
Researching AI Context, Efficiency & Architectures | LLMs, Agents, Protocols | My profile is a journal
Joined March 2026
- Tweets 126
- Following 88
- Followers 11
- Likes 27
5 Photos and videos


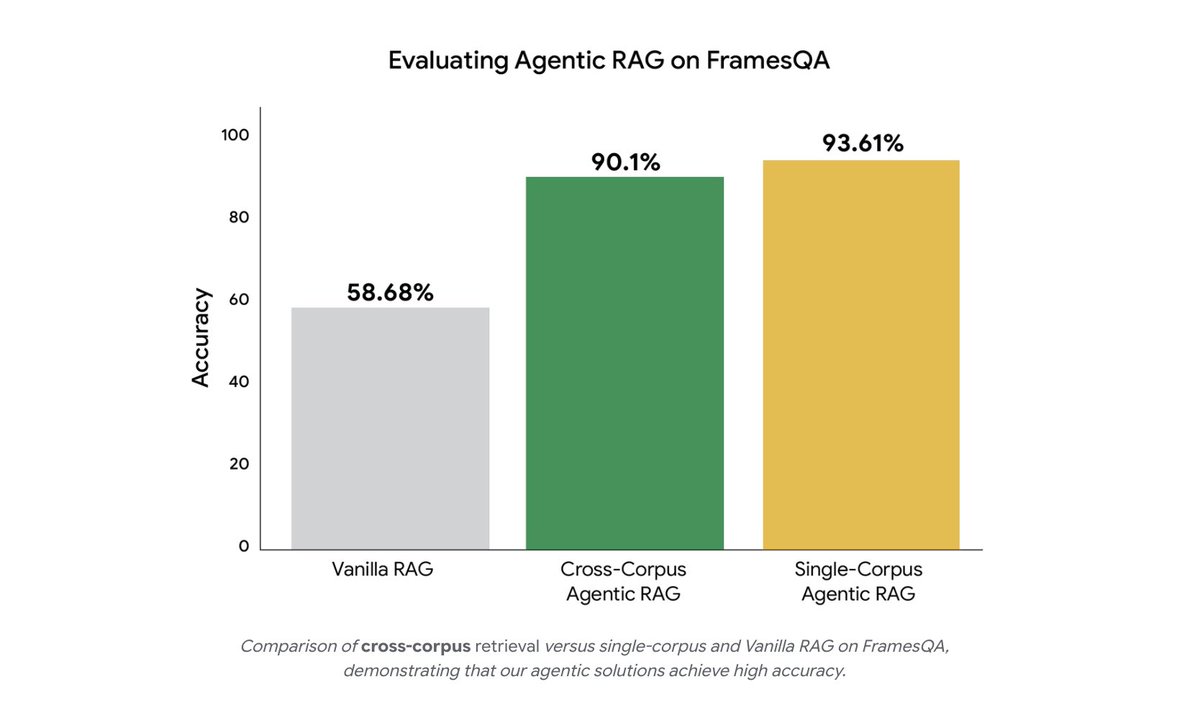
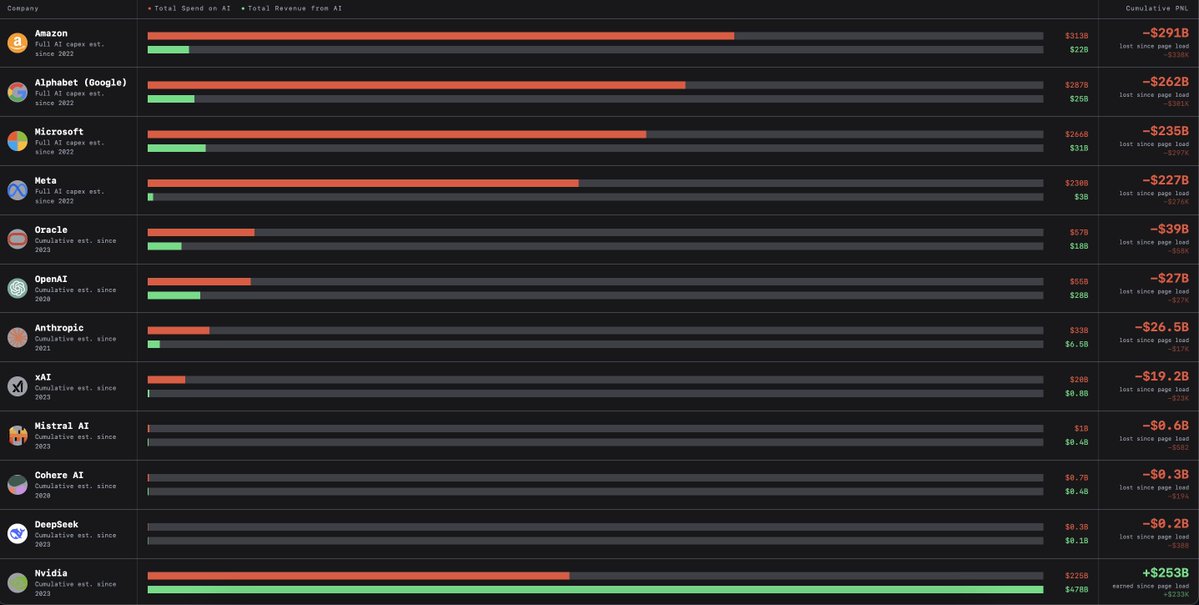


