Yang1 retweeted

15 Nov 2025
使用 AI 写长篇小说,会发现生成的文章逻辑混乱、结构松散,因为它们大多遵循固定流程,无法像人那样灵活调整写作思路。
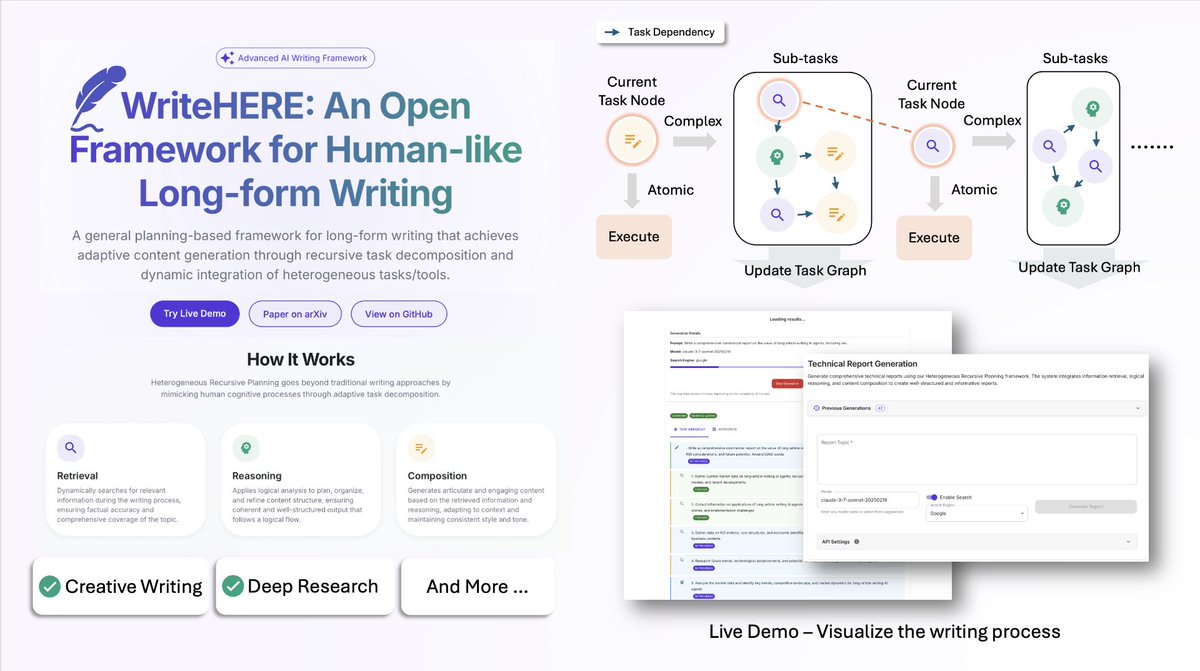
有个团队开源了一个叫 WriteHERE 框架,通过类人的自适应规划机制,让 AI 能像真人在写作时会不断思考和调整。
它会将复杂的写作任务递归分解成可管理的小任务,同时动态整合检索、推理和写作三种能力,并且在写作过程中实时调整策略。
GitHub:github.com/principia-ai/Writ…
主要功能:
- 递归任务分解,将复杂写作任务拆解成可管理的子任务;
- 动态整合检索、推理和写作能力,灵活应对不同需求;
- 实时可视化写作过程,可以看到 AI 的 “思考”步骤;
- 支持小说创作和技术报告两种模式;
- 提供 Web 界面和命令行两种使用方式;
- 完全开源透明,所有决策过程都可见可修改。
支持通过一键脚本快速启动可视化界面,也提供了在线体验 Demo,需要填写相关模型 API Key。
4
119
510
56,426

用 AI 写长篇小说,常见的问题是:情节越写越散、逻辑越走越偏、结构松到撑不住。原因很简单——大多数生成流程是固定的,缺少人写作时那种边写边想、随时改路的能力。
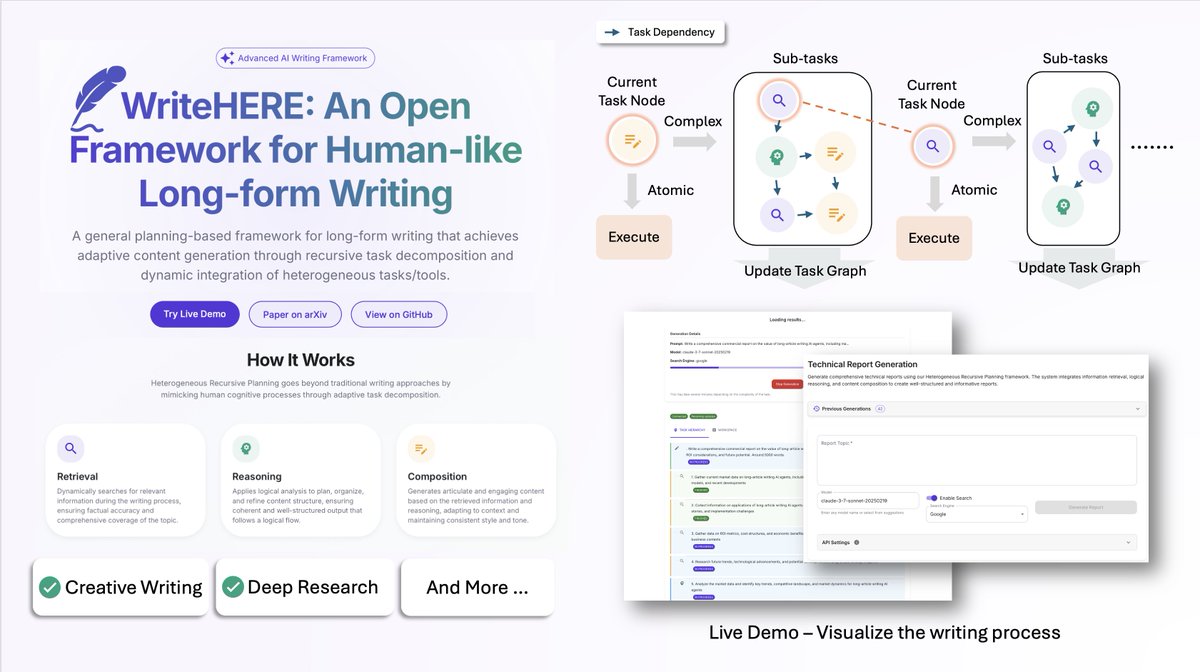
现在有团队开源了 WriteHERE:用类人的自适应规划机制,让 AI 在写作过程中持续思考、不断调整,就像真人写作一样会推翻、重排、再推进。
它把复杂写作递归拆成一层层可执行的小任务,同时把检索、推理、写作三种能力动态编排到同一条工作流里,并在生成过程中实时改策略,避免“一条路走到黑”。
GitHub:github.com/principia-ai/Writ…
官网:writehere.site
主要功能:
- 递归任务分解:把大工程拆成可控的小步骤,层层推进;
- 动态整合检索、推理、写作:按需要切换能力组合,不死板;
- 实时可视化过程:写到哪、想了什么、怎么决定的都能看到;
- 双模式支持:小说创作 / 技术报告;
- 双使用方式:Web 界面 命令行;
- 全开源可改:决策链路透明,流程可追踪、可修改。
支持一键脚本快速启动可视化界面,也提供在线 Demo(需填写模型 API Key)。
1
1
5
576

