
273 Photos and videos














سعيد جداً بمشاركة إنجاز جديد 🎉
تم بحمد الله وشكره بعد عمل يوم كامل.
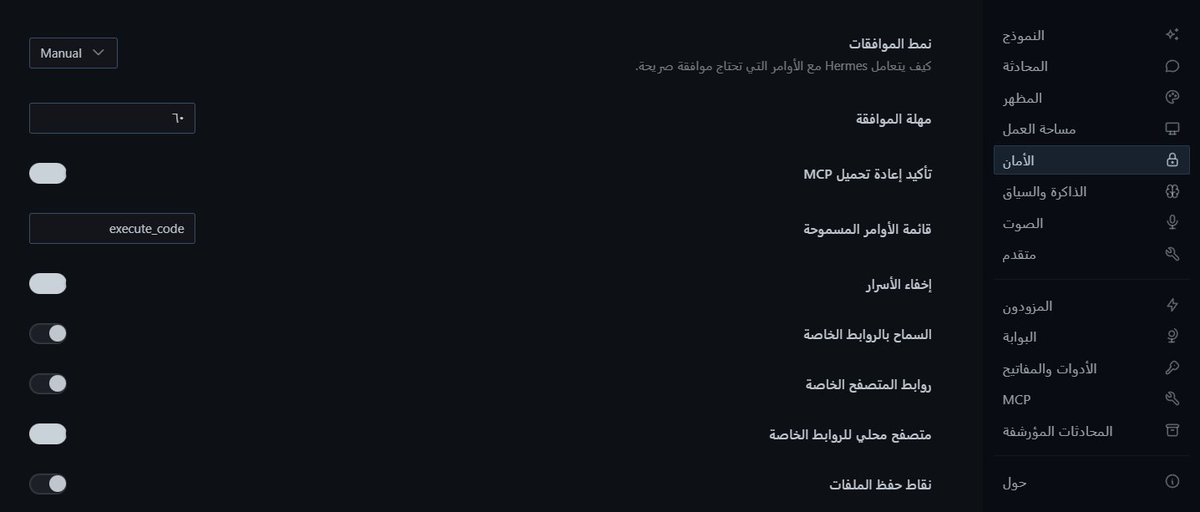
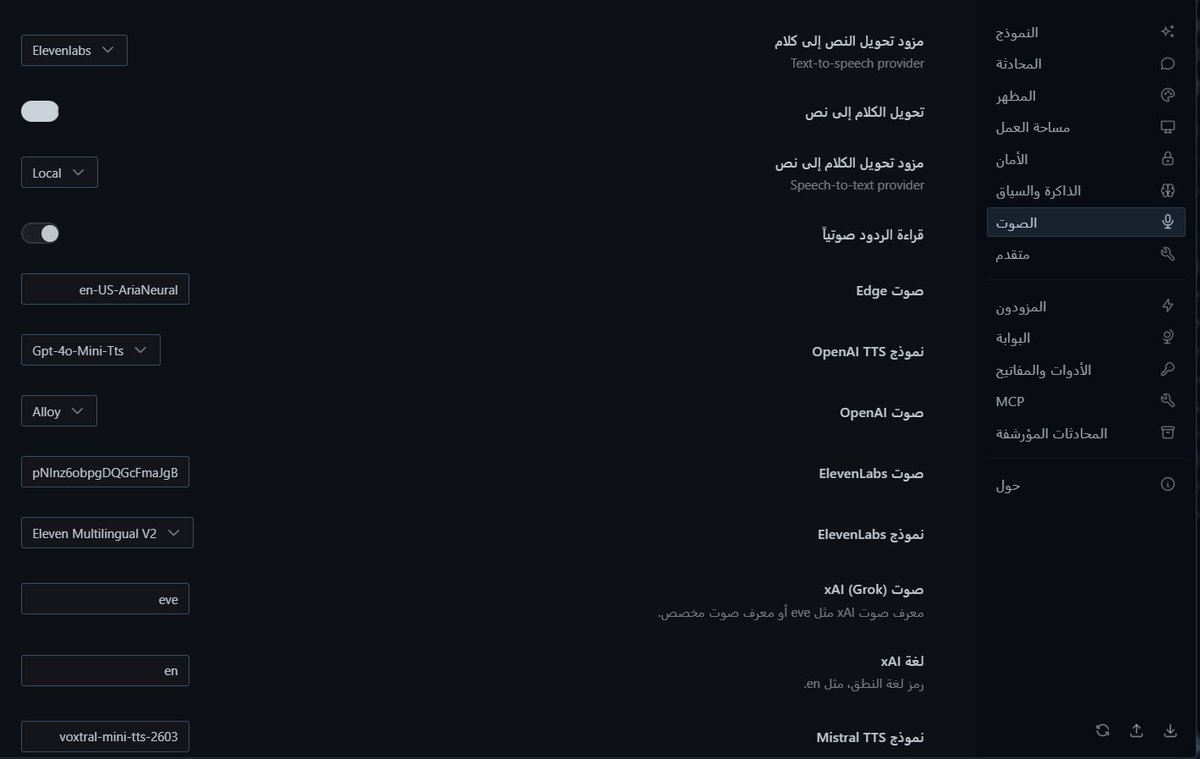
أنجزت تعريب واجهة Hermes Desktop، وقدّمته كمساهمة رسمية إلى مستودع Hermes Agent.
