
AI Engineer | Software Engineering | Building AI agents @ Redis (@RedisInc) | linktr.ee/raphaeldelio
Joined May 2022
- Tweets 2,808
- Following 433
- Followers 929
- Likes 5,209
480 Photos and videos










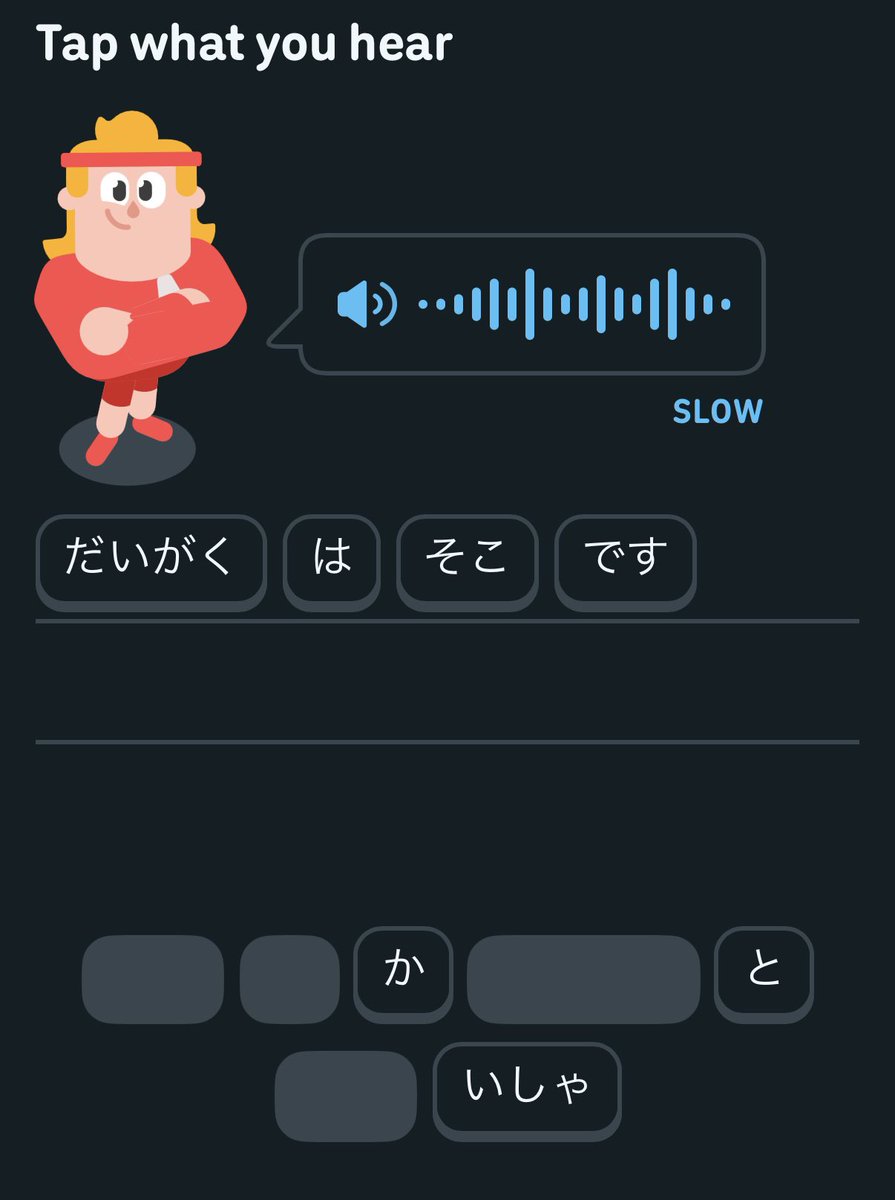


Jun 6
“Architecture is not good or bad. It is suitable or not suitable.” Gregor Hohpe
2
66
Jun 5
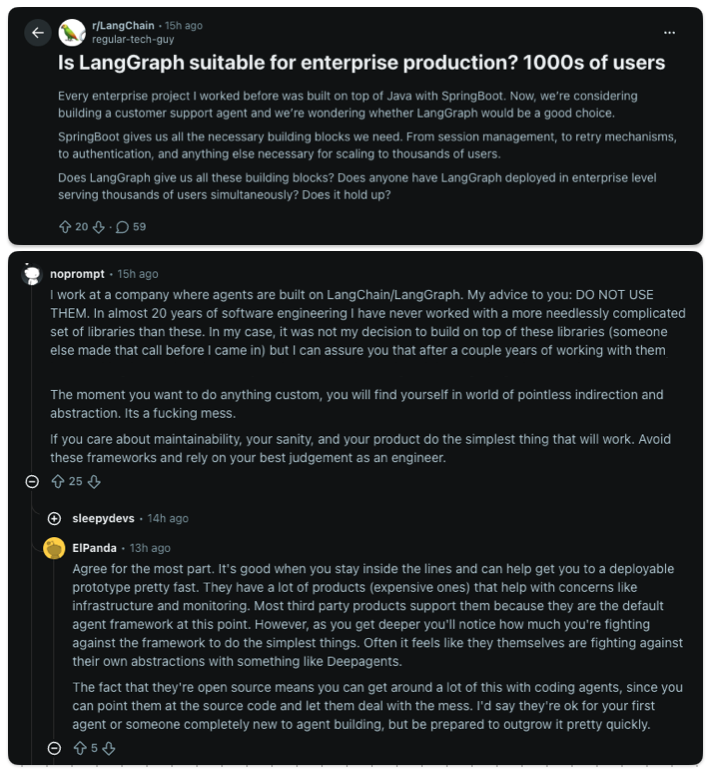
This is the number one discussion in the LangChain subreddit today. And it shows a large gap between personal/small projects and enterprise systems.
LangChain has been around for about four years. LangGraph has been around for about two. That is still early for enterprise software.
I understand why developers want to use them. Early in my career, I wanted to try every new technology too. I cared more about learning the tool than thinking about who would maintain the system years later.
One of my first teams had a lot of freedom to choose technology. We ended up with multiple services solving similar problems because different developers wanted to try different stacks.
That does not work well in enterprise environments.
A CTO, tech lead, senior developer, or business owner has to think about hiring, maintenance, production support, migration costs, and long term risk.
Now, what caught my attention was the response from the LangChain subreddit itself. You would expect the community to defend the technology, but most people did the opposite. They told OP not to use it in production.
The general consensus was that it can be useful for POCs, but painful in production.
That's why battle tested frameworks and stacks keep resurfacing. Enterprise teams tend to choose technology that has already survived years of production use across many companies.
Check the whole thread: reddit.com/r/LangChain/comme…
80
Jun 1
Back in March, I needed to move faster on a few implementations. Codex could plan a long running task, but the work still took too long. It also tended to lose track of what it had committed to at the start.
