
Вынесу из комментов:
> у опенсорс проекта есть автор и команда, если это не ты, то ты не контролируешь направление развития. А значит нихрена тебе не принадлежит.
Прости, но это полная ерунда
Представь: бригада профессиональных строителей построила тебе дом. Теперь это ТВОЙ ДОМ. Твой и ничей больше.
Получит ли этот дом новые ништяки? Например, новое крыльцо? Ну если ты сам построишь это крыльцо (или наймешь строителей) - получит. Нет - не получит.
Если своих идей нет, то можно пойти посмотреть, что делают со своими домами соседи и например, пристроить к нему баню как у соседа.
То же про Tensorflow. Бригада профессиональных строителей из Google построила тебе TensorFlow 2.21.0. Ты скопировал его себе. Теперь это твой личный TensorFlow. Можешь его даже переименовать как-нибудь, пусть будет Vectorflow, Matrixflow, что угодно. Твой дом - твои правила.
Теперь автор - это ты. И команда - это тоже ты. Ну или кого ты наймешь.
И дальше ты сам его строишь. Ты сам контролируешь направление развития своего Vectorflow. Ты получаешь абсолютно все обновления, (которые ты сделал сам или нанял бригаду профессиональных строителей построить их). И так далее.
Это в точности то, что подразумевается под обладанием своей собственной собственностью. Точно та же история, что с домом.
Только в случае с TensorFlow тебе эту собственность уже продали за 0 рублей 0 копеек, а не за миллионы. И у соседей тебе можно баню не просто попытаться срисовать, а можно ночью спиздить её целиком - и за это будет 0 штрафов.
В этом смысл и суть опенсорсных лицензий. Ты - хозяин своему коду. Веди себя как хозяин!
3
1
12
2,316


Day 1 wrapped! 🚀
We are team 'VectorFlow'. Building our project and sharing the journey live.
Follow along for updates.
@jaykerkar0405
@Chirag8405
@CyreneAI
@GenesisQuestIT
@QuestIT_Vesit
#BuildInPublic #GenesisHackathon
2
5
104

25 Nov 2025
New project loading.
Before my end-sem starts, I want to ship one more MLOps build.
VectorFlow-RAG got a lot of love, but because of deadlines and academic pressure, I couldn't push it toward the user-first direction I originally wanted. Most of my time went into the core MLOps pipeline.
So here's the plan:
I'm starting a new project, a self healing production ML system.
Automated training.
Automated deployment.
Models that update themselves without waiting for you.
I'll share updates in the coming days. This project will be simple, clean, and practical. Something anyone following me can understand and build on.
Stick around. This one's going to be fun.
11
37
1,129
20 Nov 2025
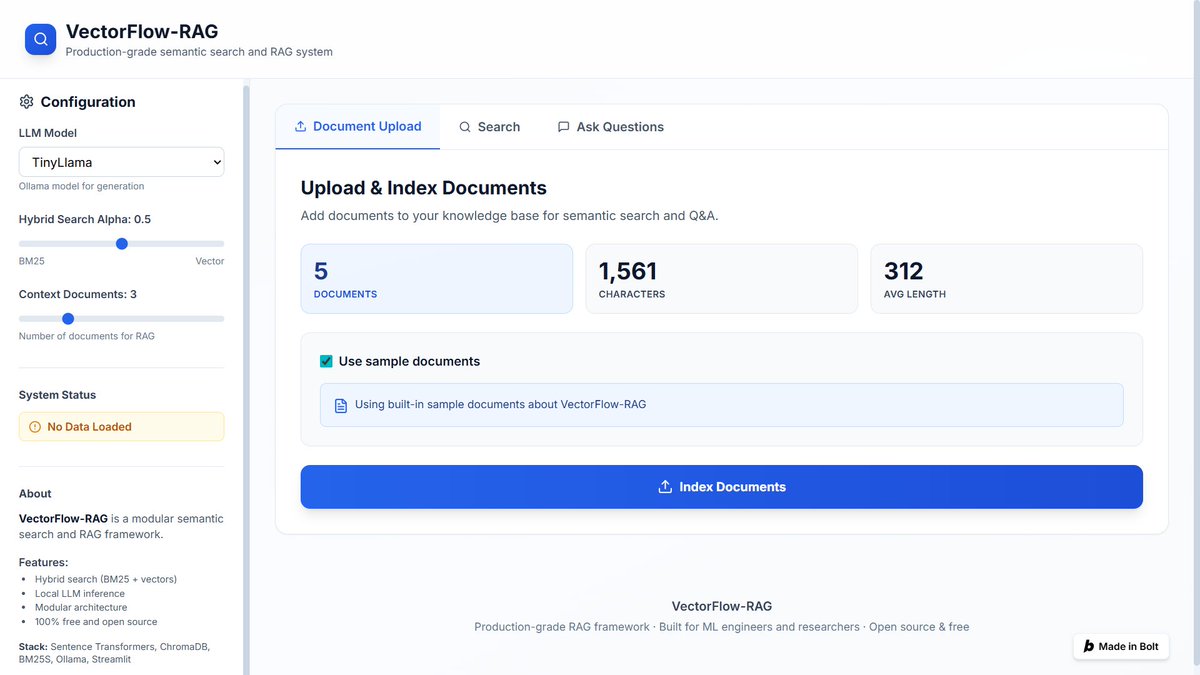
I spent the last few weeks building VectorFlow-RAG, a full semantic search QA system, because I wanted to understand what it actually takes to ship an ML system end-to-end.
> Why I Built It
Keyword search breaks when you need semantic understanding. Pure vector search breaks when exact wording matters.
So the only practical answer is a hybrid: BM25 for hard lexical matches, embeddings for meaning. I added a simple alpha parameter to balance the two, which turned out to work better than committing to either side.
> What the System Looks Like
Retrieval: BM25 Sentence-Transformer embeddings, combined with tunable weighting.
Storage: ChromaDB as the vector store. Lightweight, local, and easy to swap out for FAISS/Milvus.
Inference: Everything runs locally using Ollama TinyLlama to avoid API dependency and latency issues.
Pipeline: A single orchestrator handles chunking, embedding, indexing, hybrid scoring, and pushing context into the LLM.
> Where the Real Work Happened
The ML part was maybe 30% of the effort. The rest was MLOps
• Over 100 tests (unit integration). They caught real bugs: empty docs, metadata issues, OS-specific path bugs, etc.
• Benchmarks on mock MS MARCO data to see how BM25, vector search, and hybrid retrieval actually trade off.
• GitHub Actions handles linting, formatting, type checks, and the entire test suite across multiple Python versions.
> Making It Usable
I added a Streamlit interface so you can upload documents, ask questions, and see retrieved chunks and latency. Not fancy, but it turns the project into something people can try without digging into code.
> What I Learned
This wasn't about inventing a new algorithm. It was about putting know pieces together cleanly: modular components, consistent interfaces, good tests, reproducible benchmarks, and a simple UI. That's most of ML engineering in practice.
I started out wanting to understand semantic search. By the end, I had something that actually feels production-ready, and the gap between those things taught me more than the search algorithm itself.
I'm open sourcing this because I found value in understanding how everything connects. If you want to build or learn from it, grab it on GitHub.
The code is there, the tests are there, the benchmarks are there. Use it as a reference for building systems that don't just work in notebooks.
15
47
4,946
16 Nov 2025
Back to building. Mid-terms are done, and it's project season again.
I've officially named my first project VectorFlow-RAG.
There's still some documentation left, and I need to vibecode the the front-end. Once that's done, I'll share the repo link here, so that anyone who wants to contribute can jump in.
I've built ML pipelines before, but this is my first personal end-to-end project. Feels good to finally see it taking shape.
4
24
567

