
Research Engineer @GoogleDeepMind working on video understanding.
Joined June 2008
- Tweets 592
- Following 243
- Followers 413
- Likes 1,539
37 Photos and videos








Tobias Weyand retweeted

May 22
Can't believe we're getting this before GTA 6
May 21

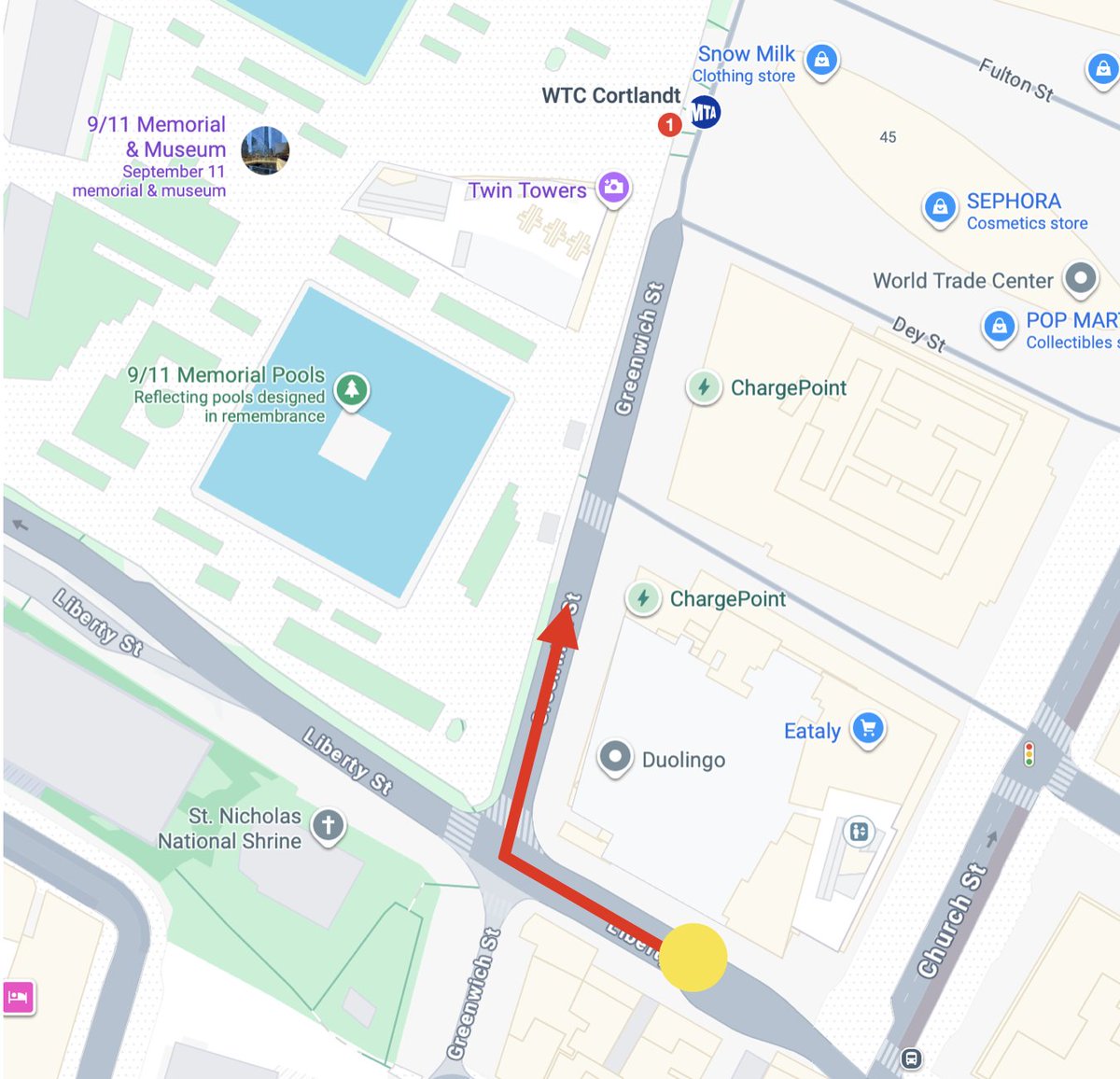
I uploaded a screenshot of Google Maps to Gemini Omni with a route drawn on it.
Then I prompted it to create a first person view of someone driving a taxi cab along the route in the reference image.
Pretty close to the real thing.
17
84
1,610
228,765