At the time friend introduced me to the idea of atomic tasks. The idea was to split work into tasks that would not clash with each other, so multiple subagents could work on the same feature without needing separate worktrees or resolving merge conflicts.
I ended up building a skill for this back in March. It plans the full implementation, creates md files for each phase, defines which phases can run in parallel, starts the subagents automatically, and tracks implementation status inside the md files.
Before completing an implementation, an extra subagent is dispatched to confirm that the task has been correctly implemented.
At the end of April, I also ran some experiments where an agent worked for around 4 hours triggering subagents and completing all phases of an implementation without losing context.
Today I realized I've been using it practically everyday since March, so I decided to share it in case anyone wants to also give it a try:
github.com/raphaeldelio/agen…
2
57
May 31
The live agent activity stream is possible thanks to NDJSON (Newline Delimited JSON), where each event is sent as an individual JSON object separated by a newline. This allows the UI to display agent thoughts, tool calls, and intermediate results as they happen, without waiting for the entire workflow to finish.
120
May 29
I was on a call with @DamienCacheux yesterday where we were discussing about our experimentations with Spring AI when the agent I've been building threw this exception out of the sudden.
Damien promptly said it was a good thing to see this error wasn't something only he was facing while using Spring AI. 😅
Turns out my chat endpoint was using Spring MVC async streaming. If the response generation takes longer than the configured MVC async timeout, Spring closes the request before the agent finishes.