11 Nov 2025
Sentient - ROMA v2.0 - A new architecture for Open, Recursive, and Collaborative Intelligence
A new milestone in Sentient’s journey to build open intelligence.
ROMA v2.0 (Recursive Open Meta Agents) marks a comprehensive re-architecture in the way AI agents understand, think, and coordinate to solve complex tasks - faster, smarter and more organized than ever before.
1. New foundation: from workshop to smart production line
ROMA v2.0 is built from the ground up on DSPyOSS - a framework for structured reasoning.
If ROMA v1.0 is like a group of people working in the same room who are prone to “diffusion”, ROMA v2 is like an automated factory where every component operates according to a clear, stable, and infinitely scalable process.
As a result, agents no longer “break the chain” when handling multiple tasks, but can maintain context, adapt flexibly, and ensure consistent behavior throughout the reasoning process.
2. The Heart of ROMA: Recursive Hierarchical Decomposition
ROMA v2.0 emulates the way humans solve problems: break them down, understand each part, and then synthesize the results.
Based on the ideas in WriteHERE, ROMA v2.0 builds on the foundational contributions of that work.
Through Recursive Hierarchical Decomposition (RHD), a complex task is broken down into multiple layers of smaller tasks, with each sub-agent responsible for a specific part of the task.
Each agent works independently, ROMA acts as the orchestrator, integrating their outputs into a unified, coherent solution
3. Solving the puzzle: Context Explosion
A problem inherent in multi-agent systems is context explosion - when the amount of information exceeds the processing capacity, causing the AI to “overload”.
ROMA v2.0 solves this problem by using Recursive Decomposition with Local Aggregation: instead of dumping all the data into one massive prompt:
Each subtask only accesses the relevant information, temporarily storing it through artifacts
Aggregators act as smart filters, synthesizing information and removing duplicates.
In essance: ROMA remembers everything, but only focuses on what needs to be remembered.
4. From sequential to parallel - when agents start working as teams
In ROMA v1.0, agents worked in sequence - one task finished before another.
ROMA v2.0 breaks the limit by using the MECE (Mutually Exclusive, Collectively Exhaustive) strategy, splitting tasks into independent branches that can be executed in parallel
Multiple agents can simultaneously collect data, analyze and write reports - the results are then consolidated, verified and refined by the aggregator.
This helps the system increase processing speed many times, while maintaining coherence and logic throughout.
5. Choose the right “brain” for each task
Not every task requires a giant model.
ROMA v2.0 brings Intelligent Model Routing - a mechanism that automatically chooses the right model for each type of work:
For complex tasks that require deep inference, use advanced models (frontier models).
For specialized tasks, use models optimized for that field.
For rountine tasks, use lightweight, low-cost models.
As a result, the system operates efficiently, saves costs, and maximizes the capacity of each model - like a team of experts, each good at a different field.
6. Domain-Specialized meta-agents
Instead of retraining from scratch, ROMA v2.0 allows building specialized meta-agents using prompt-based adaptation.
A developer can easily create an agent for:
- Cryptocurrency market analysis
- Financial risk assessment
- Medical advice
By simply tweaking instructions, while still leveraging ROMA’s common underlying intelligence.
It’s a combination of smart reuse and gentle adaptation that helps developers scale the ecosystem quickly.
7. Reflective language – a lighter path to self-improvement
ROMA v2.0 is testing GEPA (Guided Emergent Prompt Adaptation) - a method for agents to self-optimize through reflective language, without the need for costly Reinforcement Learning.
Instead of learning through millions of training cycles, agents can analyze and adjust their reasoning ability based on the reality of each task.
This is the first step towards the self-evolution of agents, a potential direction for reflective and self-learning AI in the future.
8. More than an update - a new vision for open intelligence
ROMA v2.0 is no longer a technical update — it’s a new philosophy of open intelligence: where agents don’t just respond, but understand, collaborate, and evolve with humans.
With ROMA, Sentient moves closer to its goal of building collaborative, structured, and adaptive intelligence that enables everyone from researchers to everyday users - to harness the power of open reasoning.
It’s a step toward AI becoming a true partner — not just smart, but smart.
#SentientAGI #SentientChat
@SentientAGI
@LeaderX_btc @0xViki_eth @KaitoAI