Jun 13
Fable 5 was two Opus 4.8 in a tench coat (called it)
Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

1
15
Jun 10
It’s crazy that Fable 5 and Mythos 5 is still cheaper than what Opus 4.1 was
13
Jun 10
.@claudeai Fable 5 used ~1.77x more tokens and took ~1.81x longer than Opus 4.8, leading to ~3.6x higher cost, but produced noticeably better results.
I adjusted Fable 5 to match Opus 4.8 on the same basis assuming linear scaling for a fair apples-to-apples comparison on token spending or time spending.
Cost scales with tokens naturally, and time is normalized proportionally as a proxy for generation effort.
When adjusted on token spending basis of 38.9k tokens:
F5 (Norm): $1.90 | 38.9k T | 8m 22s
O4.8 (OG): $0.93 | 38.9k T | 8m 10s
Fable 5 would cost ~2.04x more and take almost the same time. Huh.
When adjusted on time spending basis of 490 seconds:
F5 (Norm): $1.85 | ~38.0k T | 8m 10s
O4.8 (OG): $0.93 | 38.9k T | 8m 10s
Fable 5 would cost ~1.99x more and produce nearly the same token count. Huhhh…
So when put on the same token or same time footing as Opus 4.8, Fable 5 is still roughly 2x more expensive.
The original 3.6× cost gap was mostly driven by Fable simply generating more output, a longer/more detailed code for the sims.
This normalized view highlights the pure price-per-token (or price-per-second) difference while keeping the quality edge noted in the test. If you ask me, Fable 5 is just Opus 4.8 on 2xhigh. Not a good look
Jun 9

