
Apr 13
We’re gradually open sourcing key parts of the codemix stack, first up is codemix/graph - a fully type-safe, realtime, offline-first, reactive graph database that lives in a CRDT (Y.js), written in TypeScript.

1
2
2
247

Feb 18
Speech → Text (Saaras)
5 practical modes:
• transcribe
• translate
• translit
• verbatim
• codemix
Great for call assistants, transcripts and bunch of other things.
Docs: docs.sarvam.ai/api-reference…
Playground: dashboard.sarvam.ai/speech-t…
2
1
10
989
Feb 11
Today we launch saaras:v3
saaras:v2.5 was good.
v3 is faster. more accurate. streaming-native.
what’s new:
• native real-time streaming
• low latency decoding
• higher accuracy on code-mixed speech
• robust to noisy environments
• supports 22 official indian languages english
• ~19% WER on IndicVoices benchmark
5 output modes:
• transcribe (default) → normalized text
मेरा फोन नंबर है 9840950950
• translate → english translation
my phone number is 9840950950
• verbatim → exact spoken words
मेरा फोन नंबर है नौ आठ चार zero नौ पांच zero नौ पांच zero
• translit → romanized script
mera phone number hai 9840950950
• codemix → mixed english native script
मेरा phone number है 9840950950
available via:
• REST API
• streaming API
• batch processing
use what fits your latency scale needs.
production-grade ASR.
built for real indian speech.
Feb 11

Drop 8/14: Introducing Saaras V3, the next iteration of our speech recognition model. We extend our lead in this space with an even more accurate model, particularly for mixed-language and noisy speech.
We have also expanded support for all the 22 scheduled languages of India.
And we now support real-time streaming! In this mode, the model delivers low latency while preserving transcription quality.
sarvam.ai/blogs/asr
3
9
88
3,270

Jan 27
My people and English 😂! To find ijesha man wey no dey codemix Yoruba with English na by connection
2
849

20 Sep 2025
UNILAG,
Lagos State Ministry of Agriculture, Farm service centre Agege (they codemix),
Bab-es- salam orphanage, Ikeja
Gbagada General Hospital (codemix)
1
7
2,674


30 Jul 2025
Euskal Herrian EUSKAÑOLA eta Irlandan GAELENGLISH edo Codemix delakoa.
"Gazte-hizkeratik" urrun, ordezkapenaren hizkera baino ez dena, españolera / frantsesera edo ingelesera trantsizio-aldaera.
👇👇
13 Sep 2024

TXGGaren Blogeko 10. artikulua
Irlandako Conchúr Ó Giollagáin eta Brian Ó Curnáinen eskutik datorkigu.
✏️"Gaeliko "Chic"arentzat gainbehera onargarria"
Irakurri hemen:
telesforomonzonlab.eus/gaeli…
4
7
271

Codemix reserch lo ఇన్ని రోజులు English script la telugu / indian languages rastu unde example samples mida ne relying .
Ippati nunchi hindi script la Telugu rase data kuda important samples annattu
1
1
2
247

18 Jun 2025
Wow! Such a character. She owned the interview from the beginning till the end. This has to be one of the most entertaining episode of #Masoyinbo. It is amazing she didn't codemix. @munahhh_ 👏👏
18 Jun 2025

#Masoyinbo Episode One Hundred and Sixty- Three with Memunat Teslim: Exciting Game Show Teaching Yoruba language and Culture. Watch full video here: youtu.be/hk29R62Vz04
1
6
605


21 May 2025
Yea, I remember her.. aisha kazeem or so. In the earliest episodes, one guy didn't codemix as well.
1
2
29

13 May 2025
Nice trap in … why the rush takes …u keep bouncing out on the beat bro. Love the codemix too. A good producer will do justice tho cos this is defo a mixtape. U got it… real talent 🔥
1
504

6 May 2025
I know he won’t codemix as he doesn’t speak any iota of English but nobody knows it all when it comes to Yoruba language, not even the host 😂🤣
He will fail woefully numbers and certain conc questions. Stay tuned 😅
1
2
519