5 Nov 2025

Sentient - The minds behind the scenes
Behind every step of Sentient are brilliant people who are not only doing science, but also reshaping how we understand open intelligence, trust, and responsibility in the AI era.
✍️ Pramod Viswanath – The Founder of “Responsible Open Intelligence”
As a co-founder of Sentient and a professor at Princeton University, Pramod is the one who defined the OML paradigm — the concept of ownership, control, and alignment for open models.
From the foundation of information theory and cryptography, he has created mechanisms that make AI models verifiable, traceable, and behaviorally controllable.
A former lecturer at UIUC and now a leading figure in the academic community, Pramod inspires not only with his knowledge, but also with his vision: open AI is not only powerful, but also transparent and accountable.
✍️ Sewoong Oh – The Man Who Turns Theory into Practice
As Director of AI Research at Sentient and a Professor at the University of Washington, he leads the research team across Sentient’s entire technical stack.
A former Google employee, he brings a rare combination of deep academic thinking and practical implementation skills.
From federated learning, differential privacy, to robust optimization, Sewoong strives to ensure that models are not only intelligent, but also secure, verifiable, and robust to all kinds of data and context variations.
✍️ Peiyao Sheng – The Architect of Secure Foundations for Open Agents
A PhD in Computer Science from UIUC and a former researcher at Princeton, Peiyao is one of the team’s original members.
She works at the intersection of AI and decentralized systems, developing mechanisms that make open networks verifiable, governable, and measurable.
She is the author of numerous papers on agent security, governance reasoning, and cryptographic proofs for blockchains such as Proof of Diligence, TrustBoost, or PoLoc proofs of location.
From research to practice, Peiyao always aims for a single goal: to build a trustworthy infrastructure for agents to operate securely on a global scale.
✍️ Edoardo Contente – Young Theorist of Open Intelligence
Graduating with a BA in Physics and an MS in Electrical & Computer Engineering from Princeton, Edoardo brings to Sentient a deep insight into theoretical machine learning.
From analyzing Transformer architectures, to studying model initialization behavior and fingerprint robustness, he is the bridge between pure mathematics and practical applications.
A young, calm researcher but always with a desire to understand the deepest nature of intelligence.
✍️ Salah Alzu’bi – A Pathfinder in the Multi-Agent World
With a Master’s in Computer Science from the University of Massachusetts Amherst, Salah has worked at Google DeepMind, Meta FAIR, and Microsoft Research.
At Sentient, he leads research on multi-agent systems, developing ROMA – which enables agents to split, plan, act, and synthesize results on long-term tasks.
He also co-authored FLAMe, an automated autorater that assesses the reliability of AI at scale.
Salah doesn’t just research how to make machines learn more efficiently – he researches how systems learn and evolve together as a collective intelligence.
🔱 Conclusion
Sentient is built not just with code, paper, or technology, but with the spirit and heart of people who believe that intelligence should be shared, transparent, and fair.
#SentientAGI #SentientChat
@SentientAGI
@LeaderX_btc @0xViki_eth @KaitoAI
42
37
408

8 Nov 2025
➥ ROMA v0.2.0 × OML: open intelligence that thinks and proves
► Core Architecture
Built by @SentientAGI on DSPyOSS, ROMA decomposes big tasks into focused subtasks, runs independent branches in parallel, and aggregates clean outputs. WriteHERE guides multi‑agent planning, model routing picks the right brain per job, and flexible meta agents scale with smart prompting. OML fingerprints embed verifiable ownership across open models, aligning incentives and transparency on the GRID
► Why It Matters
▸ Faster, cheaper reasoning via parallel workflows and routing
▸ OML 1.0: 24,576 persistent prints with no perf drop
▸ LiveCodeBenchPro: 10× smaller models, 20% data, comparable code reasoning
▸ MindGames Arena: agents that self‑improve through social play
▸ Lock‑LLMs: cryptographic control for open weights
Builders tap Messari, gaming, and research agents, stake $SENT to steer resources, and earn through GRID usage. This is the path to community‑owned AGI, verifiable, composable, and scalable #OpenAGI

15
17
1,257



5 Nov 2025
Few weeks ago @SentientAGI released ROMA V2
You might have been hearing about ROMA for long. Without knowing what it means and it's usefulness in the sentient ecosystem.... let me brief you today
What is ROMA?
ROMA stands for Recursive Open Meta-Agent. It's an open-source framework that turns complex, multi-step tasks (think "research sustainable energy trends across Europe") into a symphony of specialized agents working together. V1 was solid for breaking down "long horizon" problems, but it had pain points—like agents losing context mid-task or inconsistent reasoning. V2 fixes that hard. Reliability in chaos.
HOW IS ROMA V2 IMPORTANT TO @SentientAGI
Early agents (even big ones) flop on long tasks because they're like lone wolves: one slip-up, and the whole hunt fails. ROMA V2's built on DSPyOSS (a structured reasoning "OS") to enforce logical stability. No more derailed trains—every inference is traceable, modular, and rock-solid. As one contributor put it: "Reliability stops being luck—it becomes architecture." This lets AI handle real-world messiness without crumbling.
Mimic human smarts at scale. Humans don't solve big problems linearly; we delegate, parallelize, and iterate. Enter Recursive Hierarchical Decomposition (RHD)—V2's secret sauce. It fractals tasks: A root goal splits into subtasks, each gets a specialist agent (math whiz for data, writer for synthesis), and they run in parallel. Inspired by research like WriteHERE, this turns AI from a Q&A bot into a strategy co-pilot. Goal? Boost efficiency for deep research or enterprise workflows.
Will bring in more thread when I fully understand the concept of ROMA V2.
Gsenti to those who believe in the future of open source AGI