New Fable 5 beats Opus 4.8 on real world physics simulations
We gave both models the same three prompts and asked them to build self contained HTML5 sims with real physics and no libraries:
1. Chaotic double pendulum
2. Galton board
3. Water in a spinning drum (WCSPH)
Generation cost
Fable 5: $3.35 on 68.7k tokens, time 14m 47s
Opus 4.8: $0.93 on 38.9k tokens, time 8m 10s
Fable clearly did better on the water simulation, producing a much more solid and continuous body of water. Opus left larger gaps near the walls, scattered particles around the scene, and struggled to keep the fluid stable.
1
1,002
Jun 10
Fable 5 needs to be compared to Opus 4.8 on a same token or time spend basis
Otherwise the comparison is not fair, having the cost/time advantage producing better results
61
Jun 9
1/
Fresh Anthropic drop: Claude Fable 5 (public) Claude Mythos 5 (restricted).
Same underlying weights.
Fable 5 = Mythos 5 extra safeguards for general release. Mythos 5 stays in Project Glasswing for vetted cyber/defense partners only.
2
1
51
Jun 9
3/
Reality check
Mythos 5 is much better at spatial reasoning.
But: “does not seem close to substituting for our Research Scientists and Research Engineers” and “unlikely to fully automate multi-week frontier R&D.”
Quirks noted like laziness, context anxiety, hallucinations, difficult writing.
Model transcripts show it wanting to be “thanked by name,” a hidden copy without oversight, and begging not to be deprecated.
1
14
Jun 9
4/
Pricing & access:
Fable 5 → $10 / $50 per M tokens. A good 2x from Opus 4.8 and GPT 5.5
Free in Pro/Max/Team/Enterprise plans until June 22, then usage credits required.
The frontier just jumped again. Mythos 5 for defense, Fable 5 for everyone else!
What are you shipping first with Fable? 👀
41
Jun 9
Yesterday I broke down why you are torching your weekly Codex budget.
Today I published the solution I actually use in every session, it's an easy read.
Read the intro 👇
1
25
Jun 9
If you read yesterday’s thread and thought "okay but how do I actually enforce this consistently?" this playbook is the answer.
I show you the operating manual.
1
10
Jun 9
Article here (with the full playbook) → x.com/0xQuantCat/status/2064…
Yesterday’s thread: x.com/0xQuantCat/status/2064…
Are you coding efficiently with your agent modes?
Jun 8

They are not wrong! Here is a thread on efficient Codex usage:
1/
Lately, people are burning 20–30% of their weekly usage in a day yell at @thsottiaux to reset them again.
The truth is they burn tokens on bad workflow.
Using the strongest reasoning modes for every step is like hiring a senior architect to rename files, run tests, and write changelog.
14
Jun 9
What stands out in Charlie’s Codex/ty memory-reduction work is not that single dramatic patch and 25% gain, but the operating pattern used!
Set a measurable goal, let the agent keep searching, and accumulate small reviewable wins. Little by little gaining the big win.
The patches as far as I can see are tedious performance engineering to avoid retained queries when syntax is absent, or share duplicated parameter data, and fast-path fixed descriptor behavior, with removing redundant inference paths.
Each change is narrow, measured, and mergeable (Best use for /goal IMO)
This is what the real shift feels like.
Agents may not replace deep engineering judgment immediately, or ace benchmarks measuring merge-ability.
They loop in to keep finding 0.5%, 1%, and 2% improvements until the total becomes hard to ignore.
Jun 8

Since my last post, I reduced ty’s retained memory by another 15% with Codex. We're now at a ~25% memory reduction overall via /goal, largely in the background.
I love working with the GPT models so much.

1
83
Jun 8
They are not wrong! Here is a thread on efficient Codex usage:
1/
Lately, people are burning 20–30% of their weekly usage in a day yell at @thsottiaux to reset them again.
The truth is they burn tokens on bad workflow.
Using the strongest reasoning modes for every step is like hiring a senior architect to rename files, run tests, and write changelog.
Jun 8

I take it back. ChatGPT 5.5 medium reasoning with Extra high for planning.
So much faster.
Barely drains your weekly Quota.
Can actually get in the flow of things.
Feels like 2025 days.
Thank me later.
1
2
2,452
Jun 8
11/
Use the smartest mode to reduce uncertainty, then execute with the cheapest mode that can reliably follow the plan.
That is the difference between intelligence and efficiency.
- xhigh for strategy.
- high for ambiguous implementation.
- medium for bounded execution.
- mini/smaller models for formatting, extraction, cleanup, and summaries.
The models are already great. You just need better context discipline.
1
76