
API-first Agentic Document Intelligence platform built for accuracy, reliability, and governance at scale.
Joined December 2017
- Tweets 2,936
- Following 860
- Followers 10,023
- Likes 1,095
926 Photos and videos











Pinned Tweet

Jan 15
We just launched a new short course with @DeepLearningAI
Document AI: From OCR to Agentic Doc Extraction.
This course shows how to move beyond OCR by building agentic document pipelines that preserve layout, reading order, and visual context when extracting structured data from complex PDFs and images.
Free to enroll here: bit.ly/4bpV2rG
1
8
28
1,986
Jun 9
Getting a JSON back from a document isn't the hard part.
Knowing whether to trust it is.
Most document pipelines wrap an LLM around a schema, extract the fields, and pass the output downstream. It works on clean documents. On messy real-world ones, it returns wrong values confidently with nothing to indicate something went wrong.
The failure mode isn't extraction. It's silent extraction.
ADE (Agentic Document Extraction) is built around this problem. Every extracted value carries a bounding box and page reference, traceable back to its exact location in the original document. Cross-page tables reconstruct as complete arrays instead of disconnected rows. Documents over a thousand pages process without losing context.
The difference between a demo that works and a system you can ship to production is knowing exactly where your extraction can and can't be trusted.
5
11
290
May 26
RAG on real documents is a different problem!
You can stand up a pipeline on clean PDFs. It breaks on dense tables, scientific figures, and irregular layouts.
