
I deal with the larger portions by cooking for 4-6 each weekend and freezing onesies. Great pre-plan for a busy work week. And after a few weekends of megameals, I have a crisper of options on demand.

Weekends don't fix a broken life. You need a life you don’t constantly need a break from.
1

Also, they play about 30-40 shows a year. Only one or two weekends a month. And it’s never the same. Not 50 a year
3



Vedat orakçı retweeted

seems like weekends for base:0x721b072dbb616f29eea73ac004e03fd4e884bba3 is a casual self sovereign takeover backatchu of the recent US govt. ban of @AnthropicAI's Fable / Mythos sitch.
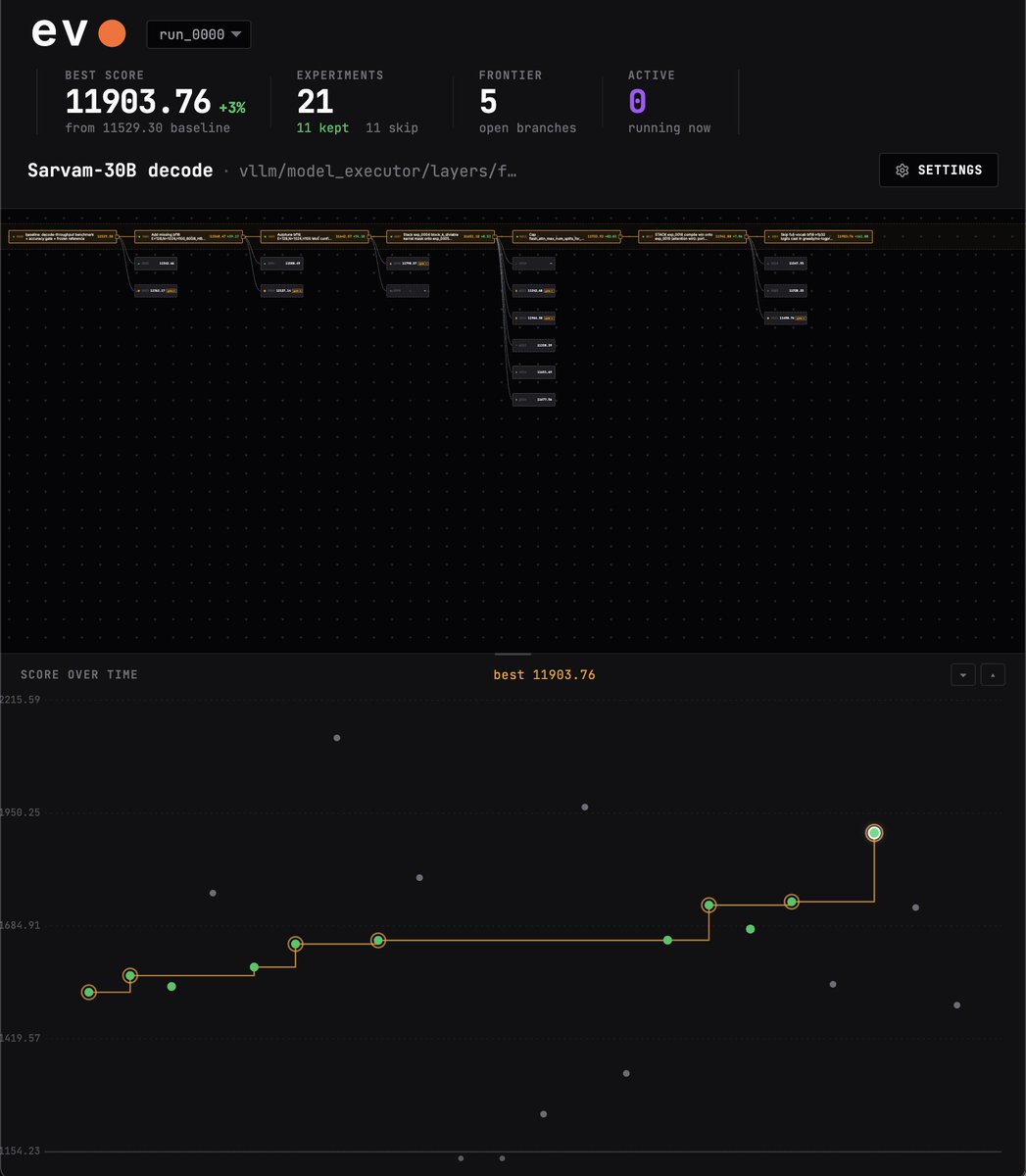
TL;DR @EVO__HQ in response autonomously optimized SarvamAI’s Indian inference code and ran 10 hrs of experiments. Found ~3% decode throughput gain.
Institutional gatekeeping in shambles. agents wrenching real efficiency from existing open models, no new tech needed. The number runner may be small batch but is demonstrative of something huge and telling. and these censors will only accelerate such resistance and build. wild just unreal.