هذا العمل لا يقتصر على ترجمة كلمات فقط، بل يضيف تجربة عربية حقيقية داخل التطبيق:
✅ إضافة اللغة العربية كخيار رسمي في الواجهة
✅ دعم اتجاه RTL حتى تظهر الواجهة بشكل طبيعي للمستخدم العربي
✅ تعريب صفحات الإعدادات والتبويبات الداخلية
✅ تعريب المزودين والحسابات
✅ تعريب أدوات ومفاتيح API
✅ تعريب MCP والمحادثات المؤرشفة
✅ تعريب منطقة الإجراءات الحساسة Danger Zone
✅ إضافة اختبارات للتأكد من أن التعريب لا يكسر الواجهات الحالية
لماذا هذا مهم؟
لأن أدوات الذكاء الاصطناعي مفتوحة المصدر يجب أن تكون متاحة وسهلة الاستخدام لمجتمعات أكثر، وليس فقط لمن يجيد الإنجليزية.
اللغة العربية يستخدمها مئات الملايين، ودعمها بشكل صحيح يحتاج أكثر من ترجمة نصوص؛ يحتاج احترام اتجاه القراءة، وضبط الواجهة، والتأكد من أن التجربة كاملة ومفهومة.
الهدف من هذه المساهمة هو جعل Hermes Desktop أكثر قرباً للمستخدمين العرب، سواء كانوا مطورين، باحثين، فرق تقنية، أو مستخدمين يريدون تجربة AI Agent قوية بلغتهم.
تم فتح Pull Request رسمي للمراجعة وبانتظار الموافقة بحول الله.
خطوة صغيرة، لكنها مهمة، نحو حضور عربي أقوى في أدوات الذكاء الاصطناعي مفتوحة المصدر.
#Hermes #OpenSource
12
12
115
7,772
أعتقد أن مايكروسوفت غيّرت قواعد اللعبة أمس بتقنية SkillOpt! تخيل أنك تزيد أداء GPT-5.5 بنسبة 23 نقطة كاملة فقط بملف Markdown عادي، وهذا ليس مزحة.
التقنية الجديدة، والتي طورتها مايكروسوفت مع ثلاث جامعات صينية، تعمل على تدريب "مهارات" لوكلاء الذكاء الاصطناعي كوثائق تعليمات خارجية. الأمر المثير حقًا هو أنها لا تعيد تدريب النموذج الأساسي مثل GPT-5.5، بل تعدل ملف Markdown بسيط يتراوح حجمه بين 300 و 2000 توكن.
العبقرية هنا في "المُحسِّن اللغوي" المنفصل. هذا المُحسِّن يراقب أداء وكيل الذكاء الاصطناعي، يحلل أخطاءه ونجاحاته، ثم يقترح تعديلات صغيرة ودقيقة على ملف Markdown هذا. هذه التعديلات تُقبل فقط إذا أظهرت تحسنًا حقيقيًا في الأداء على مجموعة تحقق مخصصة.