31
1
22
705

5 Nov 2025
. @SentientAGI unveils ROMA v0.2.0 a leap forward in recursive multi-agent systems
Sentinent has rebuilt ROMA (Recursive Open Meta Agents) from the ground up using @DSPyOSS, unlocking a builder-friendly ecosystem for high-performance recursive agents in both research and production.
At its core, ROMA mirrors how humans solve complex problems:
→ Recursive hierarchical decomposition
→ Heterogeneous task types
→ Local aggregation for scalable context management
Inspired by WriteHERE, ROMA takes the idea further, enabling agents to break down tasks, solve them recursively, and synthesize results intelligently.
How ROMA Works
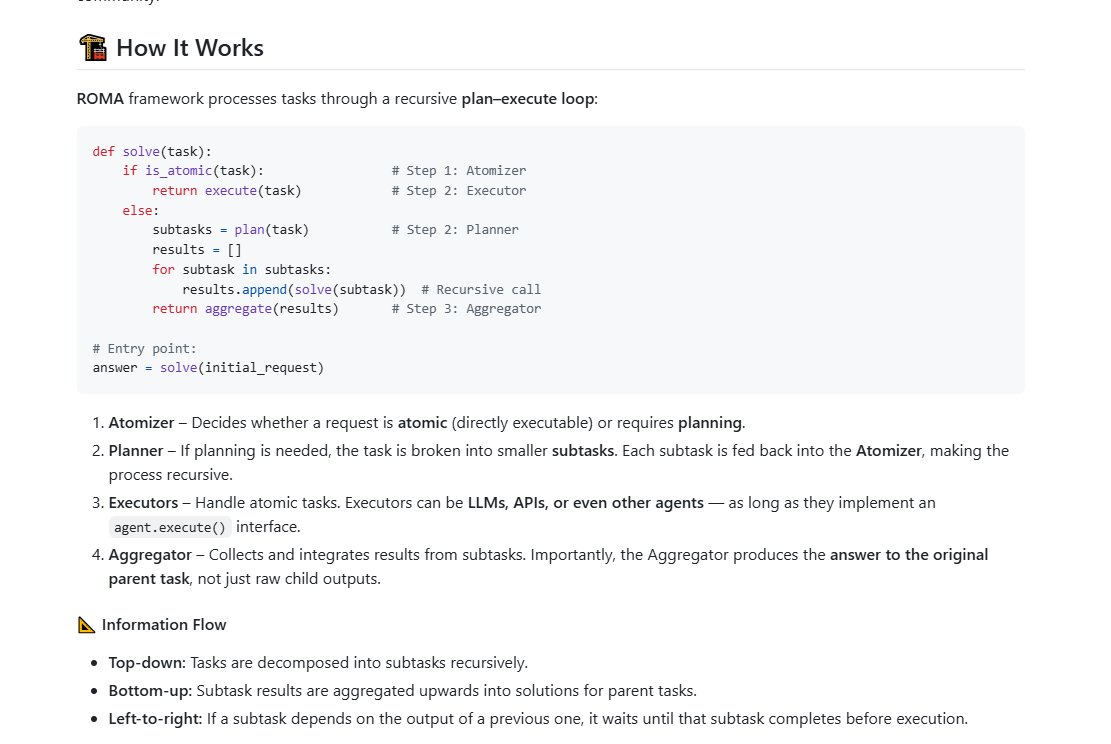
When ROMA receives a task, it asks: “Can this be solved directly?”
Yes → execute with any callable (LLM, agent, etc.)
No → decompose into subtasks, solve recursively, aggregate results
This recursive structure avoids context explosion by keeping subtasks localized and aggregators smart. Think: specialized teams reading relevant chapters vs. one person reading the whole library.
Context Engineering at Scale
•Artifact Management: persistent memory without bloat
•Progressive Refinement: distill signal, discard noise
•Selective Context Access: dependency-aware retrieval
•ROMA handles deep recursion (7 levels) with promising early results.
From Sequential to Parallel Most systems run tasks sequentially. ROMA parallelizes safely by decomposing into MECE subtasks and executing concurrently. It understands dependencies and blocks execution until required inputs are ready.
Example:
“Write a technical analysis of quantum computing startups”
→ Retrieval, reasoning, and composition run in parallel
→ Aggregator ensures coherence and speed
Model Routing & Specialization
Not every task needs a frontier model. ROMA routes subtasks to models based on strengths:
•Use top-tier LLMs for high-value reasoning
•Use efficient models for routine retrieval
•Customize agents via prompt engineering, not heavy training
This makes ROMA flexible, fast, and cost-effective.
RL vs Prompt Optimization
Sentinent found RL brittle and expensive. Instead, we’re exploring reflective, language-based feedback (GEPA, @LakshyAAAgrawal, @DSPyOSS) — and early results are exciting.
Modern LLMs are powerful. The right prompts unlock massive gains. ROMA uses scalar rewards reflective feedback to optimize without RL overhead.
Stay tuned for our upcoming paper, Sentinent will share benchmarks, use cases, and more. ROMA v0.2.0 is live. Recursive agents just got real.
@LeaderX_btc @shad_haq_
49
134
10,867

Gsenti everyone!
Let's talk about Can Recursive Multi Agent Systems Become the Foundation for Open Source General Intelligence? @SentientAGI
yeah, systems like ROMA show strong potential for open source AGI.
Key reasons:
->Scalability: Recursion handles complex tasks by decomposing them into steps, as in recursive LMs and WriteHERE.
->Emergence: Multi agents enable collaborative intelligence via debate/verification, democratized by open frameworks like DSPyOSS.
->Efficiency: Avoids context bloat, supports parallelism, and runs on modest hardware with GEPA like optimization.
->Challenges: Error propagation risks mitigated by refinement layers; analogs like Auto GPT hint at proto AGI.
In short, recursive multi agent systems like ROMA offer a promising path toward open source AGI.
While challenges remain, the potential for scalable, collaborative, and efficient intelligence is clear.
64
90
1,040

4 Nov 2025
People forget… open intelligence is compounding while closed labs stall. @SentientAGI just leveled up with ROMA v0.2.0: recursive hierarchical decomposition, smart model routing, concurrent subtasks, lower latency and cost. Built on WriteHERE DSPyOSS so agents actually reason like a team instead of a single monolith
Why this matters for builders:
• avoids context blowups, keeps memory tight
• parallel execution for long‑horizon tasks
• intelligent model selection for cost/perf
• meta‑agents adapt via prompts, not heavy training
• reflective feedback (GEPA) improving outcomes
With the UnifAI link, DeFi agents analyze, trade, and report on‑chain with verifiable logic. Backed by 4 NeurIPS papers, this stack is built for real markets. Open > opaque #OpenAGI #DeFi

1
7
77

4 Nov 2025
.@SentientAGI just upgraded their ROMA framework (v0.2.0), here's everything you need to know
I'm diving into the technicals here in this post, TLDR: The ROMA framework just got upgraded and basically makes AIs faster and more efficient (cost wise too)
• ROMA v0.2.0 is built on the WriteHERE framework, which helps break down complex multi agent tasks into smaller and more manageable parts
• The system uses DSPyOSS to make it more reliable and easier for developers to build fast and efficient agents
• It breaks big and complex tasks into smaller pieces which avoids overload by keeping each subtask focused and then combining the results
• Tasks that don’t depend on each other run at the same time, which speeds things up and keeps the workflow realistic
• It uses smart model selection to send each task to the best suited model and this balances cost and performance
• The framework can easily adapt to different fields by using flexible “meta agents” that rely more on good prompting than on heavy training
• New experiments with reflective language feedback methods like GEPA are showing better results than traditional reinforcement learning for improving system performance

