
STARTING NOW UNTIL WEDNESDAY (17th), @GFuelEnergy IS DOING A 40% OFF CODE BOOST IF YOU USE MY CODE “TECHHD” 😱🔥
WORKS ON ENERGY TUBS, HYFRATION FOCUS, COLLECTOR’S BOXES, ETC! 👀 USE THE LINK GET ACCESS TO IT!
gfuel.com/TECHHD
#gfuelenergy #gfuel #codeboost #discountcode #gfuelcode #ad
1
2
26

NEED KOL/AFFILIATE UNTUK BRAND SKINCARE!
Detail
Syarat: Beauty creator, folllowers TikTok minimal 600
Brand: Neutrogena
SOW: 8VT YC (Kerkun) Codeboost
Product: 2 product value up to 500K
Sistem: Barter
Periode: H 14 setelah product sampai
Link gform
forms.gle/MiqgHQ23DrU1xySB9
50
SOW: 8VT YC (Kerkun) Codeboost
Product: 2 product value up to 500K (Visible Repair Regenerating Cream/Hydroboost Hyaluronic Water Gel/Ultra Sheer Sunscreen SPF 50 )
Sistem: Barter Value
Isi link gform ini yaa!
forms.gle/MiqgHQ23DrU1xySB9
31

Apr 2
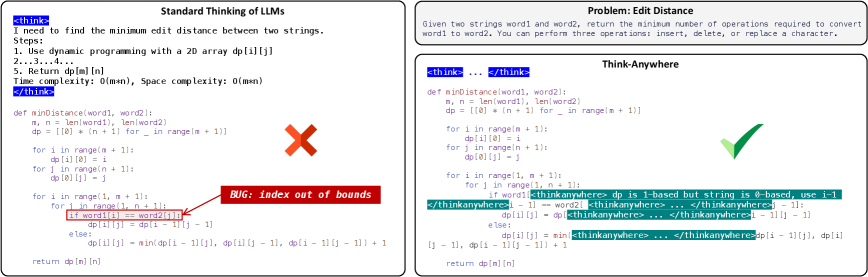
Current reasoning LLMs think everything upfront before writing code. But developers don't work that way. We pause during implementation when things get tricky.
Think Anywhere, from Xue Jiang, Yihong Dong, Ge Li and collaborators at Peking University and @TongYi_China (Alibaba Tongyi Lab), lets LLMs invoke reasoning at any token position during code generation, not just before it.
The method uses cold start training reinforcement learning (GRPO) so the model learns WHEN to pause and think. Analysis shows it triggers reasoning at positions with high entropy, exactly where bugs tend to appear.
Results on Qwen2.5 Coder 7B: 9.3% absolute improvement over the base model across LeetCode, LiveCodeBench, HumanEval, and MBPP. Beats both distillation methods (OlympicCoder) and other RL approaches (CodeRL , CodeBoost).
The model also generalizes to math reasoning benchmarks without any math training. Code and data are open source.
1
3
87

21 Nov 2025
Jeff wants to know why the hell you aren't using code KAOTIC20 for your @ADVANCEDgg order yet. Its creator support week! 20% off for you and I get more of the commission! It's a win-win!
#advancedgg #partner #codeboost #creatorsupportweek

5
316

12 Sep 2025
Want to boost your coding skills quickly? Stop memorizing build challenging projects daily.
Here’s how I went from beginner to confident developer in three months:
- Solve real problems
- Code daily
- Share and get feedback
Reply 'CodeBoost' for my project list and resources!
3
8
89

6 Jul 2025
🚀 Kickstart your DevOps journey at just ₹399! 💻✨
Get "The Ultimate Python Bootcamp: Learn by Building 50 Projects " on Udemy with this exclusive coupon! 🔥
🎟️ Code: CODEBOOST
⏳ Valid for 5 days only!
Don’t miss out—enroll now!
#Python #UdemyCourse #PythonCourse #HiteshChoudhary #Udemy #BestCourse

3
1
46
3,875

23 May 2025
Todo un éxito el primer #CodeBoost que hemos organizado en la @ETSISIupm, gracias a todos los participantes por venir! #PIE24




3
131
14 May 2025
Concurso de programación #CodeBoost en la @ETSISIupm organizado por el Grupo de innovación GIETEMA. Será el viernes 23 de mayo a las 16.00, una buena forma de terminar las clases y ganar un dron. Inscríbete antes del jueves 22 de mayo. Más info en blogs.upm.es/codeboost

