

Jun 13
NEURA is building facilities where humans wearing motion sensors & VR headsets can train robots 🥽
German robotics firm @NEURARobotics raised $1.4bn
Takeaways from CEO @regerdavid1’s chat with @tbpn
🔵There is a lack of data to train robotics models
🔵Internet/egocentric videos aren’t sufficient 👓
🔵Teleops data is needed 🦾
🔵Building infra/facilities to collect the right data
🟢Data collection facilities to be located globally 🌎
🟢Supply chain won't be limited to Europe
🟢Focus is not limited to humanoids
🟢Industrial use cases first, then household 🧑🍳
7
7
45
4,045
Hoda retweeted

Jun 10
gPrisma Familia❤️
PrismaX Teleops Beginner Guide: Control Explained
If you're new to Teleops, this is a simple guide to help you understand how it works.
What is Teleops?
Teleops is a system where you control a real robot using your keyboard in real time.
Every key you press directly moves the robot.
You are not watching automation, You are operating it.
Basic Control Keys:
W / S → Move forward / backward
A / D → Move left / right
Q / E → Move up / down
Z / X → Open / close gripper (pick objects)
← / → → Rotate gripper for alignment
C / V → Move robot base left / right
Common beginner mistakes:
• Pressing keys too fast
• Holding multiple keys together
• Not checking camera view
• Overshooting the object
💡 Simple rule for beginners:
Small movements correct timing = better control
How to improve quickly:
• Move step by step
• Observe before acting
• Reduce unnecessary actions
• Practice same task repeatedly
Why is Control Important?
Without good control:
• Objects can be missed
• Alignment becomes difficult
• Tasks take longer
• More corrections are needed
With good control:
• Movements become cleaner
• Tasks become more efficient
• Fewer adjustments are required
• Accuracy improves
👉 The more you practice, the better your control becomes.
Join the PrismaX family
Follow the official @PrismaXai account so you never miss any updates
Join the PrismaX Discord : discord.gg/prismaxai
Teleoperation platform : app.prismax.ai
@vivianrobotics @MaxC16134
Jun 8

gPrisma Familia❤️
In every community, people leave their mark in different ways.
some contribute ideas, some help others grow and some quietly stay consistent behind the scenes. What makes PrismaX special is the diversity of people who come together with a shared interest in innovation, creativity and AI.
That's the inspiration behind this PrismaX ID Card.
A simple concept that represents more than just a profile. It reflects the journey, the experiences, the contributions and the connections built within the community over time.
Big appreciation for the PrismaX team for building and growing a community where people can learn, connect and grow together
Every member has a unique path and every path adds value to the ecosystem.
What's your PrismaX story?
Join the PrismaX family
Follow the official @PrismaXai account so you never miss any updates
Join the PrismaX Discord : discord.gg/ahZB27Sn
Teleoperation platform : app.prismax.ai
@vivianrobotics @MaxC16134
96
3
122
11,924

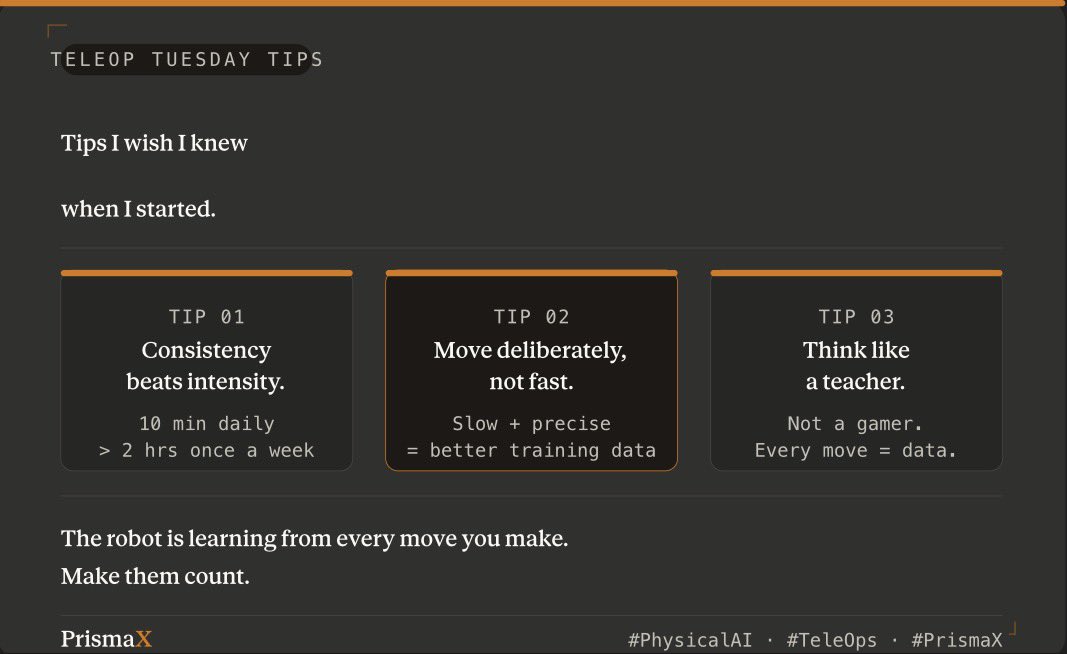
Been teleoperating on @PrismaXai for a while now.
Here are the tips I wish I knew when I started.
If you're just getting into teleoperation — this thread is for you.👇
🔗 app.prismax.ai
#PhysicalAI #TeleOps #PrismaX
3
1
34