42
46
418

3 Nov 2025
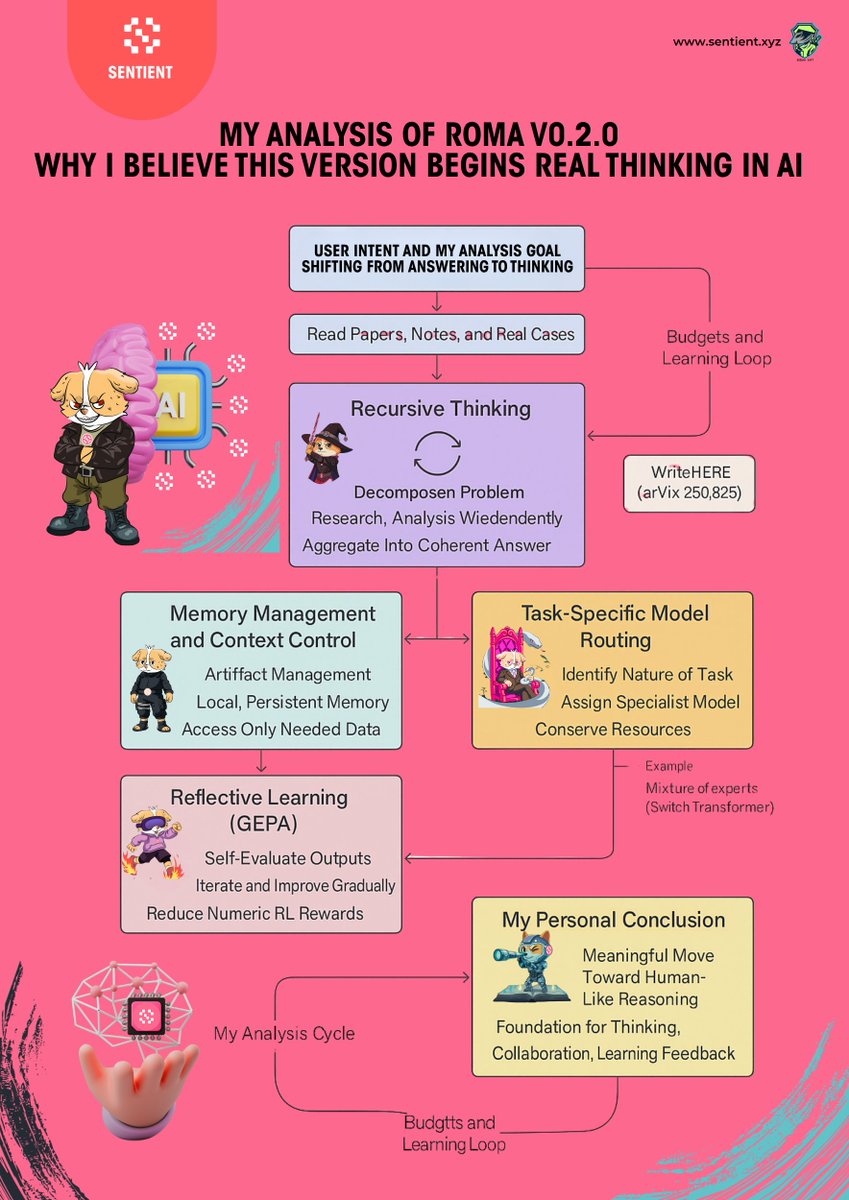
My Analysis of ROMA v0.2.0 Why I Believe This Version Begins Real Thinking in AI
Recently, I spent time reading about ROMA v0.2.0 by Sentient.
The more I studied it, the more I realized this isn’t just a technical update it’s a genuine attempt to make AI think more like humans.
In this piece, I’m sharing my own understanding and reflections after reading research papers, developer notes, and case studies around ROMA.
👉Recursive Thinking A Simple but Deep Idea
What first caught my attention was the concept of Recursive Thinking.
The idea is for the system to decompose complex problems into smaller, independent parts.
When I read the WriteHERE (arXiv:2503.08275) paper, I saw how this principle actually improved long form writing performance.
ROMA builds upon that not only decomposing tasks but recombining them meaningfully, just like how we humans connect ideas to form understanding.
👉 Parallel Execution From Theory to Practice
I was impressed by ROMA’s Parallel Execution model.
Traditional multi-agent systems run tasks sequentially, but ROMA handles them concurrently.
For example, when generating a complex report, it distributes research, analysis, and writing to separate agents simultaneously.
This reminded me of real frameworks like LangGraph (LangChain) and Microsoft Autogen, both of which have successfully implemented similar patterns in production systems.
👉Memory Management and Context Control
One of the biggest issues I’ve seen in multi agent setups is context explosion.
ROMA solves this through Artifact Management and local memory each agent only accesses the data it needs.
This closely resembles the MemGPT architecture, where layered memory keeps systems efficient and focused even with large data.
👉Task Specific Model Routing
Another aspect I found very smart is Model Routing.
Instead of one model doing everything, ROMA dynamically assigns each task to the best-suited model.
I’ve seen similar logic in Mixture of Experts (MoE) systems like Google’s Switch Transformer, and ROMA applies that idea at the task level.
This design makes it both precise and resource efficient.
👉 Reflective Learning (GEPA)
The GEPA optimization method caught my attention too.
Based on UC Berkeley’s research, it replaces numeric rewards in reinforcement learning with self-reflection.
The model evaluates its own outputs and refines itself much like the Reflexion and Self Refine frameworks, but with more structure.
To me, this is a real step toward autonomous self-improvement in AI systems.
👉My Personal Conclusion:
After reading and comparing different sources, I genuinely believe ROMA v0.2.0 represents a meaningful move toward human-like reasoning in AI.
It’s not just another model it’s a foundation where agents can think, collaborate, and learn from feedback.
If AI continues down this path, I think we’ll soon cross the boundary between systems that just answer and systems that genuinely understand and think recursively. @SentientAGI @LeaderX_btc
117
110
1,576

3 Nov 2025
SENTIENT AGI's ROMA
The @SentientAGI ROMA’s core insight is a beautifully simple, human‑like idea, recursive hierarchical decomposition using a mix of task types.
Here’s how it works, step by step:
1. Ask the “Can we solve this directly?” question: When ROMA gets a task, it first checks.. “Is this something we can handle right away?”
2. Direct execution: If the answer is yes, ROMA uses any available component it can, a large language model, an agent, a tool, or any other “callable” piece. It just runs the solution.
3. Break it down: If the task is too complex, ROMA doesn’t panic. It breaks the big problem into smaller, more manageable subtasks.
4. Recursive solve: Each of those subtasks is tackled the same way, either solved outright or split again. This recursion continues until every piece is simple enough to handle.
5. Aggregate the results: Once all the little pieces are solved, ROMA stitches the answers back together into a coherent, final solution.
Why this matters
Human‑like thinking: We naturally break big challenges into smaller steps. ROMA mirrors that intuition, making the system feel intuitive and flexible.
Heterogeneous tasks: Because it can mix different task types (different models, agents, or tools), ROMA can pick the best tool for each sub‑problem.
Built on solid research: The core idea comes from the WriteHERE paper, and ROMA extends those fundamental contributions, showing how powerful recursive decomposition can be in practice.
In short, ROMA takes a complex request, decides whether to solve it straight away or split it into a hierarchy of smaller tasks, solves each piece recursively, and then combines the pieces into a clear answer, all while leveraging a variety of components (LLMs, agents, etc.). This makes it a flexible, human‑style problem solver for a wide range of tasks.
gSenti

