
A story teller who weaves tales through numbers and a demographic scientist who has indigenously built many data-tech platforms
Joined July 2012
- Tweets 15,161
- Following 77
- Followers 71,177
- Likes 739
537 Photos and videos

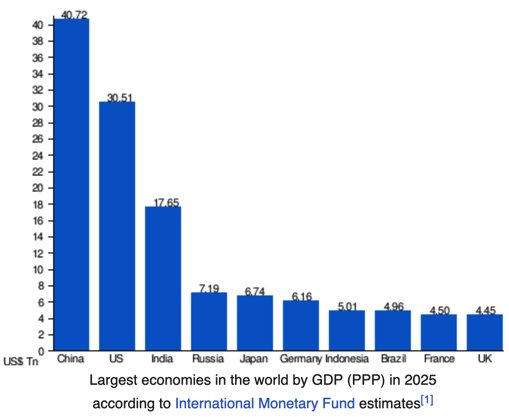

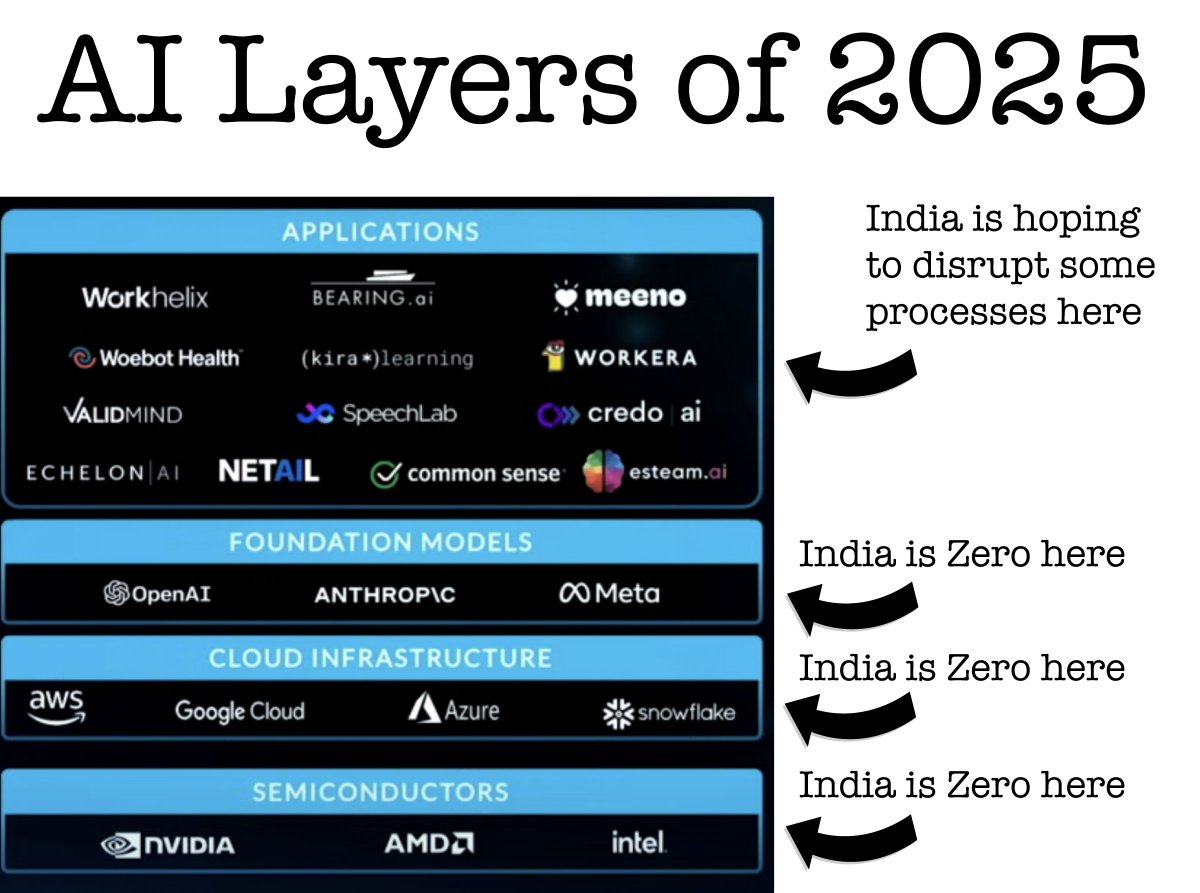







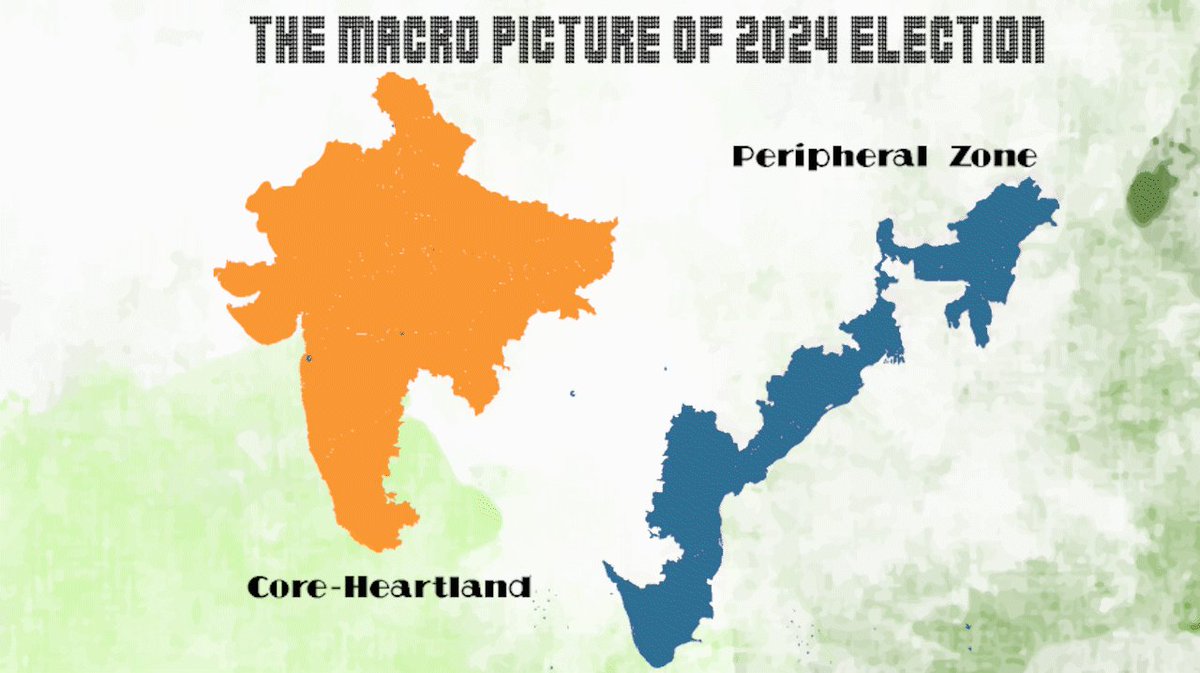




Jun 7
Funny to hear about GenZ being "angry" online.
Meanwhile IRL, have never seen a younger generation more nationalist, more inward looking towards Sanatan values, more reverential towards their Prime Minister.
One just has to get out of their X/Insta echo chambers!
3
16
60
2,050
May 28
Siddaramaiah is literally the last mass leader that Congress has and he was sacrificed today.
12
26
197
12,054
Dr Praveen Patil retweeted

May 21
भारत Food-Surplus Nation होने के साथ-साथ वैश्विक Food Security में भी महत्वपूर्ण योगदान दे रहा है। हमारे लिए Food Security केवल एक Policy Matter नहीं, बल्कि यह मानवता के प्रति हमारी जिम्मेदारी भी है।
2,380
6,699
33,128
7,241,361
Dr Praveen Patil retweeted

May 12
Alexander , Ghori , Ghazni , Khilji , British , French , Communists couldn’t do it …… & here comes a person who cannot convince his own family about this …!! Bharat & Sanatan have withstood the test of time & generations .
May 12

VIDEO | Chennai, Tamil Nadu: "Sanathanam that divides people should be abolished," says LoP Udhayanidhi Stalin.
Source: Third Party
(Full video available on PTI Videos - ptivideos.com)
213
2,836
8,011
135,554
May 10