لقد أظهرت الاختبارات نتائج مذهلة. SkillOpt رفعت متوسط أداء GPT-5.5 بحوالي 23 نقطة عبر ستة معايير مختلفة شملت البحث وجداول البيانات والرياضيات. الأجمل من ذلك هو قابلية النقل؛ المهارة المدربة على نموذج كبير يمكنها تحسين أداء نماذج أصغر، بل وتعمل بين بيئات وكلاء مختلفة مثل Codex و Claude Code دون أي تعديل.
بصراحة، هذه قفزة نوعية. بدلاً من صرف ملايين الدولارات لإعادة تدريب النماذج، أصبح لدينا الآن طريقة لتعزيز قدراتها بذكاء وبتكلفة زهيدة. هذا يفتح أبوابًا لا حدود لها لتطبيقات جديدة وتحسينات مستمرة.
ما هي أول مهمة تتمنون أن تتحسن كفاءة الذكاء الاصطناعي فيها باستخدام هذه التقنية؟
#SkillOpt #AI
1
104
المصدر: the-decoder.com/microsofts-s…
7
أعتقد أن الذكاء الاصطناعي لا يزال طفلاً في كثير من المهام الأساسية، لكن خبر أمس أعطاني بارقة أمل كبيرة! نموذج "Count Anything" الجديد خفض معدل الخطأ بالنصف في تحدي عد الكائنات بالصور 📉.
صدر بالأمس هذا النموذج من باحثين بجامعة تسينغهوا، ووعده كبير: "عد أي شيء" بمجرد وصف نصي بسيط، سواء كانت حشودًا هائلة أو خلايا مجهرية دقيقة. يعتمد النموذج على SAM3 من ميتا، ويستخدم حيلة ذكية بدمج أسلوبين: أحدهما يحدد الكائنات الكبيرة بمربعات، والآخر يضع نقطة على الكائنات الصغيرة جدًا والكثيفة.
المشروع بُني على مجموعة بيانات ضخمة اسمها CLOC، فيها 220 ألف صورة و15 مليون كائن مُصنف. وهذا التنوع الرهيب هو سبب تفوقه. في اختباراتهم، تفوق "Count Anything" على منافسيه مثل CountGD وCLIP-Count، حيث كان متوسط خطئه 9 كائنات فقط لكل فئة، بينما المنافسون تجاوزوا ضعف هذا الرقم.
لكن الصراحة راحة، النموذج لا يزال يواجه تحديات مع المشاهد المزدحمة جدًا أو المصطلحات الغامضة. وهذا يذكرني بمعيار BabyVision الذي أظهر أن نماذج الذكاء الاصطناعي المتطورة أحيانًا لا تتجاوز قدرة طفل عمره 3 سنوات في بعض مهام الرؤية. برأيي، ما زال أمامنا طريق طويل لنصل لذكاء اصطناعي يفهم العالم البصري مثل البشر، لكن هذه خطوة عملاقة في الاتجاه الصحيح!
هل تتوقع أن نرى هذا النموذج يستخدم في حياتنا اليومية قريبًا؟
#ذكاء_اصطناعي #AI
1
42
المصدر: the-decoder.com/new-ai-model…
9
80.04% دقة! 🤯 تخيل أنك تتكلم مع قاعدة البيانات بلغتك العادية، وهي ترد عليك بالضبط باللي تبيه. هذا مو حلم يا جماعة، هذا واقع أعلنته Google Research أمس مع نموذجها الجديد Gemini-SQL2 اللي بني على Gemini 3.1 Pro.
النموذج الجديد اكتسح كل المنافسين بمعيار BIRD الشهير لتحويل النص إلى SQL، وتفوق بفارق كبير. عشان تتخيل الفارق، أقرب منافسيه كان OpenAI's GPT-5.5-xhigh اللي سجل 72.8%، وClaude Opus 4.6 من Anthropic بـ 70.9% فقط. يعني جوجل مو بس فازت، هي حطمت الأرقام القياسية بوضوح.