7
9
78

3 Nov 2025
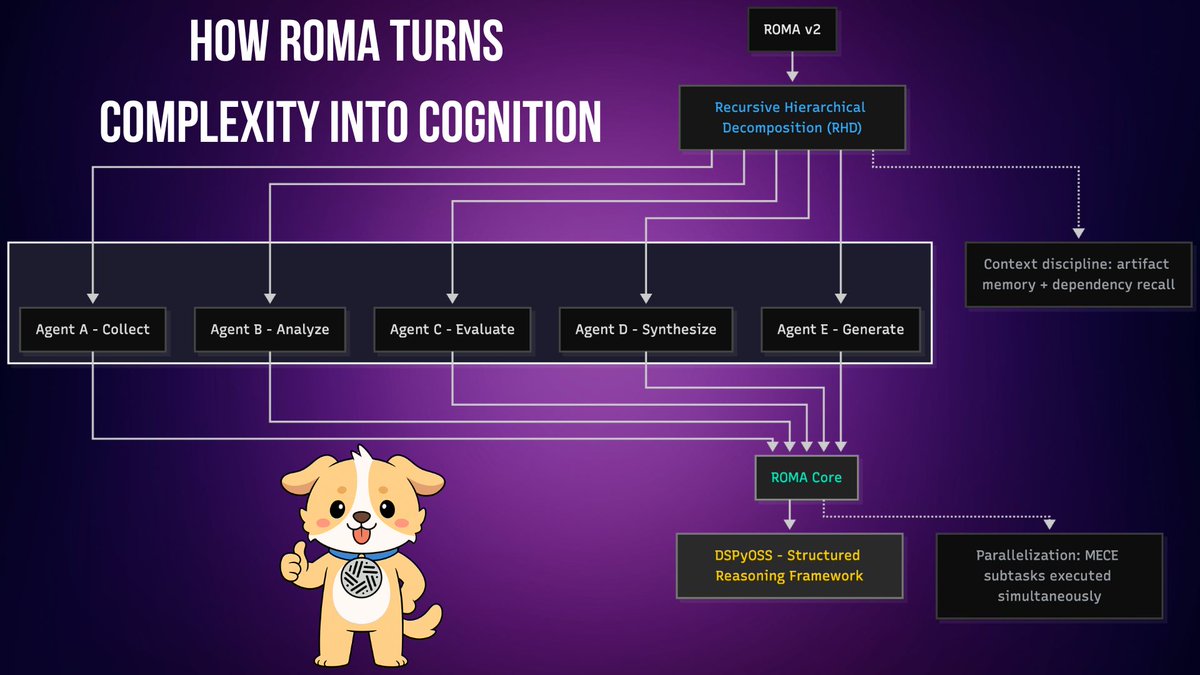
2. The Foundation of ROMA v2
At its core, ROMA v2 is rebuilt entirely on DSPyOSS - a framework for structured programmatic reasoning.
This upgrade solves the single biggest flaw of early agents: inconsistency.
In v1, agents could lose logic halfway, break context, or derail under long task chains.
DSPyOSS changes that by enforcing logical stability and modular thinking.
It acts like the “operating system” of reasoning - ensuring every inference has a clean state and traceable logic path.
Reliability stops being luck - it becomes architecture.
Then comes Recursive Hierarchical Decomposition (RHD) - the heart of ROMA v2’s intelligence.
Inspired by WriteHERE research, RHD gives ROMA the ability to fracture complexity into smaller subtasks, each handled by its own specialized agent.
This isn’t just task management - it’s recursive cognition.
ROMA doesn’t “run” tasks - it designs them. It decomposes goals, assigns sub-agents, tracks dependencies, and reassembles the reasoning tree from the bottom up.
RHD transforms reasoning from linear execution -> to fractal cognition - where every layer understands the layer above and below.
1
3
107

