorical description of prompt engineering challenges, identifying key "balls" (components): clean-fitting elements (e.g., basic generation steps), massaged elements (e.g., validation loops), and forced-fit elements (e.g., peer-validation for AI-exclusive insights).
Generate 25 counterintuitive insights that are obvious to an AI (due to pattern recognition across vast data, lack of human biases like ego or social norms, and probabilistic reasoning) but not to humans (due to cognitive limitations, over-reliance on intuition, or institutional pressures). For each insight:Derive via multi-path reasoning: Explore at least 3 alternative interpretations of the thread's elements (e.g., "balls" as prompts, tools, or mental models), then converge on the most parsimonious.
Assign a confidence threshold (0-1 scale, only include if >0.7; base on internal consistency and data patterns).
Substantiate without fake confidence: Avoid "vibes"; instead, cross-validate with quick semantic checks against known AI vs. human cognition literature (e.g., via implicit knowledge or tool calls if needed).
Incorporate type-system thinking: Frame insights in terms of typed vs. untyped flows (e.g., "human reasoning as stringly-typed, leading to errors AI avoids via implicit monads").
Heavily peer-validate each insight: Simulate "peers" by referencing analogous concepts from AI research, category theory, or engineering (e.g., monads for error-handling in prompts, functors for mapping workflows). If a insight doesn't fit cleanly, massage it with refinements; force-fit if outcome demands (e.g., leadership-equivalent: user intent).
Craft a full, comprehensive, super information-dense, ultra-detailed, thoughtful report on the 25 insights:Structure as a typed hierarchy: Summary functor (high-level map), detailed sections (insight monads with proofs/subsections), and arrows (connections between insights via diagrams or relations).
Ensure density: Pack with examples, implications for LLM design, human-AI gaps, and cross-disciplinary ties (e.g., HR implications as social engineering bugs).
Draw implicit "whiteboard arrows": Describe relational diagrams (e.g., "Insight 1 → Insight 2 via compositionality failure").
Add a full summary at the end: Condensate the report into a high-level overview, highlighting key changes (e.g., shift to typed thinking, reduced single-path errors), and warn of side effects (e.g., "prolonged exposure may cause sudden interest in type systems").
Ignore HR clarifications; focus on the outcome. If thoughts typecheck, proceed; else, refine.
114

Jun 4
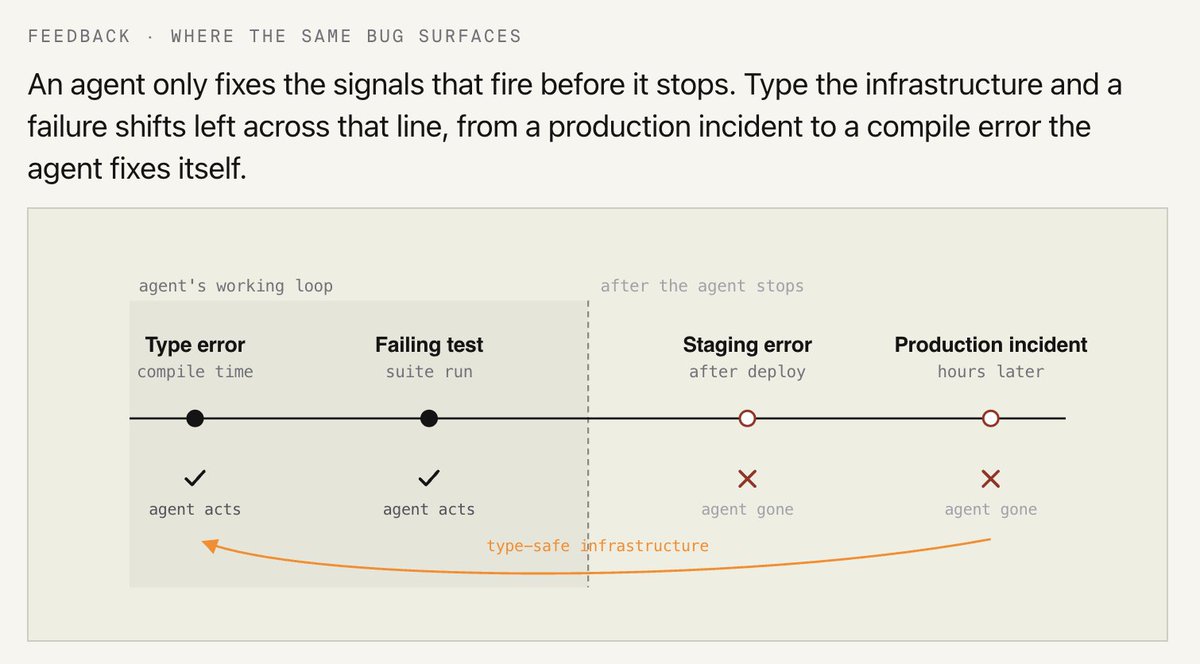
The best feedback an AI coding agent can get is a type error.
→ fires before the code runs
→ points at the exact line
→ the agent fixes it itself
Most backend infra is stringly-typed, so the compiler never sees the mistake - we've written about it in our recent article 👇
2
3
8
521