22 Oct 2025
Attending #ICCV2025? Come chat with us about our Minerva dataset that tests if models can truly reason about videos! 🕵️♀️
@ahmetius and @SachitMenon will be presenting the dataset at Poster Session 5 tomorrow (Thurs, Oct 23) morning. Find them at poster #391.
10 May 2025

We're excited to release Minerva 🕵️♀️, a benchmark to evaluate if AI can truly reason about videos, from spotting game-changing moments in sports 🏀 to understanding character motivations in short films 🍿. We provide the "why" behind the answers! Pointers below 👇
1
3
5
2,333
28 Aug 2025
Our team is hiring! If you have experience in video understanding and/or generation, join us @GoogleDeepMind and help push the frontiers with Veo and Gemini!
26 Aug 2025

We're hiring at @GoogleDeepMind! Looking for a talented Research Engineer to help build the future of Video generation and undrestanding (Veo and Gemini).
Apply here: job-boards.greenhouse.io/dee…
1
130
18 Jun 2025
Excited that our Minerva and Neptune datasets are both featured in the Gemini 2.5 tech report! Minerva is among the most challenging video benchmarks with a large gap between SotA (Gemini 2.5 Pro, 67.6%) and humans (92.5%).
github.com/google-deepmind/n…
17 Jun 2025

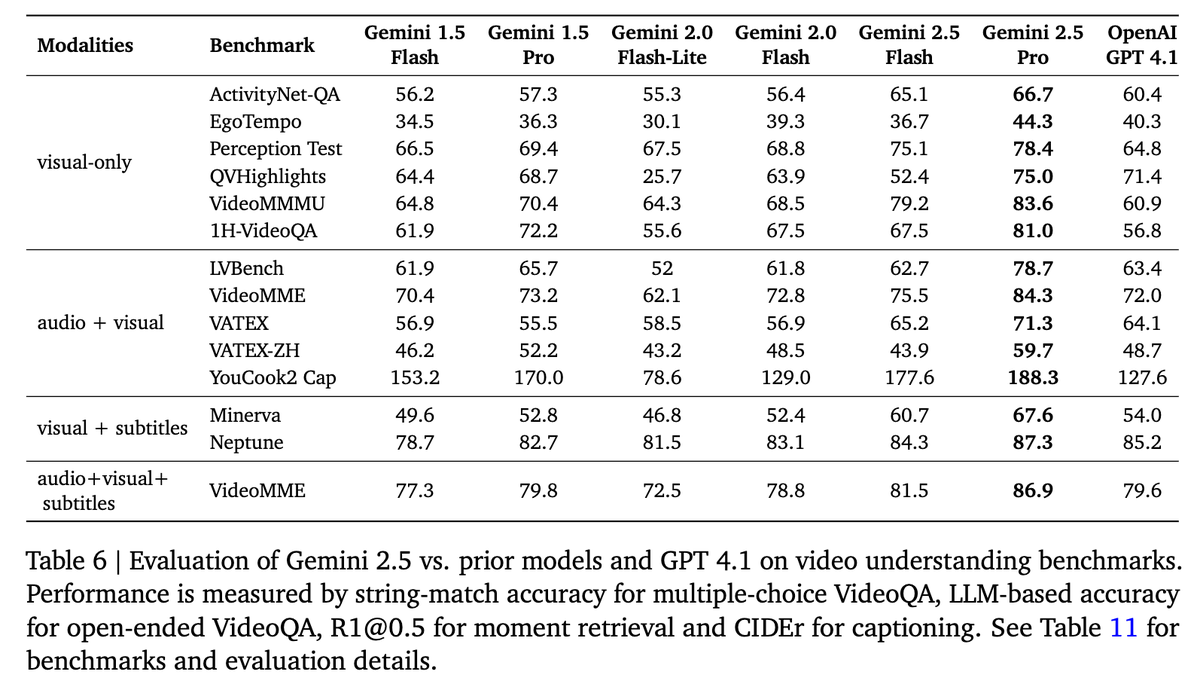
The newly generally available Gemini 2.5 Flash and Pro are even better at video understanding than the versions we shared in the blog a month ago, see more details in the tech report 😀
1
6
384
Tobias Weyand retweeted