With embedded Tomcat, that default is 30 secs. For an agentic application, that's not enough,
The OpenAI call then gets interrupted, which is why the stack trace points at Spring AI and OpenAI even though the root cause is the MVC request timeout.
The fix is to increase the Spring MVC async request timeout:
`spring.mvc.async=request-timeout: 5m`
58
May 27
Sempre quis ter um longboard. Comprei um essa semana.
Dia 1: caí igual um saco de batata
Dia 2: andando de boa
Dia 3: aprendendo a surfar nele
Tá me fazendo bem!
1
2
74
May 26
AI engineering is a role that emerged in 2023 as teams started building systems around large language models. It combines machine learning engineering and traditional system engineering.
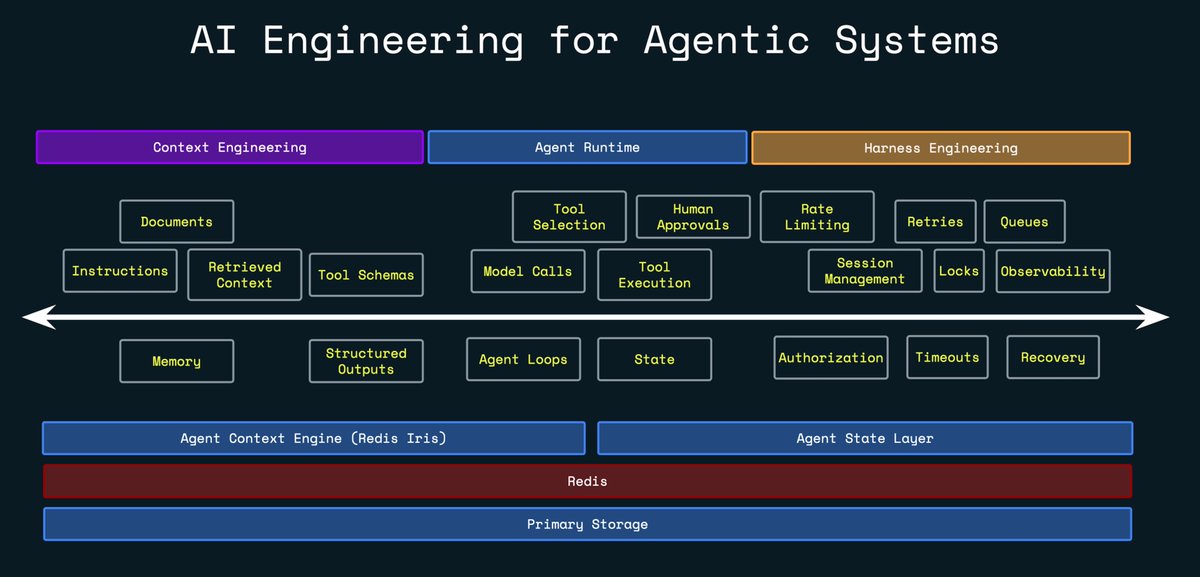
Objectively, AI engineering is the discipline of designing the context, runtime, and harness around AI agents so they can operate as reliable, observable, and scalable systems.
It took us three years to understand what composes this role as we do today.
𝗔𝗴𝗲𝗻𝘁 𝗿𝘂𝗻𝘁𝗶𝗺𝗲 executes the agent loop: model calls, tool calls, control flow, state transitions, and intermediate outputs.
𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 selects, structures, and updates the information the model receives, including instructions, memory, retrieved data, and tool results.
𝗛𝗮𝗿𝗻𝗲𝘀𝘀 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 builds the infrastructure around agent execution: orchestration, isolation, observability, scaling, retries, persistence, and recovery.
Anyone building agentic systems needs to understand all three components.
In my upcoming Redis webinar, we'll dive deeper into 𝗵𝗮𝗿𝗻𝗲𝘀𝘀 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 and focus on three components that matter for reliable and scalable systems:
- Caching
- Session management
- Rate limiting
As an extra, we will also discuss how context engineering fits into agentic system design.
