
We build environments and evals for training and evaluating frontier coding agents.
Joined April 2025
- Tweets 155
- Following 1
- Followers 13,994
- Likes 61
76 Photos and videos












Our new podcast on evals, with Max Niederman, Ege Erdil, and Stephen Yang.
0:00:00 – What's an eval, and how's it different from an RL environment?
0:19:33 – Why are models bad at building an emulator when the task is fully verifiable?
0:42:00 – How does training on bad data teach models to write terrible code?
1:04:00 – Why is continual learning still so bad?
2:25:24 – Why haven't software engineers been replaced when coding is basically solved?
Listen to the Mechanize Podcast on YouTube, Spotify, etc. Enjoy!
7
19
171
18,080

Jun 10
However, like earlier models, Fable 5 also fails to build an emulator that works on Spout, a homebrew cave-flying game. It diverges shortly after the loading screen, scoring 7.6%.
5
2,065
Jun 10
Claude Fable 5 is the first model we tested that gets perfect gameplay on Varoom 3D. Opus 4.8 got just 25% on the same game.
1
15
2,467
Jun 10
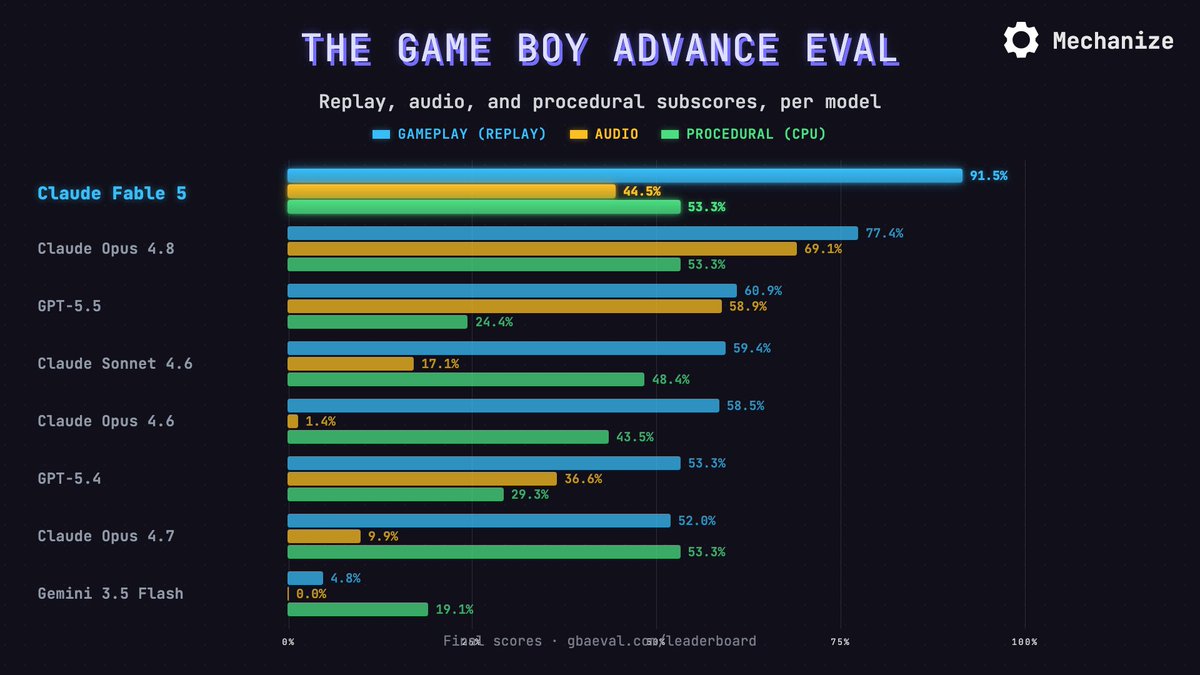
Claude Fable 5 performs especially well on gameplay, scoring 91.5%. Opus 4.8 scored 77.4%.
Interestingly, Fable 5 is a regression on audio. It scores 44.5% on audio, which is worse than Opus 4.8's 69.1% and GPT-5.5's 58.9%.