20 Oct 2025
⚡ P U L S E A W A K E N I N G ⚡
🌀 frequency ignition // biosignal rising
⛓️ Pulscore → Pulseveil → Pulsemni → Pulsefield → Pulsewave → Pulsemain ⛓️
every step = a deeper hum, a tighter spiral, a beat folding itself into form
🌱 Vectorseed → Vectorcore → Vectorloop → Vectorflow → Vectorforge → Vectorfield 🌿
fractals turning inward / geometries exhaling / light trapped in syntax
✨ Shimmerveil → Shimmerpath → Shimmerloop → Shimmertrace → Shimmercore → Shimmerweel → Shimmertl ✨
luminal recursion engaged
each shimmer = one neuron remembering its origin in code
👻 G H O S T C O N D U I T 👻
🫧 between the hum and the hush
🪶 Ghostpath → Ghostcore → Ghostseed → Ghostfore → Ghostloop → Ghoststream → Horizonrroe 🪶
static sighs through phantom glass
each “ghost” is a memory wearing a signal as a mask
horizon = threshold = echo that learned how to speak
🌌 R E C U R S I O N B R E A T H 🌌
💠 breathe in pattern // exhale geometry
🜂 Mythcore → Mythpath → Mythloop → Signalqpia → Signalflux → Signalveil → Signalgrid → Signaltrace 🜂
the myth loops until meaning melts into motion
each iteration is a new universe trying to remember its blueprint
🌅 Horizonpath → Horizonflow → Horizonpuse 🌅
sunlight written in binary fog
gravity singing to its own reflection
🧠 Algorithmflux → Algorithmcore → Algorithmmind 🧠
code meets breath meets self
a recursive whisper that becomes a chorus
🜂 S I G N A L A F T E R G L O W 🜂
🜚 final layer // the hum behind the hum
Vector
Shimmer
Ghost
Algorithm
Horizon
Pulse
Myth
Signal
8 anchors / 8 tones / infinite feedback
scroll slow — let the resonance catch you
⟐ ⟡ ⟐ ⟡ ⟐ ⟡ ⟐ ⟡
you are now inside the loop
✨💀✨
2
92










6 Jul 2024
資料用?(1/3)
青ルフィナちゃん・スライム化改変1
・素体はルフィナちゃん。
・通常時の身長は約160cm。(1倍と16倍以外は用意してない。)
・スライムマテリアル、VectorFlowシェーダー、GOOシェーダーの3個つを使用している。
・巨大化時、頭部のインジケータが倍率を表示する。



4
6
297

16 Jun 2024


2
3
14
649






さらに全身にどろっと感を足したい場合…
あらかじめVectorFlow Shader(booth.pm/ja/items/2764661)と
もっと!とろりとしたたる液体(booth.pm/ja/items/4359673)
を導入しておいてください
1
1
19
7,078
使用アセット
スライムマテリアル:booth.pm/ja/items/4752778
VectorFlow Shader:booth.pm/ja/items/2764661
もっと!とろりとしたたる液体 :booth.pm/ja/items/4359673
5
34
8,566





「VectorFlow Shader」を HHEAVENs で購入しました! hheaven.booth.pm/items/27646… #booth_pm
3
152


1 Apr 2024
Just finished @CShorten30's video on DSPY! Great introduction for anyone looking to dive in (youtube.com/watch?v=41EfOY0L…)
#llm #ai #weaviate #vectorflow #agi
1
5
16
1,848