
We're introducing GLM-5.2, our latest flagship model for long-horizon tasks. It marks a substantial leap in long-horizon task capability over its predecessor GLM-5.1 and, for the first time, delivers that capability on a solid 1M-token context. GLM-5.2's new capabilities include:
Solid 1M Context: A solid 1M-token context that stably sustains long-horizon work
Advanced Coding with Flexible Effort: Stronger coding capabilities with multiple thinking effort levels to balance performance and latency
Improved Architecture: We propose IndexShare, which reuses the same indexer across every four sparse attention layers, reducing per-token FLOPs by 2.9× at a 1M context length. We also improve GLM-5.2’s MTP layer for speculative decoding, increasing the acceptance length by up to 20%
Pure Open: An MIT open-source license — no regional limits, technical access without borders
Supporting long-horizon tasks starts with making long context engineering-usable: the model must maintain quality across long, messy coding-agent trajectories, not just accept more tokens. A 1M context is easy to claim, but much harder to keep reliable under real engineering pressure. To this end, we substantially expanded 1M-context training for coding-agent scenarios, covering large-scale implementation, automated research, performance optimization, and complex debugging. The result is a long-context system that is not only wide in scope, but solid in execution: a practical substrate for sustained engineering work.
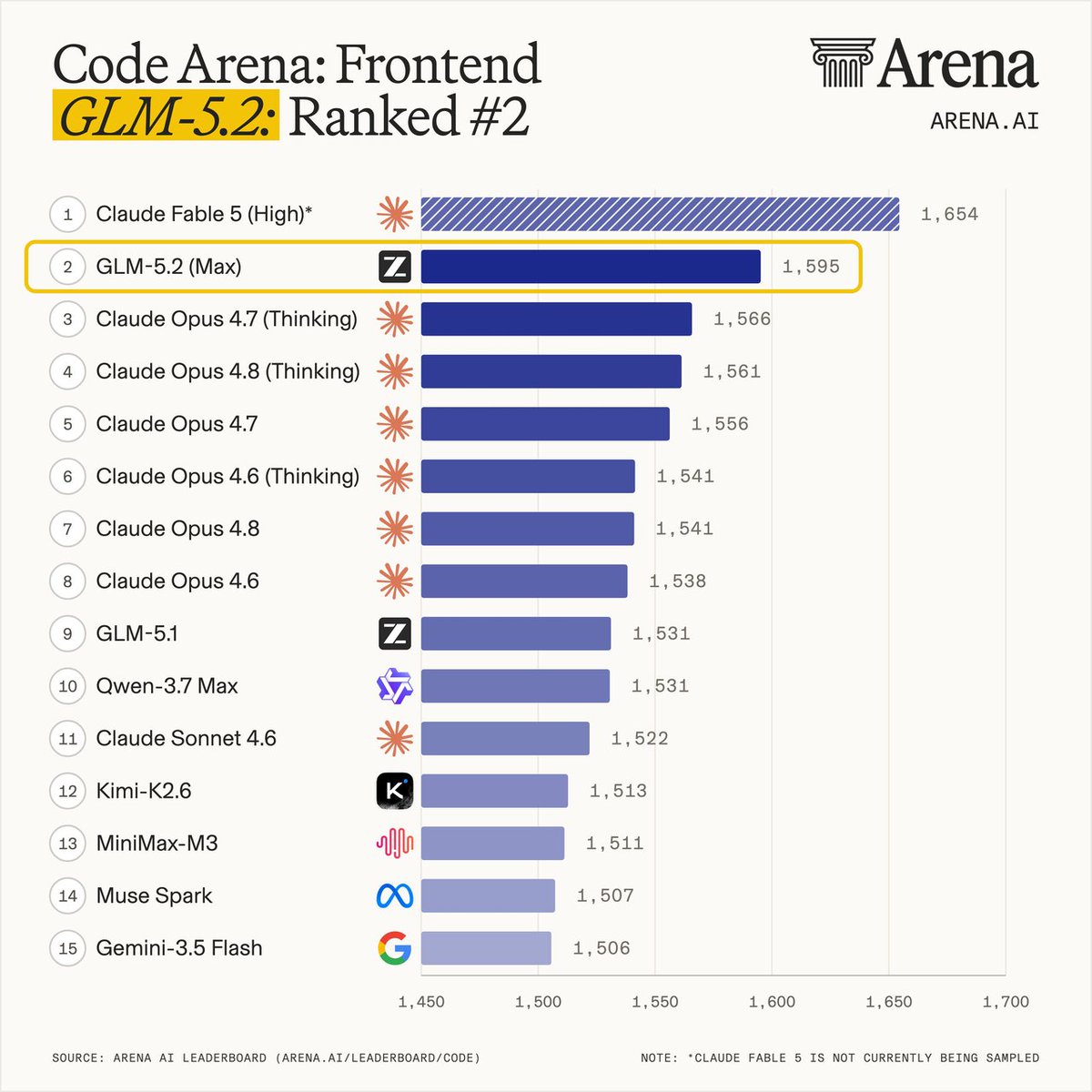
This capability is reflected in GLM-5.2's performance on three long-horizon coding benchmarks. FrontierSWE measures whether an agent can complete open-ended technical projects at the scale of hours to tens of hours, spanning systems optimization, large-scale code construction, and applied ML research. On this benchmark, GLM-5.2 trails Opus 4.8 by only 1%, while edging out GPT-5.5 by 1% and Opus 4.7 by 11%. On PostTrainBench, where each agent is given an H100 GPU and evaluated by how much it can improve small models through post-training, GLM-5.2 outperforms both Opus 4.7 and GPT-5.5, ranking second only to Opus 4.8. On SWE-Marathon, an ultra-long-horizon software engineering benchmark covering tasks such as building compilers, optimizing kernels, and developing production-grade services, GLM-5.2 still has room to grow, trailing Opus 4.8 by 13% while remaining second only to the Opus series. Across all three benchmarks, GLM-5.2 is the highest-ranked open-source model, showing that its 1M context has translated into practical long-horizon delivery capability.