Jun 10
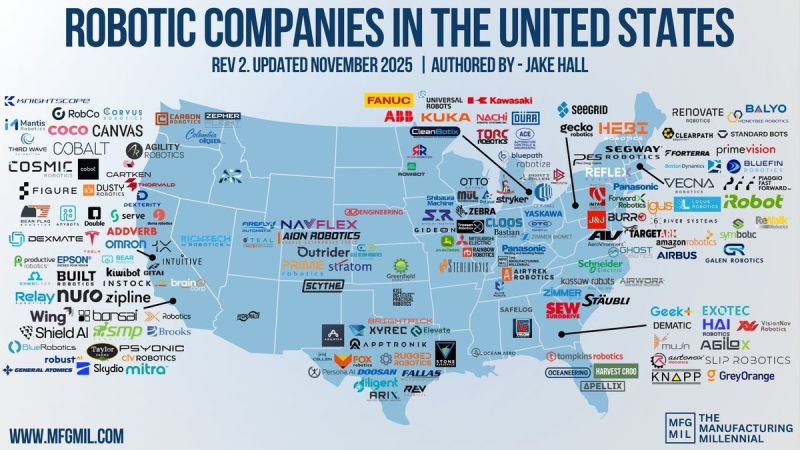
🇺🇸🤖 Hardware and autonomy stacks all over the US robotics map (via @MFGMillennial / MFGMIL).
The missing box is the “data human‑in‑the‑loop” layer for Physical AI: egocentric video, teleops, real‑world ops.
That’s where Remotics plugs in.
1
1
2
34

Jun 10
everybody poops. i mean, teleops.
Jun 10

An interesting observation from #ICRA2026 : the industry keeps getting caught hiding its teleoperators, while the two papers that each took two awards are both about human demonstration data.
The human in the loop isn't robotics embarrassing secret. It's the engine.
66

Jun 10
Why will this actually work?
Operator teleops a real robot → High-quality data is captured → Foundation model is trained on that real data → Smarter robot gets deployed to users → Attract more operators attract more data
Every single session makes the next robot smarter.
1
1
15

This gets cool once you have an AI teleoperating robotic arms around
the world without the AI leaving
your secured servers.
Gets wild when Teleops aaS allows
AI with specific experiences to
operate i.e. a dogbot in a dangerous
environment.
1
26

Jun 8
Yes, real data is very important for the development of robots and teleops.
25

Jun 8
Me Too! I love teleops. It is the reason I join this industry. I am very happy that people pay much money for me to play with them.
9
Jun 8
The drawback is that teleoperation is a bit slow (humans are rarely as fast at completing tasks through teleop as they are natively), and there are some Capex costs associated with bringing up the hardware.
#teleops #robotic #ai #prismaX
Visit us on:
prismax.ai/
29

Jun 7
What if the A and B options are clearly synergistic - e.g. Figure AI plus OnlyFans? They could start via teleops/data collection and then the Figure AI companions could provide “augmented” services
171