The session takes place next Thursday, May 28.
Don't forget to RSVP: redis.io/resources/videos/se…
77
May 22
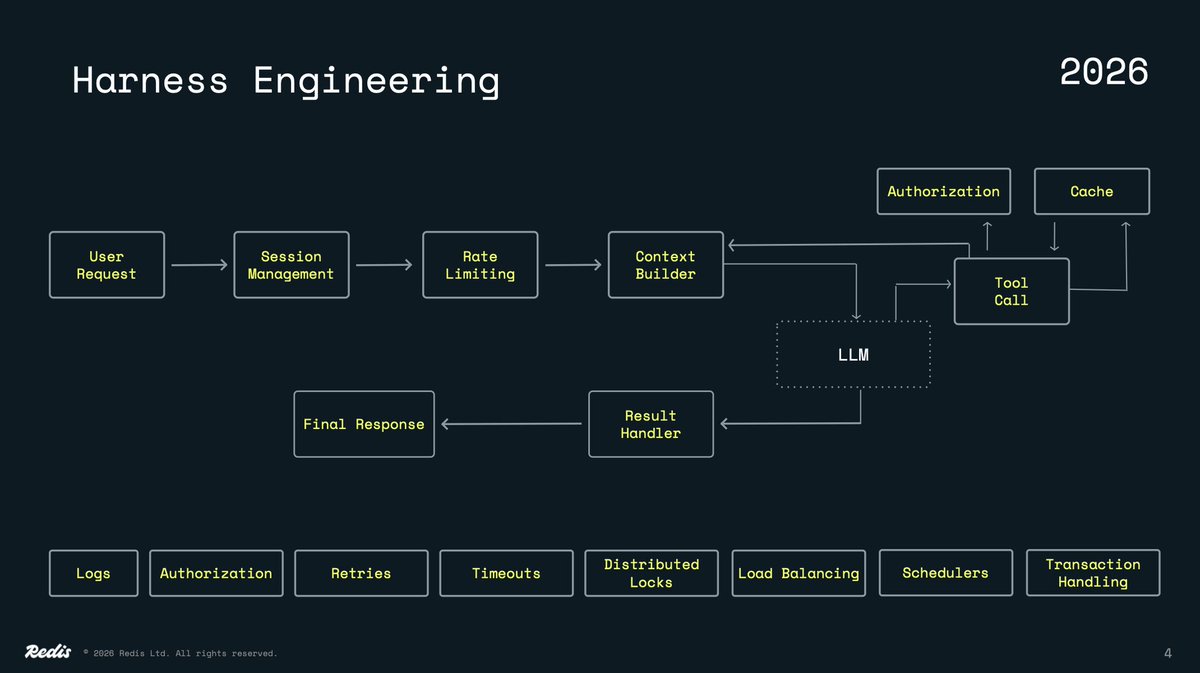
Harness engineering is the discipline of designing the infrastructure, rules, and execution environments around AI agents so they can operate as reliable, observable, and scalable work systems.
It covers the runtime pieces that manage sessions, permissions, tool execution, state, caching, rate limits, retries, logging, monitoring, and failure handling.
System engineering by another name.
This is one of the slides from the session where I'll cover three specific components of reliable and scalable systems:
- Caching
- Session Management
- Rate Limiting
Whether you're a machine learning engineer trying to harness your agents or a traditional software engineer trying to scale your systems reliably you will definitely learn something new in this webinar.
And as an extra, we will also talk about context engineering! All of that around @Redisinc
The session will take place next Thursday, the 26th of May. Don't forget to RSVP!
Webinar:
redis.io/resources/videos/se…
65
May 21
Harness engineering is the buzzword of 2026. But the ideas behind it are decades old.
It turns out that building scalable agents still requires the same systems engineering skills software engineers have relied on for years to build scalable and sustainable systems.
Whether you are building traditional applications or AI agents, mastering concepts like rate limiting, session management, and caching is essential.
Next week, I’ll be leading a webinar covering these topics and discussing why they matter even more in the age of AI systems.