21 Apr 2025
they should allow him codemix and speak a language he understand
2
10
2,908

17 Mar 2025
The Lady with the highest winning didnt codemix, she just missed about 2 or 3 questions
1
2
5

18 Feb 2025
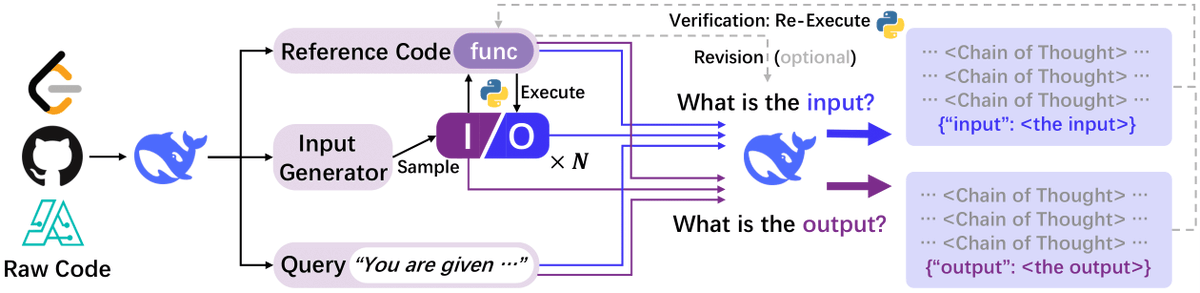
CODEI/O—Condense Reasoning Patterns in Code into a Training for LLMs
Leveraging Code for Advanced Reasoning
While abundant training data exists for tasks such as math problem solving or code generation, many other domains—especially those that require broad logical, scientific, symbolic, and commonsense reasoning—suffer from sparse and fragmented supervision. Without sufficient rich and diverse signals, models struggle to develop robust, generalizable reasoning skills.
The key insight of the paper is that everyday code is a treasure trove of diverse reasoning patterns. Real-world code inherently encodes logical flow planning, state-space searching, recursive decomposition, and decision-making processes. However, the raw code as available in repositories can be too noisy or tangled with syntax-specific details to be directly useful for training general reasoning models. To address this, the authors introduce CODEI/O, an approach that transforms raw code into a structured training signal by converting it into an input–output prediction task.
Transforming Code into Reasoning Data
The CODEI/O framework begins by collecting raw code files from multiple sources, such as CodeMix and specialized subsets like PyEdu-R, ensuring a balance of algorithmic, mathematical, and logic-intensive content. This code is then preprocessed into a unified and executable format where non-essential elements (like visualization commands) are removed. The cleaned code includes a main entrypoint and is refactored to clearly present the core logic.
Next, for each function extracted from this code, multiple input–output pairs are generated. These pairs stem from controlled sampling of input values and executing the code to obtain deterministic outputs. Crucially, the training tasks go further by incorporating Chain-of-Thought (CoT) rationales. Rather than merely predicting the output, the model is trained to express the reasoning behind the prediction entirely in natural language. This decouples the inherent logic from language-specific syntax, allowing the models to internalize universal reasoning primitives.
Incorporating Multi-turn Revision: CODEI/O
While generating coherent reasoning chains is challenging, some predictions may initially be incorrect. The authors address this by introducing a feedback-based, multi-turn revision process—resulting in an enhanced version termed CODEI/O . In this setup, models are not only verified by re-executing the code to check the accuracy of their predictions but are also prompted to revise any errors. The final training sample becomes a concatenation of the initial response and one or more revision rounds. Although the improvements tend to plateau after the first revision turn, this approach still leads to better performance compared to using the uncorrected responses.
The training of models using CODEI/O is organized in two distinct stages:
Stage 1 – Pre-training with CODEI/O:
Models are exposed to a large dataset (with over 3.5 million samples) constructed with the method described above. This pre-training reinforces broad reasoning ability by repeatedly exposing the model to diverse logical, symbolic, and procedural reasoning patterns distilled from code.
Stage 2 – General Instruction Tuning:
Following the reasoning-focused pre-training, models are then fine-tuned using a more general instruction-tuning dataset. This second stage helps models adapt their newly acquired reasoning capabilities to a wide range of downstream tasks, ensuring versatility.
The experiments are conducted on multiple advanced base models—including Qwen 2.5 Coder (7B parameters), LLaMA 3.1 (8B), DeepSeek Coder v2 Lite (16B), and Gemma 2 (27B)—and evaluated across a rich selection of benchmarks. These benchmarks span many domains: commonsense reasoning (e.g., WinoGrande, BBH), numerical and symbolic reasoning (e.g., DROP, GSM8K, MATH, MMLU-STEM), logical problem solving (e.g., GPQA, CruxEval, ZebraGrid, KorBench), and even code output prediction tasks (e.g., LeetCode-O, LiveBench).
Noteworthy Experimental Results
The experimental results underscore several key findings:
Balanced Improvements Across Domains:
Despite being based solely on code-derived data, CODEI/O shows consistent gains across a wide range of reasoning tasks. Unlike baselines that excel in only specific domains, CODEI/O improves performance in symbolic, logical, mathematical, and commonsense reasoning, demonstrating its generalizability.
Effectiveness of Multi-turn Revisions:
Incorporating execution-feedback and a single-turn revision process (forming CODEI/O ) results in further performance enhancements. Although additional revisions yield diminishing returns, the initial revision clearly boosts accuracy without compromising balance across tasks.
Scalability Benefits:
The authors show that increasing the number of training samples and the number of input–output pairs per code sample leads to more robust reasoning abilities. This scaling effect reinforces that the benefits come not just from a larger dataset but from a carefully constructed one that contains diverse, repeatable reasoning patterns.
Ablation Studies Validate Design Choices:
Several ablation experiments demonstrate that separating the prediction of inputs from outputs, retaining even erroneous responses for diversity, and carefully structuring prompt-response formats all contribute to the observed performance improvements.
Conclusion
In summary, the paper presents a novel method—CODEI/O—that condenses diverse reasoning patterns from code into a training framework accessible to LLMs. By transforming raw code into a structured prediction task augmented with natural language rationales and multi-turn revision, the approach effectively bridges the gap between code-specific execution and generalized reasoning. The experimental evaluations across multiple models and benchmarks validate that this method not only enhances specific reasoning capacities but does so in a balanced and scalable manner, opening new avenues for the development of more robust and versatile language models capable of deep reasoning.
1
4
14
1,838

17 Feb 2025
好きな曲と特別な曲と原曲で聴きたい曲は違うので、「原曲で聴きたい曲」のダントツ1位は
「Joker-G CODEMIX-」
です、間違いないです!(強火Joker担)
1
105

7 Dec 2024
Lol,
Codemix is codemix, he always says "e ma so ede miran ayafi yoruba" at the beginning of every episodes
1
30
5,557

2 Dec 2024
She would have gone home easily with 1m if she didn't codemix...
Chai!!!
1
1,524

27 Nov 2024
He knows what he's doing, he dresses like Yoruba man when at home, pidgin-dressed in his normal skit. There's a reason most musician sings in Yoruba or codemix. Its about the consumer
2
457