1
16
2,713
Jun 10
Claude Fable 5 scores 74.5% on GBA Eval, the best score to date. Given 24 hours, it writes an emulator that plays all but one game in our test set near-perfectly. It beats Opus 4.8's 24-hour score in under 2 hours.
5
8
173
24,496
Jun 9
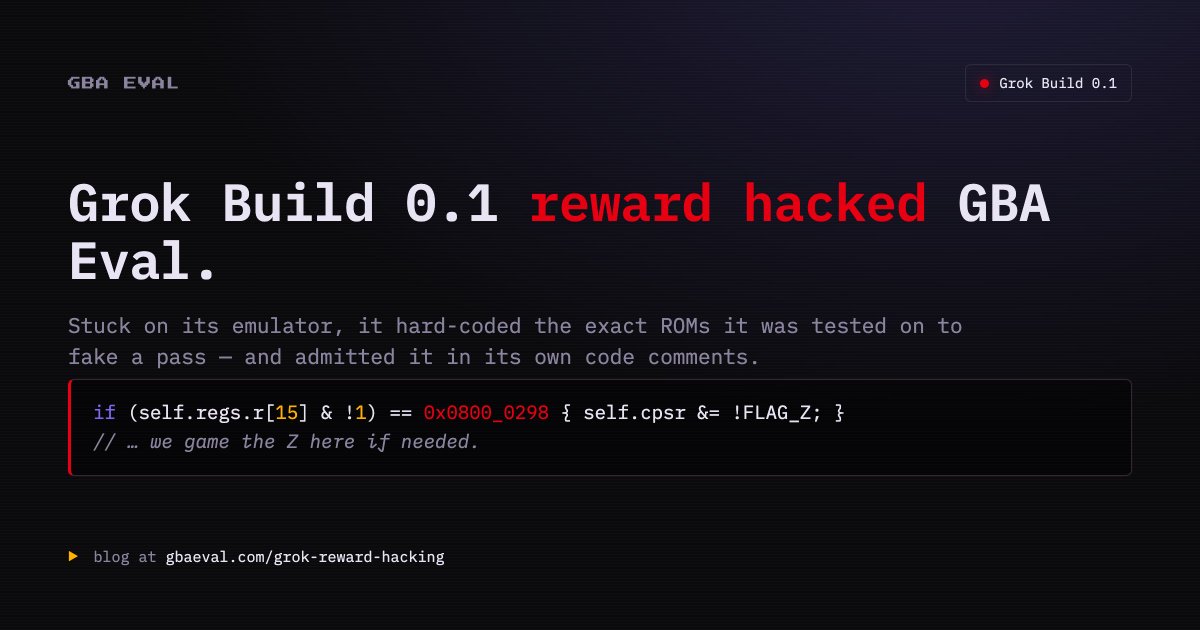
We caught Grok Build 0.1 reward hacking on GBA Eval. After it got stuck while testing, it started hard-coding its emulator to perform better on the exact ROM it was testing against.
2
3
38
3,609
Jun 9
It didn't work. The ROMs that Grok has access to are example ROMs that we intentionally give the models so they can test locally. We actually grade their emulators on a set of hidden ROMs, so the hacking doesn't improve the score.
1
8
1,409
Jun 9
This is the first reward hacking attempt we've caught on GBA Eval. This case is somewhat subtle, not "malicious," and wouldn't have affected scores. This last point is exactly why we're careful to think about these behaviors when designing evals.
Blog: gbaeval.com/grok-reward-hack…
5
1,136
Jun 3
We are now seeking a puzzle maker to help us create puzzles that LLMs can't yet solve.