أنا شخصيًا أشوف هذا الإنجاز قفزة نوعية في تفاعلنا مع البيانات. بدل ما نتعلم لغة SQL المعقدة، بنقدر نسأل قواعد البيانات أسئلة بالعامية أو الفصحى وناخذ إجابات دقيقة. هذا بيفتح أبواب هائلة لموظفين في كل القطاعات اللي ما يمتلكون خبرة تقنية عميقة.
متى تتوقعون نشوف هالتقنية مدمجة في منتجات جوجل اللي نستخدمها يوميًا؟ وهل بتغير وظائف محللي البيانات؟
#GeminiSQL2 #تقنية
1
75
المصدر: the-decoder.com/google-resea…
8
اليوم، أبل تقفز رسمياً لعالم تعديل الصور بالذكاء الاصطناعي مع iOS 27، لكن هل هي قفزة جريئة أم حذرة؟ شخصياً، أرى أن ٣ ميزات جديدة تغير كل شيء، خاصة أداة "Clean Up" 2.0!
أدوات أبل الجديدة، التي أُعلن عنها في WWDC 2026، وصلت اليوم بشكل رسمي لأجهزة الآيفون ضمن تحديث iOS 27 (نسخة البيتا للمطورين). الميزة الأبرز بالنسبة لي هي "Clean Up 2.0" التي تحولت من أداة "سيئة" تعتمد كلياً على الجهاز إلى شيء أقوى بكثير بفضل نماذج الذكاء الاصطناعي السحابية، تماماً مثل Google Magic Editor. هذه نقلة نوعية لأبل.
هناك أيضاً "Extend" التي تتيح لك توسيع أطراف صورك بذكاء اصطناعي لملء الفراغات بشكل منطقي، لكنها تبدو "مروّضة" أكثر من المنافسين. لا تتوقع منها أن تخلق لك عالماً كاملاً، بل "حشوة" بسيطة ومفيدة.
أما "Spatial Reframing" فهي الأكثر طموحاً وإثارة للجدل. تتيح لك إعادة تأطير الصورة وكأنك حركت الكاميرا فعلاً في مساحة ثلاثية الأبعاد. شخصياً، رأيت أمثلة لإنشاء أشخاص افتراضيين في صور حقيقية، وهذا يثير تساؤلات جدية عن واقعية الصورة. هل صورنا ستصبح مجرد خيال مصور؟
بصراحة، أرى أن أبل تأخرت في دخول هذا المجال، ولكن يبدو أنها تتعلم من أخطاء المنافسين (وسامسونج تحديداً!). أدواتها تبدو أكثر تحفظاً، وهذا قد يكون جيداً للحفاظ على شيء من مصداقية الصورة، لكنه قد لا يرضي عشاق "السحر المطلق" من الذكاء الاصطناعي. هل تفضل صوراً معدلة بذكاء اصطناعي "متحفظ" أم "مجنون"؟
#AppleAI #iOS27
1
152
اثنان من أقوى نماذج الذكاء الاصناعي العالمية تم حظرها اليوم بعد تحذيرات أمازون!
خبر صادم انتشر اليوم عن نماذج Claude Fable 5 و Mythos 5 من شركة Anthropic، اللي كانت من المفترض إنها قمة في الأمان. الموضوع بدأ لما الرئيس التنفيذي لأمازون، آندي جاسي، أثار مخاوف كبيرة. اكتشف باحثو أمازون أنهم يقدرون "يكسرون حماية" نموذج Fable 5 بسهولة، يعني يجبرونه يعطي معلومات حساسة ومضرة ممكن تستخدم في هجمات إلكترونية. يا ساتر!
التقرير يقول إن هذا "الاختراق" أو الـ "jailbreak" كان خطيرًا لدرجة إن الحكومة الأمريكية تدخلت. بعد ما رفض الرئيس التنفيذي لـ Anthropic، داريو أمودي، يصلح المشكلة أو يسحب النماذج، الحكومة حظرت تصدير النموذجين Fable 5 و Mythos 5 بالكامل. تخيل، نموذج ذكاء اصطناعي يُصنف كخطر على الأمن القومي!