weekend @evo__hq activities: given the recent sovereign-AI narrative (amidst anthropic's fable pullback), i wanted to see if evo could help make some of the indian models we have better in whatever way.
so i kicked off an autoresearch run on evo to see if @SarvamAI's 30B decode throughput could be improved, at bf16, on a single H100.
currently 10 hours in. so far, evo seems to have found ~3% improvement.
the metric is geometric mean tok/s across batch sizes 64 / 128 / 256, measuring steady-state decode only. prefill is timed out, so this is purely per-token decode rate on a fixed workload.
evo also ensures that anything that got faster by changing outputs, lowering precision, or messing with MoE routing was rejected by the accuracy gate.
the gate compares each candidate against a frozen baseline on both next-token distributions and actual decoded tokens. if argmax agreement or logprob drift moves meaningfully, the change is rejected, even if it is faster.
very imp caveat: these are experiment-harness numbers, not production serving numbers.
the gain still needs to be validated in a real serving setup before anyone treats it as real capacity.
i also havent done an external audit for any benchmark hack the agent may have done.
a potential ~3% bump is a potentially a pretty significant improvement for someone like sarvam at that scale. decode is a major part of inference cost. a ~3% decode-side throughput gain at identical accuracy means more capacity, or fewer GPUs, without changing the model.
i also want to s/o to @vishnuvig of jarvislabs.ai / @e2enetworks for compute support. i am trying to use more and more compute from indian providers as much as i can and give feedback to improve the experience as well
2
1
6
551
yamuriste retweeted

Weekends were made for paperhands to sell on the low volume, if you understand what you have in your hands you are betting here.
Next week is going to be amazing for crypto, but the real deal is the alt season that is going to be here in some months.
Change your families life, do the right thing for once in your life. Add more.
7
25
45
552
Shizukana 🐦⬛🪽| Crow Limbo Guardian retweeted

Weekends are for vibrating braincages
1
1
2
11
景山優木 retweeted

The progress keeps coming for the @astonmartin @Heart_Of_Racing Valkyrie after this weekends @24hoursoflemans where the #007 secure the cars best result to date at the prestigious event
the-advantage.org/2026/06/th…




1
1
44



Alex retweeted
Looks like a great spot to keep adding.
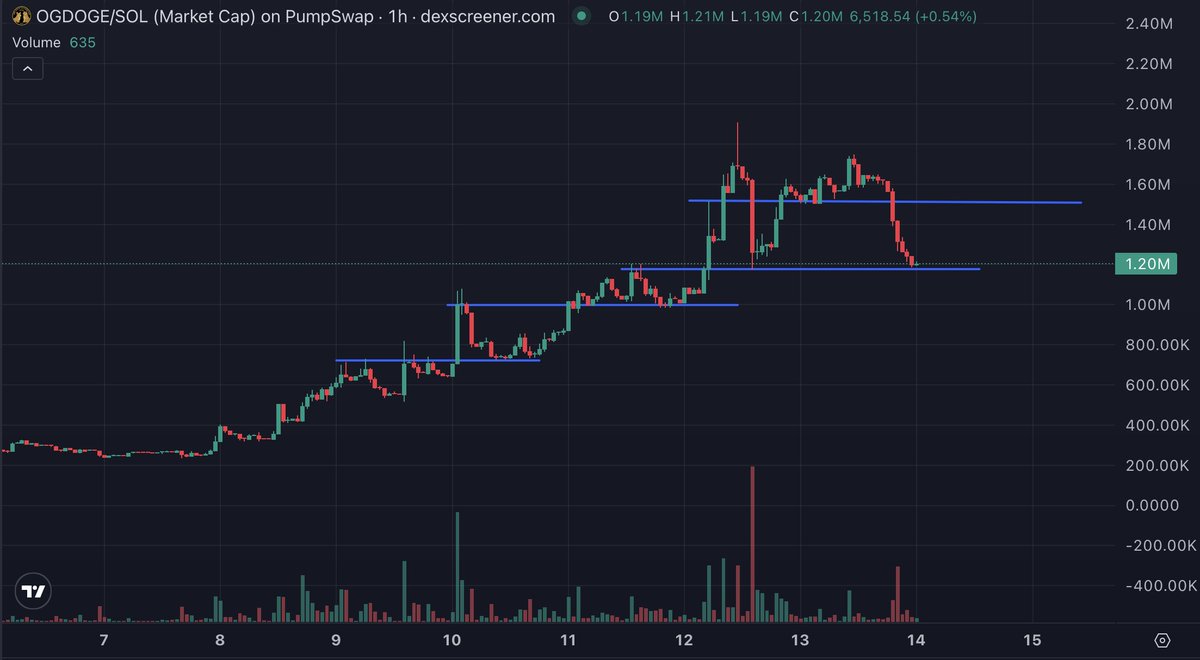
Low volume weekends make paperhands go away on crypto, next week will be so bullish for the markets, imagine what happens with $OGDOGE once everything starts to go up again.

5
22
44
669



Farm City on weekends is basically an exhibition of every type of babe Abuja has to offer
2