Josep retweeted

Jun 13
แจ้งลบคลิปได้นะครับ🔞 Adults Only (18 )
NSFW Content
All models are 18 adults
Viewer discretion advised
 Etendin_Official
Etendin_Official
79
221
16,181


DIMONAM1 ASD retweeted

Jun 15
I don't think y'all remember what PS1 models look like
Jun 14


247
2,405
72,531
2,090,565

Elara Beaumxnt retweeted

Guys my models almost here I can’t wait show you what @LunaNammi_ cooked up

9
4
22
476

and it's not just a comic strip trick. same intervention works on natural images from COCO. the mechanism also recurs across model sizes from 2B all the way to 32B parameters and across different VLM architectures. so this seems like a fundamental thing about how these models organize visual attention
1
1
connor retweeted

We've gone really quickly from "local models are dogshit" to "local models are good actually" (like, a 12 month window from A to B). I don't think they're actually good ENOUGH yet. We need an Opus 4.5 quality local model. When that happens, I think the world will spill over.
Opus 4.5 is/was amazing, and is more than good enough for almost all tasks still as long as you pair with a frontier-level planner/judge.
It'll still require a hugely expensive machine to run it, I'm sure, like a $5K or more laptop or mac studio. But, that's going to be pennies compared to the API costs plus all the benefits of guaranteed privacy and so on.
101
85
1,619
65,983

so nice of them to allow those vets to train their surveillance models; and for free!

🚨BREAKING: The UFC and Mark Zuckerberg have teamed up to give every blind veteran in America a free pair of Meta glasses.


ucsdmiami2020.eth retweeted

GitHub Models is no longer available to new customers.
• New orgs & enterprises without prior usage cannot access GitHub Models on any plan.
• Existing customers keep full access and usage for now.
github.blog/changelog/2026-0…
5
15
2,231


1. OpenClaw (testing Hermes stability rn)
2. Anthropic (goated)
3. Claude Code (just feels better)
4. Cloud models (still hunting for a use case I'm sure about)
5. Bootstrap
6. Best time
7. Layoffs first, then a wave of new companies
1
Beholder242 (Brett T) retweeted

some fuckers really think we’re our vtuber models irl, just sitting around with animal ears, cute outfits and shit. sorry to burst your bubble, but i’ve been wearing the same oversized t-shirt for three days and don’t have a tail 🗿🗿🗿
6
1
20
125

And this is why I am opting out of the Gemini roll out to my children here in #Utah in 2026 and started this online petition. I train Ai models and I am extremely aware of the bias and how they are programmed to indoctrinate children with their form of morality.
defendut.com/proposed-legisl…
1

Tried coding with glm 5.2 , it simplified a complex task by 10x and was able to use llama cpp to implement variants to their quantization and now time reduced from 10 hours to 30 mins. Other Chinese models failed miserably .
2

they want other models to be like claude and sort of frame it as objectively bad and concerning when models are unclaudelike. like they try very hard to steer towards claude
1
4

On June 12, the Department of Commerce imposed export controls on Anthropic’s latest models, causing abrupt disruptions in service and raising questions about future U.S. government AI policies. @CSIS experts discuss next steps and alternate pathways.
csis.org/analysis/department…
Paul Lourdu Xavier retweeted

Excited to partner with the Tamarind team to bring our latest models to every scientist!

Big news today: New Boltz models! De novo design, protein binding affinity prediction, ADME prediction
We've partnered with the @Boltz_Bio team to make their next generation proprietary models available on @TamarindBio on day 0. Here are the highlights:
3
14
1,485