10 Jun 2025
Excited! VideoPrism-Base/Large are publicly available now: github.com/google-deepmind/v…
Check it out if you need a versatile video encoder for video-language or video-native tasks. Feedback appreciated!

Introducing VideoPrism, a single model for general-purpose video understanding that can handle a wide range of tasks, including classification, localization, retrieval, captioning and question answering. Learn how it works at goo.gle/49ltEXW
3
21
2,277
12 May 2025
Gemini 2.5 Pro sets the state of the art on our newly released Minerva video reasoning benchmark by scoring 63.5%.
📜 Paper: arxiv.org/abs/2505.00681v1
📊 Dataset: github.com/google-deepmind/n…
12 May 2025

A lot of work went to make Gemini 2.5 SOTA at video understanding, check out this 🧵 for more details!
Looking back at where we were a year ago, the progress really feels phenomenal!
So many things to unlock and enable from video 🎥 and we are only getting started!
3
17
4,549
10 May 2025
We're excited to release Minerva 🕵️♀️, a benchmark to evaluate if AI can truly reason about videos, from spotting game-changing moments in sports 🏀 to understanding character motivations in short films 🍿. We provide the "why" behind the answers! Pointers below 👇
1
1
12
1,333
10 May 2025
The newly released Gemini 2.5 Pro (Preview 05/06) sets the state-of-the art on Minerva with 63.5% accuracy. Human accuracy is 92.5%.
developers.googleblog.com/en…
1
3
176
10 May 2025
Listen to the @agi_breakdown episode on Minerva here:
aibreakdown.org/arxiv-paper-…
3
106
4 Dec 2024
Excited to share Long-Video Masked Autoencoder (LVMAE) our team just published at @NeurIPSConf! We boost the context length of video models using an adaptive decoder and a dual-masking strategy and achieve SotA on several video benchmarks.
Paper: arxiv.org/abs/2411.13683
Training video understanding models on longer contexts is computationally intensive. To address this, we present a novel approach that reduces the computational load while also improving the quality of the learned representations. More at: goo.gle/4fW5aIc
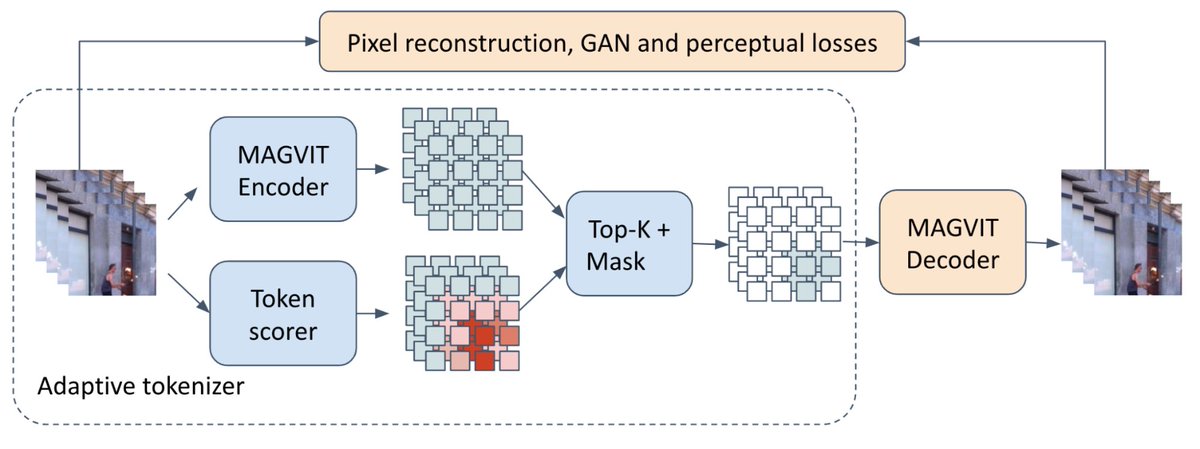
ALT Illustration of the adaptive tokenizer.
4
321
14 Nov 2024
Thank you @JeffDean , very much appreciate the boost! This is really a team effort with my amazing colleagues @NagraniArsha, Mingda Zhang, @raminia, Rachel Hornung, @nitesh_ai, @under_fitting, Austin Meyers, @zhouxy2017, @BoqingGo, @CordeliaSchmid, @sirotenko_m, @ZhuZhu66595.