Andrea Kropp is walking through the full workflow at @Snowflake Summit. ADE handles document parsing. Snowflake Cortex handles semantic retrieval, natural language queries, and agent orchestration. Everything surfaces through Snowflake Intelligence.
The entire stack runs from one SQL script and can be adapted to your use case in about half a day.
📅 Wednesday, Jun 3
🕓 4:00 PM - 4:45 PM PDT
1
4
341
May 22
Extraction scales fine on short documents. Long documents break it.
Tables span pages and arrive as disconnected rows. Suppliers use different field labels and schemas start returning nulls. Compliance teams ask where a number came from and there's no answer.
These aren't edge cases. Long documents, label variation across suppliers, and audit requirements are standard in production workflows.
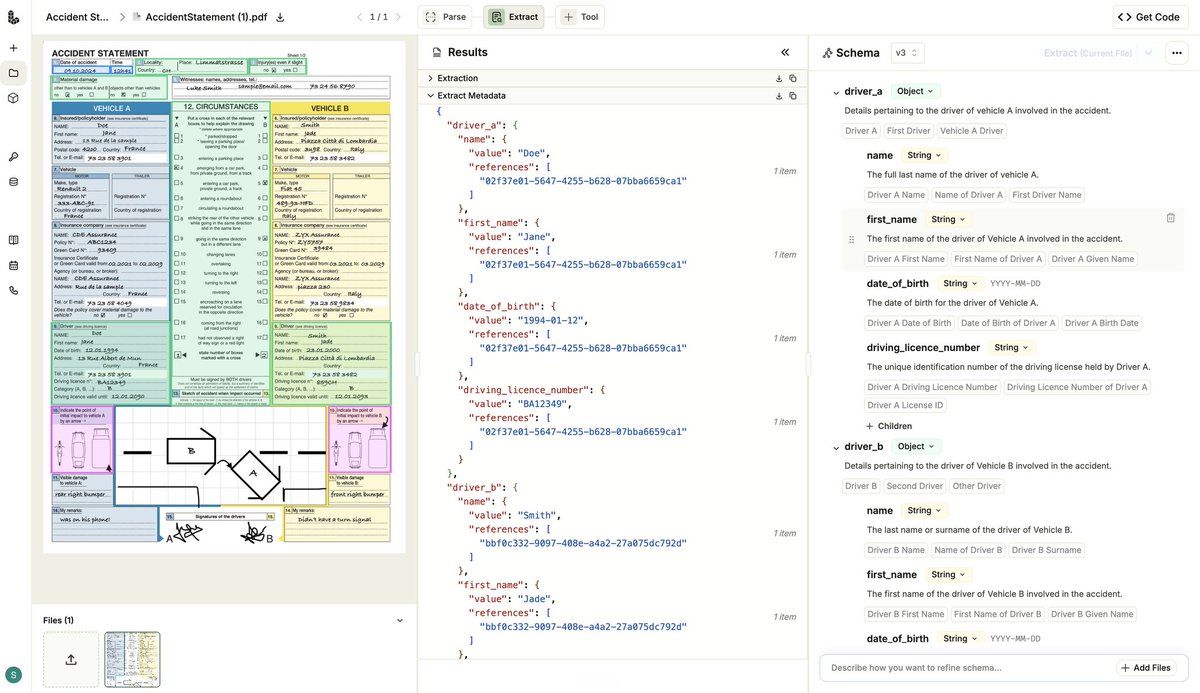
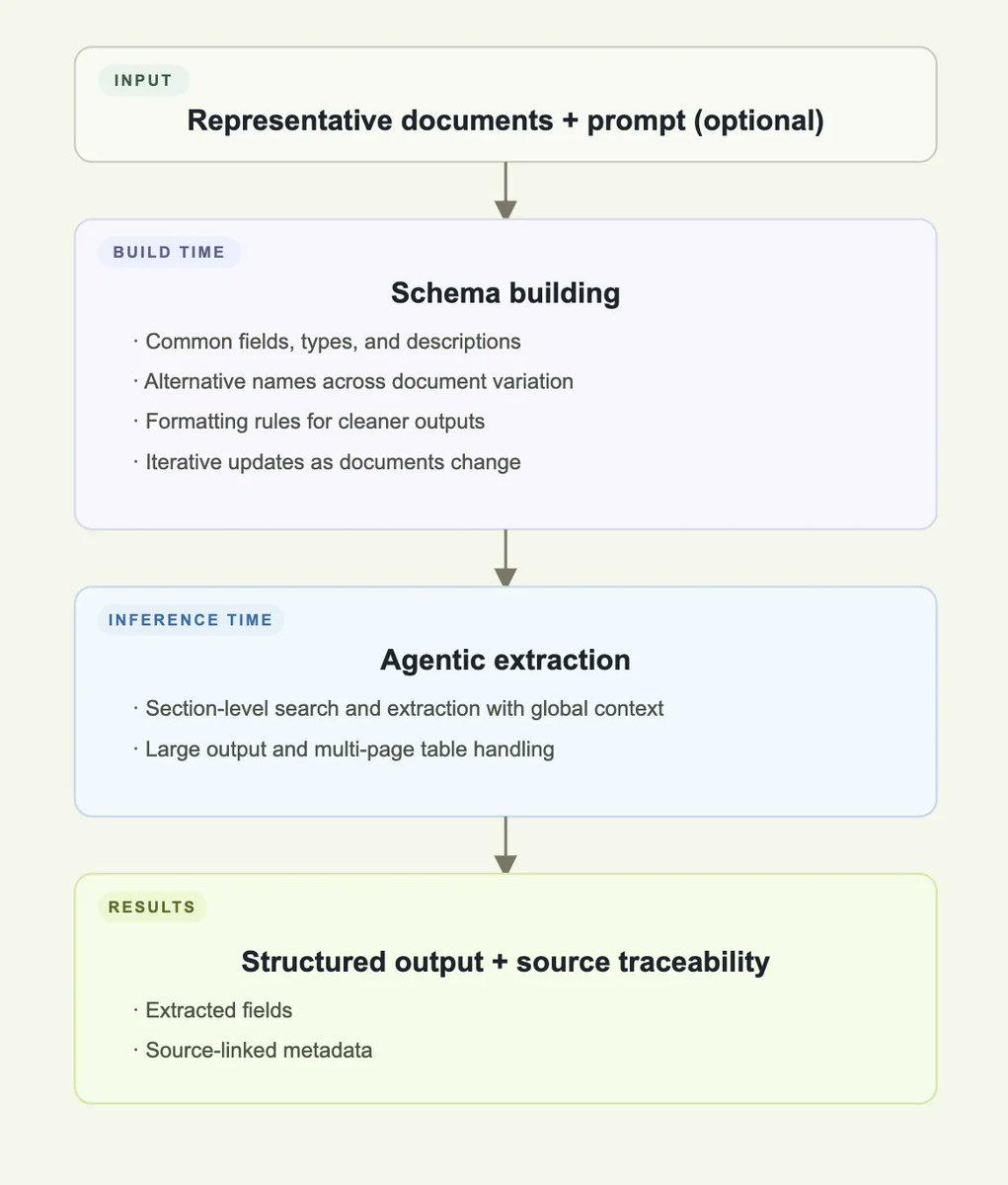
The new ADE Extract API handles this in two phases.
The Schema Building API ingests documents across suppliers and produces one master schema. It resolves label variation through semantic matching.
The Extract API processes the full document in a single call. Cross-page tables reconstruct as complete arrays. Every extracted value includes a chunk reference ID, so every number traces back to its source.
Link to the full article in the comments.
1
3
10
467
May 20
GreenLite cut plan review turnaround by ~50% with LandingAI’s ADE.
@GreenLiteTech is an AI-native permit intelligence platform processing hundreds of construction projects monthly across hundreds of US jurisdictions.
Their Plan Review Agent reasons across building codes and assesses compliance across architectural disciplines. None of it works if extraction breaks.
Plan sets are dense, stylized, and inconsistent. Stamped drawings, multi-column specs, schedules that follow no template.