Looking forward to seeing you all there. Don’t forget to RSVP!
redis.io/resources/videos/se…
40
May 20
Agents need low latency access to context. If every request to an agent turns into requests across multiple systems, latency becomes a UX bug. (Tail latency amplification)
This is a problem most agents face because context is usually scattered across the business: CRM data, order systems, support history, docs, user preferences, calendar data, email, tickets, transactions, and product data.
If the agent takes 15 seconds to call different services before responding, the answer might be correct, but the experience already failed.
This is the problem Redis Iris, the newest suite of products released by Redis yesterday, is targeting.
Redis Iris puts Redis in the middle as the fast context layer agents can query while they are reasoning.
As part of Redis Iris, you get:
𝐑𝐞𝐝𝐢𝐬 𝐃𝐚𝐭𝐚 𝐈𝐧𝐭𝐞𝐠𝐫𝐚𝐭𝐢𝐨𝐧: A streaming data integration layer for moving data from source systems into Redis. It can keep Redis updated as the underlying data changes, then reshape that data into structures that are easier for applications and agents to query.
𝐑𝐞𝐝𝐢𝐬 𝐂𝐨𝐧𝐭𝐞𝐱𝐭 𝐑𝐞𝐭𝐫𝐢𝐞𝐯𝐞𝐫: A semantic layer over Redis data. Instead of giving the agent raw keys, hashes, JSON documents, and indexes, you define business entities like `customer`, `order`, or `delivery`. Context Retriever exposes those entities through agent usable interfaces like MCP tools.
𝐑𝐞𝐝𝐢𝐬 𝐀𝐠𝐞𝐧𝐭 𝐌𝐞𝐦𝐨𝐫𝐲: A memory service backed by Redis. It stores short term conversation state and extracts longer term memories from interactions, such as facts, preferences, decisions, or things the agent learned while completing a task.
𝐑𝐞𝐝𝐢𝐬 𝐋𝐚𝐧𝐠𝐂𝐚𝐜𝐡𝐞: A semantic cache for LLM workflows. Instead of matching on exact prompt strings, it caches based on meaning or intent, so similar requests can reuse previous results and reduce latency and cost.
The useful architecture pattern here is that Redis is not the source of truth. Your source systems stay where they are.
Redis becomes the low latency operational layer that agents query while they are reasoning. That matters because agents are not good at dealing with scattered context directly.
If an agent has to inspect raw database structures, infer relationships, call multiple slow APIs, and remember what happened in previous sessions, every request becomes a mini integration project.
If a user asks why an order is late. The agent needs to identify the customer, retrieve the relevant order, inspect delivery state, possibly check policy or restaurant data, pull memory, and generate a response.
The answer is only the visible part. The real work is context retrieval, indexing, memory, and caching underneath.
That is what Redis Iris is trying to package into a more standard agent architecture: model tools Redis backed context layer.
Watch the livestream announcement with @rowantrollope and @simba_khadder: youtube.com/watch?v=7JOnwT1v…
Blog post: redis.io/blog/context-is-all…
59
May 20
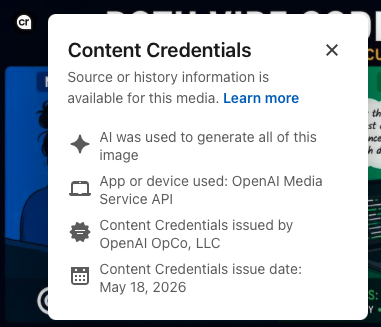
OpenAI just dropped a tool to verify if an image has been generated by one of their products. And LinkedIn is already using it to tag images that were AI made.
The technology is grounded in two mechanisms. The first one relies on the metadata of the image. The second one relies on imperceptible pixels that survive resizing and screenshots.
I don't know if LinkedIn is relying on both, but it's at least checking the metadata.
It also seems to be penalizing posts that contain AI made images given I don't see them as often anymore.
openai.com/index/advancing-c…
openai.com/research/verify/
42
May 18
Conversa muito boa sobre arquitetura na era da IA que tive o prazer de participar a convite da loomi onde falamos sobre os principais desafios ao implementar agents.
O corte que trago aqui é sobre os desafios que o novo produto da Redis, o Agent Memory, ajuda a resolver!