A nice new benchmark for long video understanding by Tobias Weyand @0xtob and others. This is likely to be one of the new frontiers of capabilities for large-scale multimodal models, and it's great to have a new benchmark to assess others in this area.
6
27
16,801
12 Nov 2024
Excited that our work on Long video understanding is being featured by @GoogleAI !
Can #AI truly understand long videos? Tobias Weyand & the Google Research team are testing the limits w/ Neptune, an open-source benchmark for long video understanding. Dive into the details & see how AI tackles temporal reasoning, cause & effect, & more →goo.gle/4esTTNM
2
10
844
23 Sep 2024
The other day I let my kids talk to Gemini live. Today my 3 year old asked my 6 year old: "Can you tell me a joke?" - 6 year old: "Sorry, I'm just a language model."
8
405
16 Sep 2024
Excited to share what our team has been working on! With expanding context lengths, frontier models are able to process longer and longer videos. But how well do they really understand them? Today we release Neptune, a challenging benchmark for long video understanding.
Datasets for evaluation of long video understanding are rare. So with this in mind, today we describe Neptune, an open-source evaluation dataset that includes multiple-choice and open-ended questions for videos of variable lengths up to 15 minutes. More →goo.gle/3B41nZV
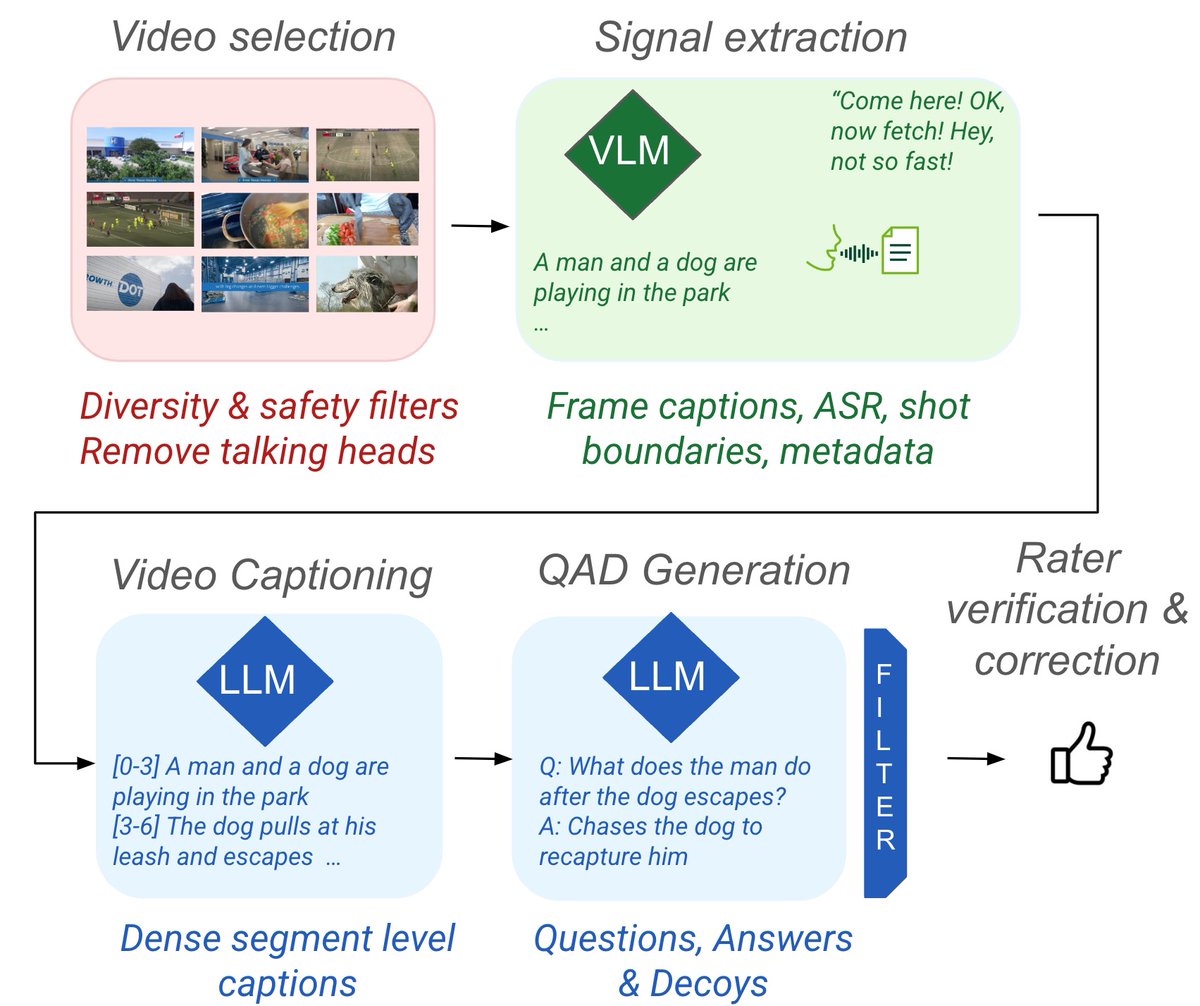
ALT The Neptune data pipeline.
1
3
15
4,045
20 Aug 2024
New long video understanding benchmark from my colleagues @GoogleDeepMind pushing LLMs to their limits!
20 Aug 2024

Can current LLMs solve video reasoning Qs like:
Over 1-hour, when does the camera holder go down stairs... ??
Watch the teaser... Can you distinguish up/down stairs - p.s. stairs are not visible when you go down any
youtu.be/Ddgvr4OReL4
Hour-Long PerceptionTest VQA @eccvconf
6
420

Congratulations to the authors of "VideoPoet: A Large Language Model for Zero-Shot Video Generation" for winning one of this year's @icmlconf Best Paper Awards! #ICML2024
Paper: openreview.net/forum?id=LRkJ…
Blog post: goo.gle/4atanoj

9
47
264
52,087
10 Jul 2024
The @DeutschesMuseum Bonn has an extremely good exhibition on AI that's great for both kids and adults. My favorite is a giant display showing the activations of a 16 layer CNN trained on ImageNet in real time as you show it animal figurines. deutsches-museum.de/bonn/aus…
1
6
306
10 Jul 2024
Another fun one: A Gradient Descent arcade machine that teaches the basic concept in a gamified way.
1
3
87