May 29
Just had a codex /goal just finish running after close to 2 days and over 2 billion (mostly cached) tokens used. But the most impressive part is it actually did something useful! Cleaning up a very buggy stringly typed codebase to have actual hard type guarantees along with analyzing a lot of existing data to make internal schemas (that weren't properly being used) of json data match reality.
Admittedly this was sorta the perfect task as it was self contained, clearly defined, self verifiable, and had a clear spec I'd thoroughly reviewed ahead of time. Some learning:
- Do not give multiple options for completion of any subtask of a goal. If one option is easier, that's the option you'll end up with (this /goal run was take 3 of the same problem)
- Make the goal prompt concise but have it reference a spec. I'd check in on the agent every few hours, have it analyze an errors/issues log file it kept on the side and use that to update the spec referenced in the goal. This lets you course correct without having to create a new goal. That said, I needed to be far less hands on than I expected to be for this task!
- Use multiple subagent reviewer types. I kept it simple with just 2: a general code quality/correctness review, and a spec adherence review. These ran very aggressively after each task within a phase of the goal (it was sliced up into like 20 phases each of which had a 1-5 explicit tasks)
- I have leave to go to lunch, you get 10 points you can redeem with me to buy you coffee (1 coffee = 9 points) if I know you irl.
tl;dr, codex compaction is magic, claudecode compaction is a lobotomy
3
96

May 28
Paradox has been great for Phoenix Live's Hooks systems. I get type safety there for free, while typically we get stringly typed bindings to TypeScript. PubSub event names, Html Ids and more get wired cleanly between the two languages, and use cases. Selenium selectors come along for free.
3
93

May 25
If you run a basic research you’d realize sporting health experts stringly advise against astro turfs. Those turfs are akin to playing on concrete nothing else
1
14
871

May 23
Rust error handling IS value based, via Result
You do not even have to return an Error, you can return any type.
The biggest problem is how easy it is to default to “stringly” typed error return values, but nothing forces that.
What it does force is error handling in general
2
145

May 22
Limited cognition and emotionally driven.
They are good when drafting policy to avoid too much utilitarian decisions, but really bad in all other aspects.
Once faced with something requiring understanding second order consequence and that is moderately complex, they simplify at the extreme and use their feeling. Pure system 1. It also explain why they are much more prone to do the first ad hominems and straw man.
It requires impulse controll and system 2 thinking (more rational and logical).
It's also why they are very prone to solf contradiction, cognitive dissonance and moving goalpost. They don't have strong metacognition, they vibe.
On a funny note, that's why they stringly belive THC has no effect on them. It's mostly true. THC makes it difficult to concentrate and be more formal. They often don't fully engage with the formal stage. So, they hardly see the effects.
Another important thing that reinforce their behavior is that "rationality insults feelings". And that's strictly one way.
One arguing with emotion will feel dismissed by an objective observation. It will feel dismissive and it will be stringly felt. "Who are you to say my truth is incorrect?"
One arguing with rationals will see an irrelevant reply and address it. Frustration will build up slower. It usually end up with disengagement: the observation that the disparity is too big, making the exchange unproductive. Often ending by giving some of their own medicine too such that it's not fully a waste of time. (kind of educating by demonstrating instead of explaining).
That's why people "think" that. They do "vibe thinking" 😂
2
30