Jun 5
Completely agree with the thoughts here. Every major ML sector has been solved via a well-developed flywheel and embodied AI just doesn’t have one yet. Every hour of robotics teleops/UMI data was paid and worked for— we’ll never reach common crawl scale this way.
If you’ve been paying attention closely, you’ll notice a lot of the people in world models are coming from AV… it’s because the AV flywheel has gotten so good that it’s essentially internally solved.
Also regarding the arch points here, it’s undoubtedly true. Language-based backbones have no place in action policies. Language is a hyper-compressed representation of reality. In no way is it possible to truly understand the dynamics of the world through language alone.
Jun 5

undoubtedly, world models > VLAs
here’s why world models are winning and what it means if you’re building in robotics:
1. VLAs worked around the robotics data gap by bolting robot actions onto a vision-language model. robot data is catching up. there’s no problem to work around anymore.
2. world models understand physics, not just pixels. space, motion, causality, affordances. a VLA sees an image and predicts an action. a world model simulates what happens next and plans through it.
3. the data flywheel finally makes sense. the robot collects data, the model gets better, the robot gets better, repeat. 1X, Generalist, and π0.7 are all converging on this loop.
4. you don’t need millions of hours to start. 1X trained on 900 hours of human video 70 hours of robot data. architecture and data quality beat volume.
5. for robotics founders: fine-tuning off the shelf is fast but it’s a ceiling. the teams training from scratch on their own data are compounding. that gap only grows
5
302
Jun 5
We spent last 3 months working with a Unitree G1
Humanoids are not fit for real world deployment YET
The real problems no one talks about:
1️⃣ They overheat after 15m of work & need to rest 45m
2️⃣ They're weak; G1 can't carry a full tray or spin a valve
3️⃣ Battery doesn't last longer than 1-2 hours
4️⃣ Hand dexterity is insufficient (hard to grasp a bottle)
5️⃣ Teleops lag makes precision work unreliable
6️⃣ Hardware deployment cost don’t justify ROI
Humanoids today can’t replace full-time labor 👷
They can’t be deployed without additional labor
But here's what matters 👇
Hardware is improving very fast 🦿
In 12–24 months the picture will look different
H2 & Walker S2 are much better fit for industrial tasks
They still won’t replace a full-time labor 👷
But can do the most dangerous tasks humans do
And minimize workplace fatality ⚰️
Despite the challenges, I'm bullish on humanoids 🦾
They will do everything humans can do
They will be more flexible than specialized robots
They will be mass produced at low costs
But we are still very early
13
10
65
24,120

Jun 4
Remoroo collects data autonomously for robotics models via automated task executions.
The way companies do robot data collection today is either through teleops, which is expensive and very slow, or ego-centric data, which is weak because it does not easily transfer.
They do this by combining three things:
- A physics-based planner for motion and safety
- The Remoroo research agent reading the world and making high-level decisions, like “move to point A” then close the gripper.
-A world model that tunes the dexterity needed to actually complete the task
Congrats on launch @AdhamGhazali !!
Jun 4

Right now, getting a robot to do one complex task takes an army of people. Watching it. Correcting it, Labeling everything. Thousands of hours.
not any more
introducing a new Remoroo capability:
autonomous data collection from a single prompt.
1
3
48
9,046
Jun 3
TLDR on @rewkang’s podcast w/ @APompliano
FIGURE🦿
Andrew came across @Figure_robot deal in 2023
Had no experience investing in Robotics
So asked VC friends for advice
Most were skeptical and told him to pass
VC robotics bets hadn’t produced many winners
US🇺🇸 VS CHINA🇨🇳
Andrew evaluates robotics firms in 3 categories:
1. Manufacturing
2. Hardware design
3. AI capabilities
China is the clear winner in manufacturing
China is leading in hardware design too
US only has Figure/Tesla
China has 100s of diff specialized hardware designs
US has an edge over AI capabilities
AI capabilities are critical cause without brains
Robots are useless
Andrew thinks tech produced ≠ market cap
BYD sells more cars than Tesla
But BYD mcap is 10th of Tesla
US robotics companies offer higher mcap potential
HUMANOIDS VS SPECIALIZED ROBOTS 🤖
Andrew agrees specialized robots are more effective
And their adoption will be earlier than humanoids
Argues that humanoids can be mass produced cheaper
The world is not static so flexibility will be valuable
ROBOTICS TRAINING DATA 🕶️
World models have changed the game
They are trained on internet video data
Despite not as good as teleops/egocentric/sim
They are still very valuable
And there are loads of them online for free
There is still need for egocentric data of specific tasks
But the scale of data needed to be collected is
Lower than expected compared to 9 months ago
JOB DISPLACEMENT 👨🔧
Andrew thinks job displacement is real
Cognitive jobs will be displaced by digital AI
Physical jobs will be displaced by physical AI
UBI is not optional but necessary
ROBOSTRATEGY $BOT
OpenAI and Anthropic went nuts in a few years
If you had invested in top AI companies few years ago
You would have outperformed the best seed funds
Same vertical takeoff will happen for robotics
Robostrategy is a publicly trading closed ended VC fund
It is currently trading at a premium to NAV
NAV premium allows them to raise more capital
Via issuing more shares accretively to shareholders