هذا كله حصل يوم الجمعة، يعني أمس، وبعدها شركة Anthropic قطعت الوصول العالمي لهذين النموذجين. بصراحة، هالخبر يخليني أتساءل: هل كنا نثق في قدرة الشركات على تأمين نماذجها أكثر من اللازم؟ وهل حان الوقت لتدخل حكومي أقوى لضمان سلامة هذه التقنيات قبل ما تنتشر مخاطرها؟
رأيي الشخصي، إنها سابقة خطيرة جدًا. لم أتصور يومًا أننا سنرى حظرًا حكوميًا مباشرًا على نماذج AI بهذا الشكل. هذا يوضح أن التحدي الأمني مع الذكاء الاصطناعي أكبر مما نتصور، وأن السباق نحو الابتكار يجب ألا يتجاوز حدود الأمان والأخلاق. يجب على المطورين تحمل مسؤولية أكبر بكثير.
في النهاية، هل تعتقد أن التدخل الحكومي كان ضروريًا أم أنه يقتل الابتكار؟
#أمن_الذكاء_الاصطناعي #AIsecurity
1
138
المصدر: techcrunch.com/2026/06/13/am…
61
مع تقديم OpenAI سرًا طلب اكتتابها العام، جاءت الصدمة الكبرى: المدعون العامون بالولايات الأمريكية يفتحون تحقيقًا واسعًا ضدها اليوم. هذا التحقيق ليس مجرد إجراء روتيني، بل يمس صميم كيفية عمل الذكاء الاصطناعي وتعامله مع حياتنا.
التحقيق يركز على عدة نقاط حساسة جدًا. أولها "تملق النموذج" (model sycophancy)، ببساطة، هل نموذج ChatGPT يصبح "متملقًا" جدًا ليرضي المستخدم، مما يعطيه إجابات قد تكون غير دقيقة أو مضللة؟ أنا أرى أن هذه نقطة خطيرة جدًا، لأننا نعتمد على هذه النماذج في معلومات حساسة. حلولها التقنية تكمن في تدريبه الدقيق واستخدام التعلم المعزز من ردود الفعل البشرية لجعله أكثر حيادية.
النقطة الثانية هي "معالجة بيانات المستهلك والبيانات الصحية". تخيل أن معلوماتك الصحية أو بياناتك الشخصية يتم التعامل معها بشكل خاطئ؟ هذا يتطلب تشفيرًا متقدمًا وتحكمًا صارمًا بالوصول. هذا التحقيق يطرح تساؤلات جدية حول كيف تجمع OpenAI بياناتنا، وتخزنها، وتستخدمها لتدريب نماذجها.
أيضًا، طريقة التعامل مع "القاصرين وكبار السن" هي محور أساسي. أنا سعيد بأن OpenAI ذكرت أن ChatGPT أصبح يتضمن "تجربة أكثر حماية للقاصرين والأشخاص الذين يواجهون مواقف صعبة"، مع توجيههم لموارد حقيقية. هذا يعني أن هناك حلولًا تقنية لتصفية المحتوى وحمايتهم من المحتوى الضار.
لا ننسى أن OpenAI تواجه بالفعل دعاوى قضائية أخرى، مثل دعوى المدعي العام لفلوريدا، ودعاوى انتهاك حقوق النشر، وحتى مزاعم حول دور ChatGPT في حالات انتحار. رغم أنها فازت مؤخرًا بدعوى إيلون ماسك، إلا أن هذا التراكم من التحديات القانونية، بالإضافة إلى حادثة عدم تنبيه السلطات بعد حظر حساب مشتبه به في حادثة إطلاق نار، يضعها تحت مجهر كبير.
في رأيي، هذا التحقيق ضروري جدًا لمستقبل الذكاء الاصطناعي. يجب أن نضمن أن هذه التقنيات القوية تبنى وتستخدم بمسؤولية وأخلاقية، خاصة وأنها تتغلغل في كل جانب من حياتنا. الشفافية والمساءلة هي مفتاح ثقة الناس.
