
Joined October 2016
- Tweets 63,335
- Following 1,922
- Followers 250,496
- Likes 7,904
1,700 Photos and videos













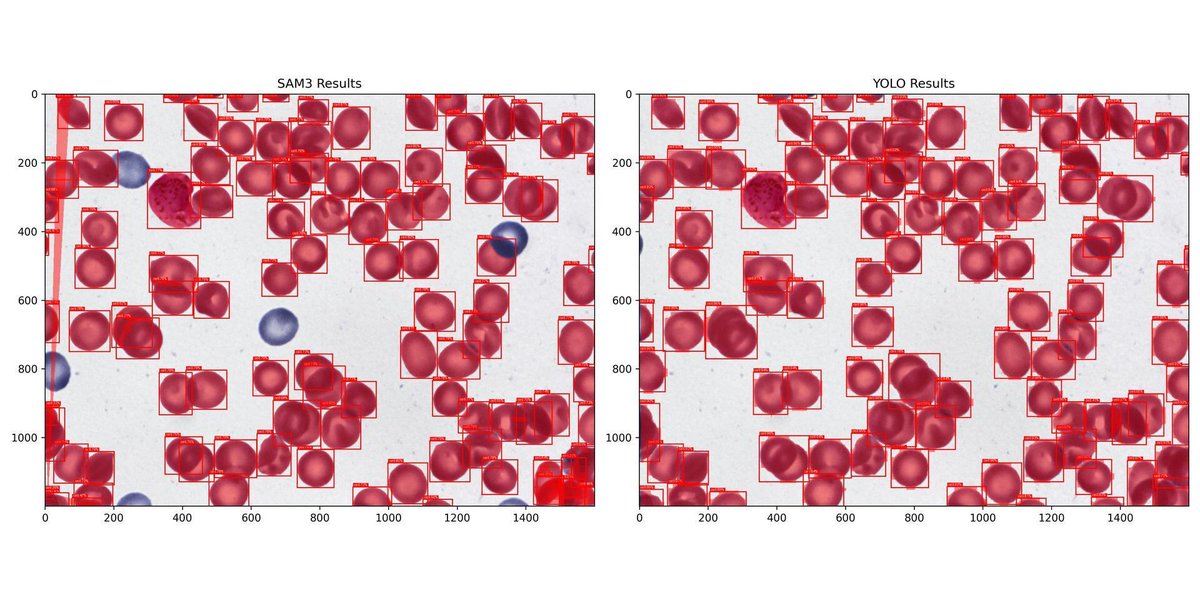


In a helpful new deep dive, Alejandro Alvarez Perez unpacks the factors he considered and tradeoffs he weighed during the long process of choosing a new experimentation platform for his company. towardsdatascience.com/picki…
1
2
715
Taking a travel agency use case as an example, Mahnoor Javed walks us through the process of leveraging Python to create a multi-agent AI system. towardsdatascience.com/build…
5
1,055
How powerful should we allow AI to be? Should we build it so it can override unethical or dangerous prompts from humans?
Nathan Bos shares a thought-provoking reflection on what it means for AI to betray its users. towardsdatascience.com/we-sh…
1
977
Could we combine Elo scores, a Poisson process, and 10,000 simulations to forecast the World Cup winner? Ari Joury gives it a shot in a timely and engaging walkthrough. towardsdatascience.com/who-w…
2
956
3D cloth simulation might sound like a very nice topic, but in Ferran Alia's article on recent breakthroughts in the field, you'll learn about its underlying math and physics, as well as its wide range of practical applications. towardsdatascience.com/the-p…
1
3
1,550
If you're interested in the math and theory behind machine learning, don't miss Conor Rowan and Finn Murphy-Blanchard's novel exploration of sequential fitting in the context of neural networks' spectral bias. towardsdatascience.com/seque…
1
11
1,436
From using hooks to relying on OpenClaw, @EivindKjos shares four actionable ideas to help you get the most out of Claude Code. towardsdatascience.com/4-new…
2
2
1,198
Interested in the emerging field of quantum machine learning?
Don't miss Davinder Singh's new article, which explains how errors arise in classical and quantum systems, why quantum information is fundamentally fragile, and much more. towardsdatascience.com/how-t…
6
1,652
Interested in integrating the power of LLMs into your recommender systems? Piero Paialunga explains how you can improve precision along the way, too. towardsdatascience.com/incre…
6
1,424
Agents require more than just model weights and an API server. Hussen Mohammed Ibrahim breaks down the systems needed to support long-context reasoning and tool use locally.
towardsdatascience.com/the-i…
2
10
1,953
ETL sounds complex until you actually build one from scratch. @IbrahimHabibEg explains the step-by-step process of extracting, transforming, and loading data as a beginner.
towardsdatascience.com/i-bui…
1
3
11
1,833
If you're interested in Python, SLM fine-tuning, and/or emotion recognition, @PetrKorab presents a new, accessible tutorial based on the Mistral Small 3.1 model and a social media-based dataset. towardsdatascience.com/how-t…
3
5
1,233
Interested in automating your prompt-creation workflow? Don't miss W Brett Kennedy's new guide, which leverages DSPy to save practitioners time and effort. towardsdatascience.com/autom…
1
1
8
1,511
Learn how Azure Layout can be used when your RAG workflow requires more advanced, scalable PDF parsing — Kezhan Shi goes into the details in the latest article in the Enterprise Document Intelligence series. towardsdatascience.com/when-…
1
5
1,723
"We’ve seen a massive shift from convolutional networks to the new Transformer architectures that power today’s [LLMs], but the way these networks route information from one layer to another hasn’t changed all that much."
@SteadySurdom explores new research that aims to address this status quo. towardsdatascience.com/why-t…
1
5
1,662
Follow along as @ibbysalam continues his journey into the nitty-gritty execution details of data engineering. His new article focuses on ETL pipeline pain points. towardsdatascience.com/i-tho…
4
1,390
A story about a broken printer inspired Shuyang to dig into a much bigger and more consequential question: is language primarily a visual system from the perspective of a language model? towardsdatascience.com/is-la…
2
1,251
For his latest technical deep dive, Chien Vu Minh takes a detailed look at Claude's new ability to write its own, task-specific harnesses on the fly. towardsdatascience.com/a-har…
1
1
1,099
Towards Data Science retweeted

Jun 12
The second part of my beginner's guide to PySpark just dropped on @TDataScience . In it, we take your skills to the next level by discussing performant data handling.
Read it for free using the link below,
towardsdatascience.com/pyspa…
1
7
1,169
"Should an agent learn only from the behavior it is currently using, or can it also learn from behavior generated in some other way?"
Ananya Bhattacharyya explains why this choice has far-reaching implications around exploration, safety, and efficiency. towardsdatascience.com/the-f…
6
1,180