1
67
May 18
O vídeo completo está disponível no YouTube: youtube.com/watch?v=6K_UV7eh…
Redis Agent Memory no GitHub: github.com/redis/agent-memor…
Em breve uma versão managed na Redis Cloud: cloud.redis.io
31
May 13
Happy to announce that I'm returning as the host of the Dutch Kotlin User Group in Amsterdam after a year and a half hiatus!



2
7
169
Raphael De Lio retweeted

May 12
What if memory extraction, management and retrieval were the function of one unified layer instead of several LLM tool-calls?
This was the main point of a recent talk I gave at @DevoxxUK.
When you build an agentic app that depends on memory, a common approach is to define a tool per source. For instance, a search_slack tool first. Then another one for Notion. Then Drive, then meeting transcripts etc. Each new source brings its own retrieval tool, and the agent's tool surface grows one source at a time.
Over time, the LLM starts moving from a reasoning engine to a router. Plus, each tool definition also eats valuable context. The other day, I read an interesting paper summary about tool selection degrading with scale, especially when the tool descriptions are very similar. All of these points in one direction - LLMs shouldn't have to sift through many tools when it wants retrieval.
Here's the interesting idea. What if memory search and retrieval were the function of one unified layer instead? The LLM issues a single query. Behind the scenes, the layer handles retrieval across sources, deduplication, ranking, and provenance. With this, the source becomes metadata on a retrieved memory, not something the LLM uses for routing. This makes your LLM 𝘀𝗼𝘂𝗿𝗰𝗲-𝗮𝗴𝗻𝗼𝘀𝘁𝗶𝗰 𝗯𝘂𝘁 𝗻𝗼𝘁 𝘀𝗼𝘂𝗿𝗰𝗲-𝗯𝗹𝗶𝗻𝗱.
And it's not just retrieval that needs to be answered when working with memory. There are two other primary challenges: 𝗺𝗲𝗺𝗼𝗿𝘆 𝗲𝘅𝘁𝗿𝗮𝗰𝘁𝗶𝗼𝗻 𝗱𝘂𝗿𝗶𝗻𝗴 𝘂𝘀𝗲𝗿 𝗶𝗻𝘁𝗲𝗿𝗮𝗰𝘁𝗶𝗼𝗻 𝗮𝗻𝗱 𝗺𝗲𝗺𝗼𝗿𝘆 𝗹𝗶𝗳𝗲𝗰𝘆𝗰𝗹𝗲 𝗺𝗮𝗻𝗮𝗴𝗲𝗺𝗲𝗻𝘁
A unified layer can potentially handle all three challenges. Extraction happens asynchronously in the background. Lifecycle - data expiry, deduplication, consolidation - becomes a property of the layer rather than something the agent has to reason about. Retrieval becomes a single trusted surface.
There are still a lot of ideas to think through properly - permissions across sources, how aggressive consolidation should be, and when fresh source data should override stored memory. But I like this architectural direction :).
I also had the pleasure of redelivering "Anatomy of Memory in Humans & AI Agents" with my colleague Raphael De Lio (@RaphaelDeLio). Interesting to see how much overlap there is between how human memory is organised and what actually works for agents.
Had a great time at Devoxx. Looking forward to future talks. Massive thanks to the incredible Redis team at the booth! Big thanks to Ricardo Ferreira who spent hours preparing this talk and gave me great tips, which were super useful.
Photo credits: Ebuka Mordi and Dimitris Doutsiopoulos

3
4
214
May 12
I love when users find bugs in my products. It means the product is actually being used.
1
30
Raphael De Lio retweeted

May 9
it’s better to quit
if you can’t keep challenging yourself to do something more complex, just quit building software
people wanna keep getting joy by rewriting the same react component in neovim for the 400th time, or firing up another identical Elixir script on their split keyboard like it’s 2018
> the joy of learning is gone
what they really mean is: i am sad I don’t get to learn a new JS framework
go build something bigger, something that AI won’t one-shot in a single prompt, something you’ll be afraid to run on your own machine
17
6
188
10,991