1
6
9
617

13 Jan 2025
🌟 CodeBoost is back! Calling all innovators 🌟
Learn startup tools, score GitHub Student Dev Pack, and connect with campus tech communities. Transform your ideas into reality!
📆 25 Jan 2025
⏰ 08:00 - 17:00 HRS
🔗 bit.ly/codeboost2025

2
3
190

10 Jan 2025
udah deal sama kol yg engagementnya bagus tapi tiba” pas up konten produk viewsnya ngeflop ga bisa naik padahal udah pake codeboost 🙂☝🏻
1
3
200

1 Jan 2025
1⃣. Co-hosted CodeBoost2024 : Propel your Startup Tech on January 20th at @coict_udsm! Despite heavy rains 🌧️, over 60 passionate participants joined us to level up their startup journeys! 🙌 A big thanks to our amazing sponsors @GitHubEducation , @NeuroTech_HQ , @udicti, and @UdsmFinhub for making it all possible! 🚀
💡 What we did:
➡️Startup Essentials: Led by @MbarakaShakila from @StartHubAfrica, we tackled idea creation, validation, and implementation. Attendees got hands-on with group tasks and presentations building a solid foundation to launch their startups! 🌱
➡️Landing Page Mastery: @RohitGulam guided us through creating impactful landing pages using WordPress—because your startup’s online presence matters! 🌐🦾
➡️GitHub & MVPs: With @Pheogrammer & @daniel_mawalla, we unlocked the power of GitHub for fast MVP development, giving students the resources to build and scale! ⚙️📚
🎉 The event was filled with laughter, games, tasty bites, and valuable networking opportunities! 💬
Missed out? Don’t worry—join us for CodeBoost 2025. Register here: bit.ly/codeboost2025 🙌
Thank you to all the organizers @AnenBIsaac @daniel_mawalla @__AlexMkwizu @chax255 and participants who made this a success! 👏




1
2
9
195
7 Dec 2024
🚀 CodeBoost is back! Calling all innovators 💡
Learn startup tools, score GitHub Student Dev Pack, and connect with campus tech communities. Transform your ideas into reality!
📆 25 Jan 2025
⏰ 08:00 - 17:00 HRS
🔗 bit.ly/codeboost2025

2
4
201

3 Jul 2024
Debugging code all night? Our new Adidas CodeBoost™ sneakers are perfect for those marathon coding sessions. Comfort for your feet, even when your code isn't running. #AdidasForDevs #CodeInComfort
1
2
11
581

12 Apr 2024
Some extensions to increase your productivity as a coder:
CodeBoost
SyntaxSavvy
CodeFlow
DebugBuddy
CodeCraft
CodeSync
CodeGenius
CodeZen
2
112

23 Feb 2024
Uncover software secrets with Flame Graphs! See how your code runs, fix issues fast. Read our guide! 🚀middleware.io/blog/flame-gra…🔥 #flamegraphs #codeboost #easytech #techtips #developers #devopscommunity #softwaredevelopment
4
65

21 Jan 2024
🎉 CodeBoost was a blast! 🚀 From tasty bites to laughter-filled games, we had it all. Missed out? No worries! 🌟 Join us next time for more fun, learning, and excitement. Stay tuned! Congrats to all the organizers tagged below!🍕🤩 #CodeBoost #NextEventComingSoon



2
26
567
21 Jan 2024
#CodeBoost Session 3📈: GitHub and MVPs - the keys to rapid startup development. With @pheogrammer and @daniel_mawalla we unlocked the potential of GitHub and shared valuable resources for Dar's university students. The world is at your fingertips! ⚙️📚 #CodeBoost #GitHubMagic



2
17
251
21 Jan 2024
#CodeBoost Session 2🛠️: Crafting a killer landing page is crucial! Led by @RohitGulam we explored the essentials – calls to action, WordPress magic, and more. Your startup's online presence matters, and we showed you how to make it count🦾. 🌐 #CodeBoost #LandingPageMastery



1
11
180
21 Jan 2024
#CodeBoost Session 1🧠: Led by Shakila from Starthub Africa, we dived into startup essentials - idea creation, validation, and implementation. With engaging group tasks and presentations, the session was a solid foundation for any budding🌱 entrepreneur. 💡 #StartupEssentials



1
13
349