GreenLite evaluated frontier VLMs and several dedicated OCR and IDP providers. ADE was the most consistent performer on dense-figure and non-standard layouts.
The results:
→ 50% faster plan review turnaround
→ >90% precision and recall system-wide
→ ~90% of agent recommendations accepted by expert reviewers
Engineering shifted from extraction firefighting to reasoning and knowledge graph work.
Read the full case study.
Link in the comments!
1
2
210
May 19
Your RAG pipeline reads every chunk. But it has no idea where they came from.
Introducing ADE Section: hierarchical context for every chunk in your retrieval pipeline.
Standard chunking strategies slice documents into fragments, stripping away structure. "Revenue is down 10%" lands in your index with zero signal of whether it came from Risk Factors or Global Operations. Both queries compete against the same flat pool of chunks.
ADE Section builds a hierarchical Table of Contents from your parsed document, tied to exact chunk anchor IDs. It prepends the full breadcrumb path to every chunk before embedding. Structure bakes directly into the vector.
The ancestor path saves as metadata, so you can filter retrieval to specific sections. A legal analyst searching for indemnification clauses doesn't need the system evaluating marketing copy. Precision filtering cuts noise on every query.
The breadcrumb travels with every chunk into the LLM. The model knows exactly where it is in the document. Citations hold up.
When the default hierarchy needs adjustment, pass a guidelines prompt in the API call.
Run ADE Parse, then run ADE Section.
1
4
10
427
May 19
Try it now in the playground: va.landing.ai
Read more here: landing.ai/blog/beyond-flat-…
2
130
May 17
Unlocking RAG on Complex Documents!
Your RAG pipeline works on clean PDFs. It breaks on the documents you actually need to process. Scanned forms, nested tables, multi-page charts, irregular layouts. These are where conventional extraction fails.
Andrea Kropp from LandingAI and the @Snowflake team ran a webinar showing the full end-to-end workflow.
ADE parses complex documents. Dense tables, embedded figures, multi-page structures. It extracts structured fields and creates semantic chunks. Both get stored in Snowflake.
Snowflake Cortex provides the query layer. Semantic search across chunks for contextual questions. Natural language to SQL for structured queries on the extracted fields. External enrichment from sources like PubMed. Agents that orchestrate across all these capabilities.
Business users interact with everything through Snowflake Intelligence.
You'll see live demos on FDA regulatory documents and legal contracts. Andrea walks through the architecture, shows the code in Snowflake worksheets, and shares how Olas Medical deployed this in production.
Link to the webinar in comments.
2
5
14
1,483
May 12
We are introducing ADE Classify.
Page-level classification for mixed documents.
Here's the problem. A 50-page mortgage PDF hits your pipeline. You pay to process 48 pages you didn't need. That mixed text reaches your extraction agent. It starts extracting invoice data from passport pages.
ADE Classify evaluates every page concurrently against your custom JSON class schema before ADE Parse even runs. Each page comes back with a label and a reasoning string.
Unknowns get flagged with a suggested class so nothing slips through silently. Pass semantic descriptions per class and the model handles the ambiguity - no fine-tuning needed to tell a formal invoice from a generic receipt.
Different document types route to different pipelines. Classification happens first, not after you've already paid to parse everything.
The reasoning string is logged for downstream auditing. Every routing decision your pipeline makes is fully traceable.
Try it right now in the Playground with your mixed documents. Link in the comments!
1
3
10
2,439
May 8
We built a multi-agent loan underwriting system!
It's a production-ready multi-agent system powered by LandingAI Agentic Document Extraction (ADE) and Google ADK.
Upload a mixed financial document packet - pay stubs, bank statements, tax forms - and extract structured fields in one pass.
Here's the pipeline:
1. Parse the PDF page-by-page. Classify each page and group into logical documents.
2. Extract structured fields using document-specific schemas. Every field grounded to its exact location.
3. Claude agent applies underwriting rules - DTI ratio, income validation, fraud detection. Returns decision with reasoning.
4. Manager agent reviews the decision. Scores risk. Can override. Escalates edge cases to human review.
The best part: every extracted field is traceable back to its exact location in the source document. Bounding boxes. Confidence scores. Full visual grounding.
Extract once, then run unlimited scenarios. Change the loan amount or debt and get a new decision instantly without re-uploading.
Code is open source. Link in the comments!
1
2
3
352
May 6
ADE is now live on AWS Marketplace! 🚀
For teams already running on AWS, this means no separate procurement process or vendor approvals.
Deploy Agentic Document Extraction (ADE) against your existing committed cloud spend and go straight from evaluation to production.
ADE processes complex documents - financial reports, insurance claims, medical records - using a schema-driven approach that keeps context across pages and links every extracted value back to its exact source location in the document.
Supports cloud and VPC deployment for teams that need document processing to stay within their own infrastructure.
1
3
8
289