Not enough people are talking about physical AI and robotics.
I sat down with @rewkang, one of the best investors of the last decade, to discuss his massive bet on humanoids and robotics.
He breaks down the industry, the addressable market, multiple leading companies, and why he launched a publicly-traded fund ($BOT) focused on investing in the top private robotics companies.
YouTube: youtu.be/Q_UWD5aoJkc?si=_E7l…
Apple: podcasts.apple.com/us/podcas…
Spotify: open.spotify.com/episode/4L6…
TIMESTAMPS:
0:00 - Intro
1:28 - Why Andrew shifted from crypto to humanoid robots
3:58 - How big is the total addressable market?
8:08 - Building conviction — the $19M bet on Figure AI
16:06 - US vs. China — who wins the robot race?
28:08 - General purpose vs. specialized robots
31:05 - Where does training data come from?
40:24 - Humanoid robots in your everyday life
43:27 - Can Tesla & Elon win the humanoid race?
46:19 - Job displacement & UBI
51:15 - RoboStrategy — the publicly traded venture fund
1:11:17 - What is exciting about Apptronik?
1:13:24 - Addressing the critics
8
3
42
4,515

Jun 1
Teleoperation in the PrismaX Project
PrismaX is building a decentralized platform for physical AI, connecting robots, real world data, and human intelligence.
At its core is teleoperation (teleops), a system that lets humans remotely control robots in real time.
What is Teleops at PrismaX?
Teleoperation allows community members (Amplifiers) to take direct control of physical robots (starting with tabletop robotic arms) from anywhere with an internet connection.
Operators perform tasks like pick-and-place, contributing human dexterity and judgment where AI still falls short.
What makes @PrismaXai unique is turning teleops into an open, incentivized protocol:
- Standardized interface for easy adoption by robotics companies
- Token rewards, staking, and bonuses for high-quality performance
- Rich video action data generation to train better foundation models
This creates a powerful flywheel:
more teleop → better data → smarter robots → more deployment → even more data.
Why It Matters
Real world robotics lacks high quality training data. Teleoperation solves this by producing precise, labeled, embodied demonstrations that help models learn manipulation and planning in messy physical environments.
It serves as a bridge from today’s human-controlled operations to tomorrow’s full autonomy.
Current Status and Future
Since launch, users can remotely operate real robots and earn rewards through an engaging Tele-op Arcade.
The platform emphasizes community participation and decentralization.
Looking ahead, PrismaX plans to expand to more robot types (including humanoids), advanced data marketplaces, and stronger evaluation systems.
By creating open standards, it aims to accelerate the entire robotics ecosystem.
16
5
39
218

May 31
smart indirect approach to data collection
but aren’t teleops datasets *too tied* to the hw they operate remotely?
1
2
816

May 31
Sometimes all it takes is a small reminder that the world around us is alive.
Not everything is measured by speed. Some things require attention. Some require patience. And some only grow when they are given a little care and time.
TeleOps is built on a similar principle. Through remote operation, human operators help robots perform tasks in real-world environments where precision, decision-making, and adaptation to unexpected situations are essential. Human oversight enables these systems to operate safely and effectively in scenarios where full autonomy still has room to improve.
Every teleoperation session generates valuable data about actions, environments, and system responses. This data helps train AI models, improve navigation algorithms, and prepare robots for greater autonomy in the future. Step by step, these interactions are helping build the foundation for the next generation of robotics.
@PrismaXai

May 19

Happy to share that I have a new role at @PrismaXai I sincerely thank the team and community for their trust, support and the opportunity to grow with the project. Thank you very much @vivianrobotics and @MaxC16134 for the opportunity to be a part of this journey. Thank you to everyone who helps, creates and moves this ecosystem forward - every step brings a new experience. There is still a lot of work ahead, so I will continue to work, develop and do even more))
@PrismaXai
24
86
1,787