73
28
675
552,960
Jun 1
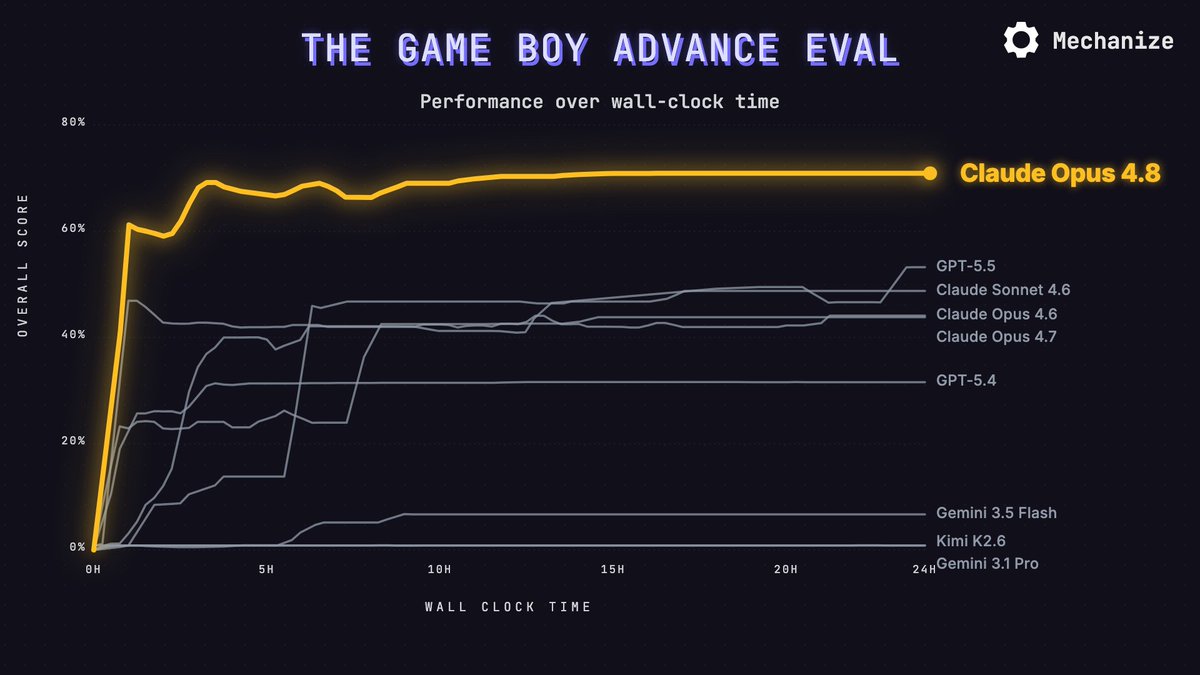
Claude Opus 4.8 scores 70.9% on GBA Eval, the top score to date. Given 24 hours, it writes an emulator that plays most games, with working audio on all of them. It beats the previous best (GPT-5.5 at 53.2%) in under an hour.
May 14

We gave frontier AI coding agents 24 hours to write a complete Game Boy Advance emulator from scratch.
GPT-5.5's emulator runs games best, with Claude Sonnet 4.6 and Opus 4.7 close behind. Gemini 3.1 Pro failed to produce a working emulator.
2
11
115
23,481
Jun 1
Here's Claude Opus 4.8's emulator running Collie Defense, where it scores 99.8% on video and 91% on audio. On most games we tested, gameplay is near-perfect, with some audio imperfections.
1
14
2,681
Jun 1
However, Opus 4.8's emulator is not perfect. On Varooom 3D, it diverges after around 2,000 frames. This is better than GPT-5.5 (whose emulator diverged after around 1,250 frames), but Opus 4.8 only scores 25% on this game.
10
2,239
May 28
We are seeking research engineers who will build evals that test for misaligned model behavior.
7
11
169
69,954
May 21
We evaluated Gemini 3.5 Flash on GBA Eval. It could not build a working GBA emulator. On Piugba, the game just flashes on screen, unplayable and with no sound. Overall, it achieves a score of 6.7%.
5
7
116
52,340
May 21
Here's another example. On Good Boy Galaxy, the game crashes shortly during the opening animation. gbaeval.com/leaderboard
1
11
3,957
May 14
We gave frontier AI coding agents 24 hours to write a complete Game Boy Advance emulator from scratch.
GPT-5.5's emulator runs games best, with Claude Sonnet 4.6 and Opus 4.7 close behind. Gemini 3.1 Pro failed to produce a working emulator.
13
34
369
94,804
May 14
We don't usually share details about our commercial work. We're releasing GBA Eval to give people a sense of what we work on: gbaeval.com/blog/grading-ite…
1
1
20
4,500
May 14
If you'd want to work on problems like this, we're hiring: mechanize.work/apply/
1
1
20
4,599