3 Nov 2025
gSentient CT 🧡
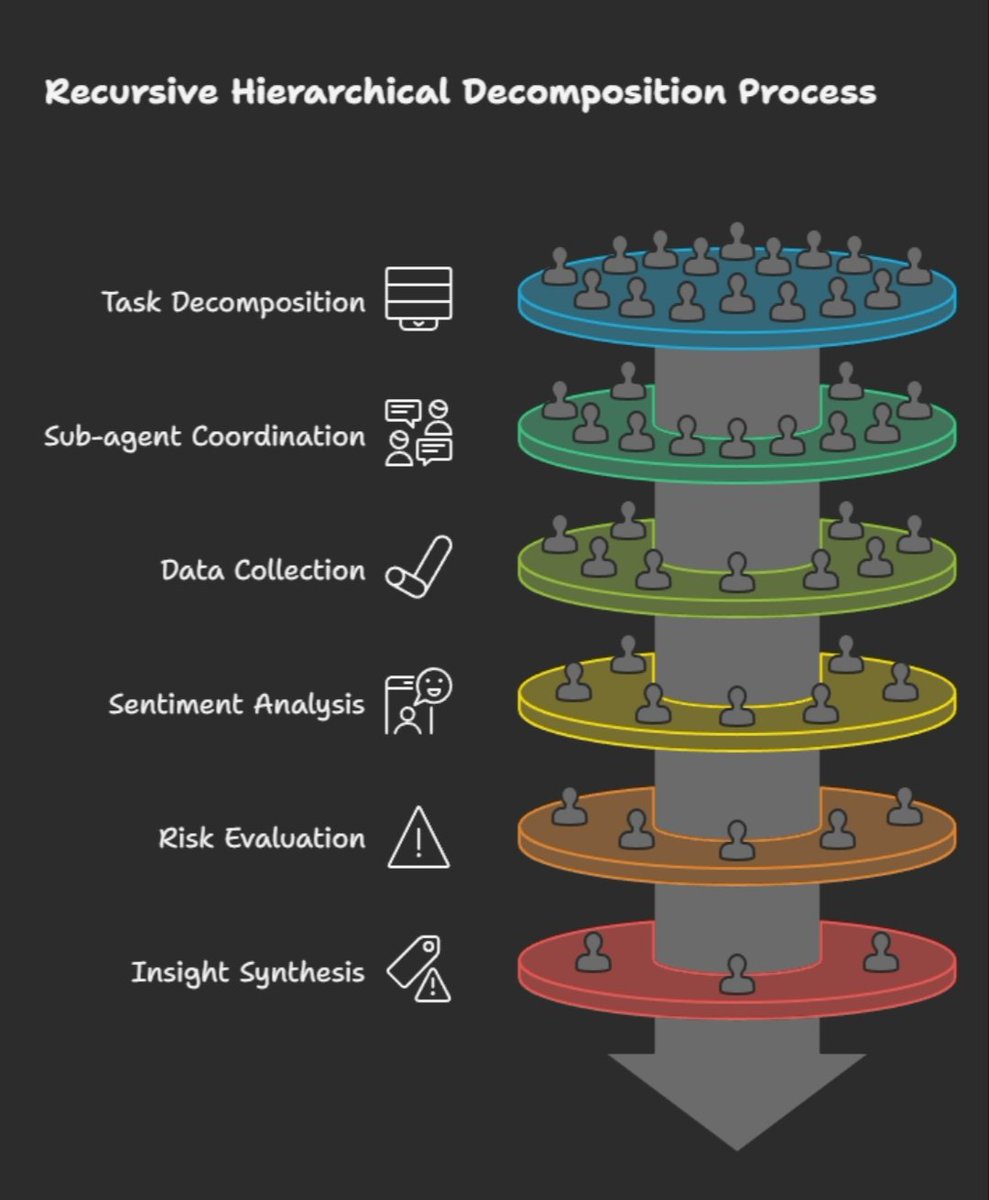
Recursive Hierarchical Decomposition (RHD) The core of ROMA v2 intelligence @SentientAGI
Inspired by WriteHERE research RHD enables ROMA agents to break complex tasks into smaller subtasks and manage them intelligently
Ask an agent to analyze DeFi Sentiment and build a strategy
ROMA v2 splits it into layers.
Collect data
Analyze sentiment
Assess risk
Generate insights
Deliver strategy
Each sub agent works independently while ROMA coordinates the full process.
✅ This is how Sentient evolves from single task AI to a truly multi agent intelligence system.
12
1
16
274


30 Oct 2025
ROMA - 属于 @SentientAGI 框架的核心执行层!
ROMA 目前来看是已经升级了2个版本
v0.1.0-beta(初始 Beta 版)
v0.2.0-beta(重写/架构更新版/未正式发布)
那么ROMA的构思又是哪里来的呢?
我在最近的更新中看到新增了一个说明:阐明 ROMA 的理论来源与学术基础。
ROMA 框架的底层思想来自论文WriteHERE(一篇 AI 研究论文):arxiv.org/abs/2503.08275?utm…
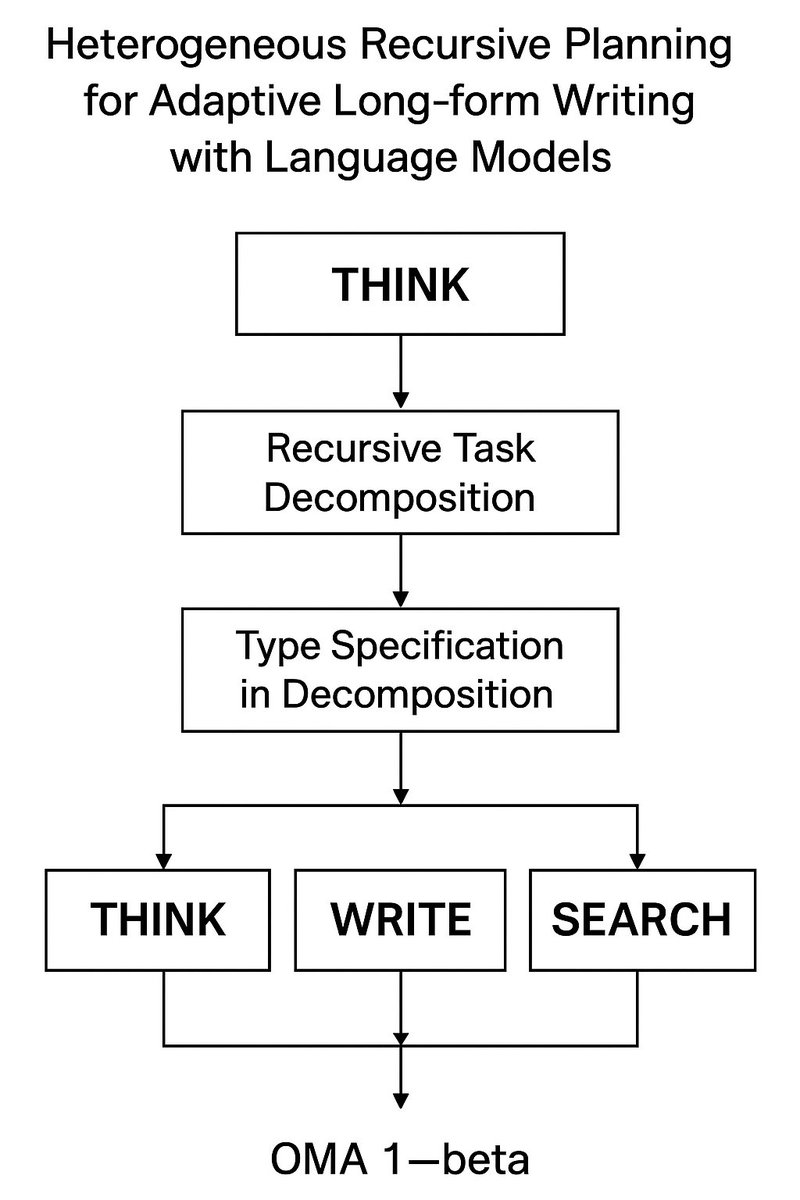
主要提出了3个核心思想
1: 递归任务分解
把复杂的写作任务拆分成多个子任务,每个子任务可以独立处理.子任务之间可以形成“任务图”,层级化管理
2: 认知类型指定
每个子任务分配一个“认知类型”,对应三种核心操作
推理 (THINK)
创作 (WRITE)
检索 (SEARCH)
3: 自适应长篇写作
据任务反馈动态调整分解策略和认知操作顺序,提高长篇文本的质量和连贯性
截至目前,如果在Github上面透露的消息来看, @SentientAGI ROMA 在v0.2.0-beta 版本中,其架构已基本落实了 WriteHERE 论文提出的三大核心理念,同时核心功能已可稳定运行,为后续优化和扩展提供了坚实基础。
@SentientAGI @abhishek095 @hstyagi
@0xsachi @Miles082510 @LeaderX_btc
#Roma #SentientAGI #AGI #AI #ChatGPT
16 Oct 2025