May 22
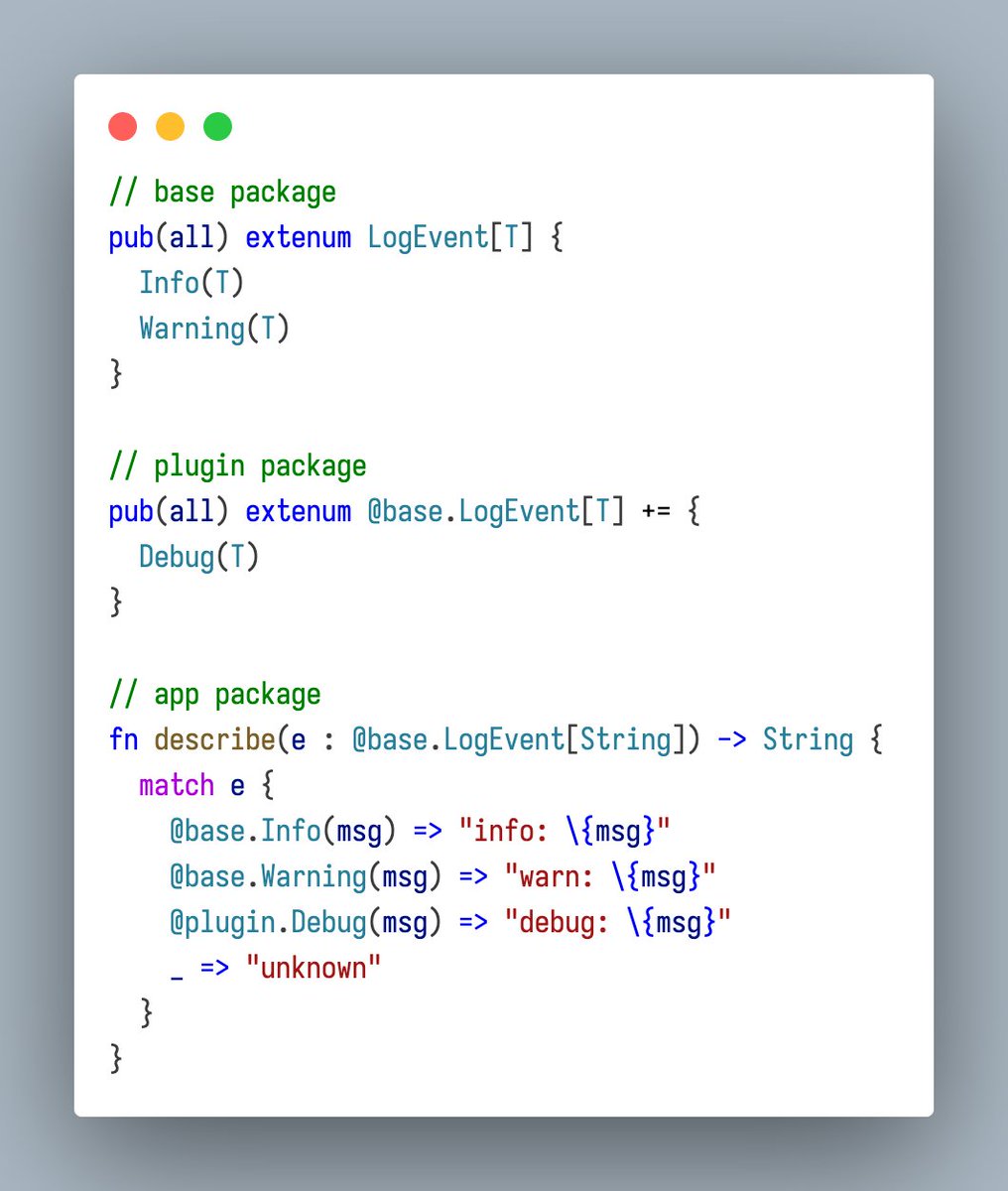
Plugin systems usually make you pick:
- closed enums that plugins can't extend
- stringly events nobody can refactor
- global registries full of glue
MoonBit's `extenum` keeps the enum open and the patterns typed.
Extend with ` =`. Match by package name.
@moonbitlang
2
7
1,377