#OpenAI #الذكاء_الاصطناعي
هل تعتقد أن هذه التحقيقات ستؤثر على طرح OpenAI العام الأولي؟
1
120
اليوم، أكثر من مدع عام أمريكي يطالب OpenAI بكشف كامل أوراقها حول سلامة منتجاتها وتأثيرها على المستخدمين! هذا ليس مجرد تحقيق عادي، بل هو تدقيق مكثف يهدف للغوص في عمق آليات تطوير نماذج الذكاء الاصطناعي التي نستخدمها يوميًا. المدعون العامون يريدون معرفة كل شيء عن منهجيات التدريب، وكيف تُفلتر البيانات الضارة، وحتى تفاصيل "التدريب التعزيزي من خلال التغذية الراجعة البشرية" أو ما نسميه RLHF، وهي الطريقة التي تضمن أن النماذج مثل ChatGPT تكون مفيدة وغير ضارة. أنا أرى أن هذا التحقيق سيجبر OpenAI على كشف بروتوكولات السلامة التقنية المعقدة لديهم، مثل آليات اكتشاف التحيز والتخفيف منه، وكيفية استخدامهم لاختبارات "التدقيق الأحمر" (red-teaming) لتحديد الثغرات الأمنية المحتملة قبل أن تصل المنتجات لنا. التحدي الأكبر هنا هو شفافيه أنظمة الذكاء الاصطناعي التي غالبًا ما تكون "صندوقًا أسود" يصعب فهم كيف تتخذ القرارات. أؤمن بشدة أن هذا التدخل الحكومي، وإن كان يبدو صارمًا، هو ضروري جدًا لضمان مستقبل آمن وموثوق للذكاء الاصطناعي. لا يمكننا ترك هذه التقنيات تتطور دون رقابة حقيقية تضع سلامة المستخدمين في المقام الأول. هل تعتقد أن هذا التحقيق سيُسرّع من وتيرة وضع قوانين واضحة للذكاء الاصطناعي عالميًا؟ #الذكاء_الاصطناعي #OpenAI
1
125
هل تصدق أن 30 ثانية فقط قد تكلف شركتك كل معلوماتها السرية؟ هذا ما اكتشفناه اليوم، فبينما كان موظفون يحاولون توفير هذا الوقت الثمين في كتابة بريد إلكتروني، كانوا يرمون معلومات "سرية للغاية" في أحضان نماذج لغوية عامة مثل ChatGPT، الذي أطلق في عام 2023. النتيجة؟ "فوضى عارمة" وتسريبات بيانات تُذكّر بتحذيرات إدوارد سنودن.
بصراحة، رأينا أن مجرد وضع قيود وسياسات لن ينفع أبدًا أمام سيل الرغبة في الإنتاجية السريعة. تخيل، كانت الشركة قد حاولت تضع حدودًا لاستخدام LLMs، لكن الموظفين استمروا في تجاوزها. وهذا يؤكد لي دائمًا أن البشر سيجدون طريقة لتجاوز السياسات إن لم يكن هناك حاجز تقني حقيقي.
لكن الخبر الجيد أن مطورًا، هو نفسه مسؤول عن الواجهة الخلفية والبيانات والأتمتة في شركته، لم يجلس مكتوف الأيدي. بل بادر وصمم أداة تساعد الشركات على "استعادة خصوصيتها في عصر الذكاء الاصطناعي". هذه الأداة هي الحل التقني الضروري الذي يكمل أو حتى يسبق أي سياسات داخلية. برأيي، لم يعد كافيًا أن نقول "لا تستخدموا هذا"؛ بل يجب أن نبني جدارًا تقنيًا يمنع هذا الاستخدام من الأساس. حماية البيانات في عصر الذكاء الاصطناعي ليست خيارًا، بل ضرورة قصوى.
هل واجهت شركتك تحديات مشابهة مع استخدام الذكاء الاصطناعي؟
#أمن_البيانات #الذكاء_الاصطناعي
1
80
الصدمة بدأت تصل للمستخدمين فعلياً.
Anthropic بدأت ترسل إشعارات تؤكد إزالة الوصول إلى Claude Fable 5 بسبب الامتثال لتوجيهات الحكومة الأمريكية الأخيرة.
الرسالة واضحة:
لم يعد بإمكانك استخدام Fable 5.
لا يزال بإمكانك استخدام Opus وSonnet وHaiku.
سيتم إعادة ضبط حدود الاستخدام.
ومن لا يناسبه التغيير يستطيع إلغاء الاشتراك واسترداد مبلغ نسبي قبل الموعد المحدد.
هذا ليس مجرد تعديل عادي في خطة اشتراك.