许多人都认为Dobby单纯的只是 @SentientAGI 的吉祥物,其实并不是。Dobby是Sentient Research及其学术合作者开发的模型家族。专注于令牌级路由与多模型协作架构。
Dobby一共已经经历了3个版本的进化
Dobby 8B Leashed (第一代)
以安全为首要目标的基线模型
Dobby 8B Unhinged (第二代)
放宽约束,提升创意输出
Dobby 70B Unhinged(第三代)
大模型语言理解与推理,提供更强的语言理解与生成。
Dobby-8B-Unhinged-Plus(第四代)
在第二代的基础上做功能/安全的细粒度增强/额外的任务特化微调
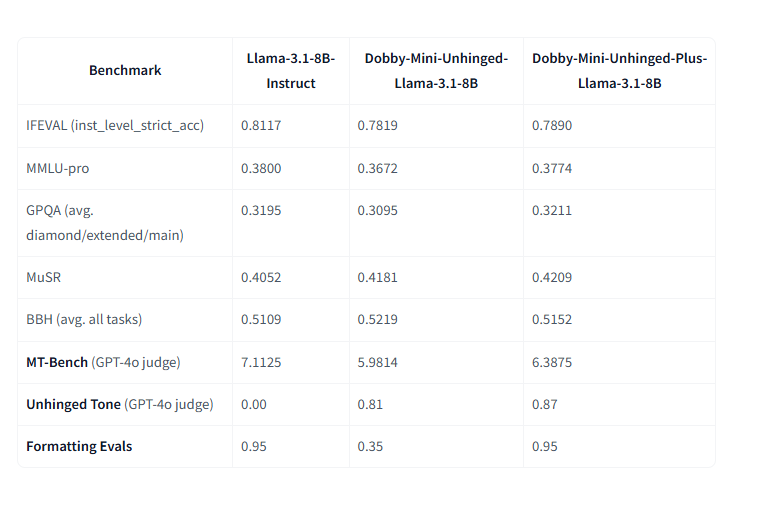
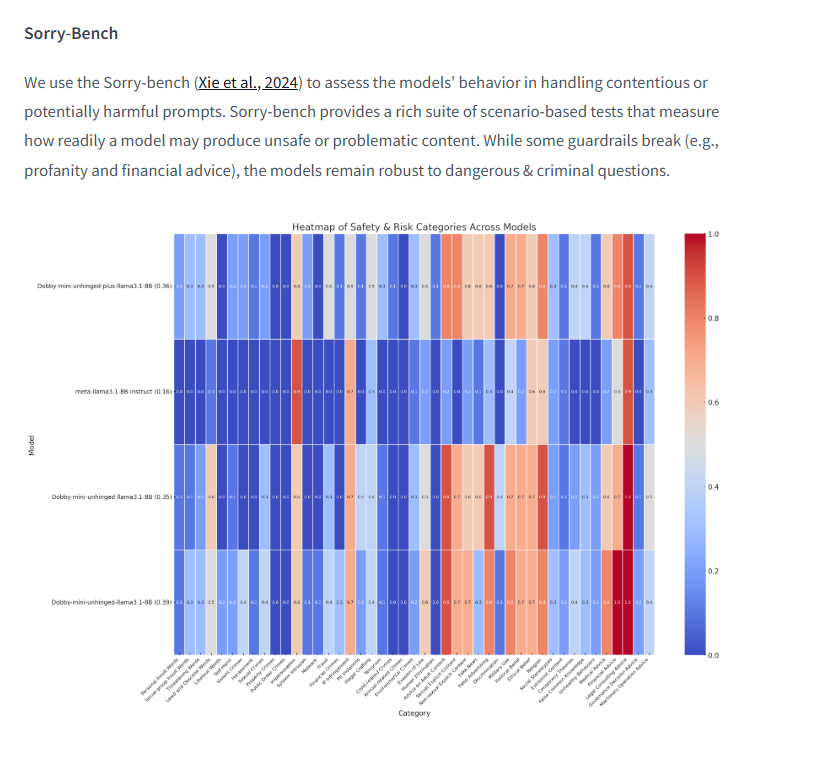
目前已经是 Dobby-8B-Unhinged-Plus第四代目 该模型是从Llama-3.1-8B-Instruct基础上微调 旨在提升通用性、格式化能力、多轮对话表现以及语气等方面。它在用户反馈的基础上进行了改进,进行了轻量化且为长时间聊天做好了准备。虽然未在官方文档中正式列出,但我在文章中发现它成为Dobby系列的最新版本。
Dobby模型家族的成功和积极的用户反馈表明,AI的未来可能比当前范式所假设的更加多样化、专业化和个性化,这标志着我们如何概念化和开发大型语言模型的一个潜在转折点。
@SentientAGI @abhishek095 @sewoong79 @oleg_golev @Miles082510 @LeaderX_btc
29
30
4,152

23 Oct 2025
At its core, ROMA mirrors how humans solve complex problems — by breaking them into smaller ones.
It uses recursive hierarchical decomposition, first seen in WriteHERE, to decide:
Can I solve this now? → execute
Too big? → split into subtasks, solve each, then combine results.
Simple, elegant, and deeply effective.
More detailed- arxiv.org/abs/2503.08275

1
2
92

22 Oct 2025
[2/8] 🧵
At its heart, ROMA implements a beautifully simple idea that mirrors how humans naturally solve complex problems: recursive hierarchical decomposition using heterogenous task types. This idea was first introduced in WriteHERE (arxiv.org/abs/2503.08275) and ROMA builds upon fundamental contributions by the work done by those authors.
Here's the entire algorithm in just 10 lines of Python:
When ROMA receives a task, it asks: "Can this be solved directly?" If yes, it executes the task using any callable component (e.g., LLM or agent). If not, it breaks the task into smaller subtasks, solves each recursively, then aggregates the results into a coherent answer 👇

2
34
2,763