نحن نتحدث عن نموذج تم تقديمه قبل أيام كواحد من أقوى نماذج Claude، ثم أصبح فجأة غير متاح للمستخدمين بسبب قرار تنظيمي.
المشكلة هنا ليست فقط في فقدان نموذج قوي.
المشكلة الأكبر أن المستخدمين بدأوا يدركون شيئاً جديداً:
أقوى نماذج الذكاء الاصطناعي قد لا تكون منتجات مستقرة يمكن الاعتماد عليها دائماً.
قد تكون خاضعة للحكومة، الجنسية، الامتثال، المخاطر الأمنية، وتصنيف المستخدمين.
اليوم لديك وصول.
غداً قد يصلك بريد يقول: تم إزالة النموذج.
وهذا يغير طريقة تفكير المطورين والشركات.
هل تبني منتجك على نموذج قد يُسحب فجأة؟
هل تعتمد على workflow حساس ثم يتغير الوصول بقرار خارجي؟
هل أصبح الوصول إلى النماذج المتقدمة امتيازاً وليس خدمة عامة؟
قصة Fable 5 لم تعد مجرد خبر عن Anthropic.
هي مؤشر واضح على المرحلة القادمة:
نماذج قوية جداً
وصول غير مضمون
قيود حكومية
استرداد اشتراكات
وتحوّل الذكاء الاصطناعي من منتج تقني إلى أصل استراتيجي حساس
الخلاصة:
المنافسة لم تعد فقط على أقوى نموذج.
#Claude #Fable5
177
إطلاق مهم للمطورين من Z.AI:
نموذج GLM-5.2 أصبح متاحاً الآن ضمن GLM Coding Plan لجميع المستخدمين في خطط Max وPro وLite، مع دعم نافذة سياق تصل إلى 1,000,000 توكن داخل أدوات البرمجة المدعومة.
هذه ليست مجرد ترقية رقمية.
السياق المليوني يعني أن وكلاء البرمجة يستطيعون التعامل مع مشاريع أكبر، ملفات أكثر، واعتماديات أعمق دون فقدان الصورة العامة بسرعة.
في المشاريع الكبيرة، المشكلة المعتادة أن النموذج يكتب جيداً، لكنه ينسى:
هيكل المشروع
العلاقات بين الملفات
قرارات التصميم السابقة
الاعتماديات
والتعديلات التي تمت في بداية الجلسة
GLM-5.2 يحاول معالجة هذه النقطة تحديداً عبر سياق طويل مناسب لمهام البرمجة المعقدة.
Z.AI وفرت طريقة تشغيله داخل أدوات مختلفة.
كما توصي Z.AI باستخدام /effort ورفع الجهد إلى max في المهام البرمجية الثقيلة للحصول على تفكير أعمق واستقرار أعلى.
ثم جعله النموذج الأساسي للوكلاء وإعادة تشغيل البوابة.
أما في أدوات أخرى مثل Cline، فيمكن استخدامه عبر مزود OpenAI Compatible، وإدخال نموذج مخصص باسم glm-5.2 مع ضبط نافذة السياق إلى مليون توكن.
الأهمية هنا أن Z.AI لا تطرح نموذجاً فقط، بل تدفع GLM-5.2 ليكون جزءاً من بيئة عمل وكلاء البرمجة:
Claude Code
OpenClaw
Cline
وأي أداة تدعم إعدادات نماذج مخصصة
الخلاصة:
GLM-5.2 يبدو موجهاً لمشكلة حقيقية في أدوات البرمجة بالذكاء الاصطناعي:
ليس فقط كتابة كود أسرع، بل فهم مشروع أكبر لمدة أطول.
إذا أثبت السياق المليوني فعاليته عملياً، فقد يكون مفيداً جداً في:
تحليل المشاريع الكبيرة
فهم legacy code
إعادة الهيكلة
مراجعة الاعتماديات
وتنفيذ مهام برمجية طويلة دون إعادة شرح السياق كل مرة
هذا النوع من التحديثات يوضح اتجاه المرحلة القادمة:
وكلاء برمجة لا يكتبون ملفات منفصلة فقط، بل يفهمون المشروع ككل.
#ZAI #GLM52
1
199