This has been a red flag for a long time. BJP-RSS Leadership is aware of this for many years now but surprisingly not proactive.
Google and Meta platforms literally decide Indian elections in 75% of the political geography of India.

Meta platforms are making or breaking elections in India. FB, Insta, and Whatsapp can now win elections for some, and make some lose. That's their power. 2024 lower than expected seats for NDA & 2026 performance by TVK, both were a result of Meta's algorithms. And Meta is...
5
180
801
19,405

Meta platforms are making or breaking elections in India. FB, Insta, and Whatsapp can now win elections for some, and make some lose. That's their power. 2024 lower than expected seats for NDA & 2026 performance by TVK, both were a result of Meta's algorithms. And Meta is...
326
2,191
13,244
1,112,473
May 4
Turnsout Dravidian politics survived all these decades in Tamil Nadu just because of one man's political cowardice, nothing ideological, nothing subnationalist about it.
This is on you Rajnikant!
39
275
1,909
69,419
May 4
200 in Bengal and 100 in Assam!
Even a decade ago, that was purely a fantasy. The extent to which "political secularism" has been crushed by Indian voters is something no one could have predicted
4
143
514
9,651
May 4
BJP is now the strongest in its history, even surpassing the 2019-20 period when it had 300 MPs.
Hindsight shows us that not performing well in 2024 actually helped BJP to reimagine its electoral machinery. Since then BJP has defeated,
AAP in Delhi
Indi Alliance in Maharashtra,
An ascendent Congress in Haryana,
A rising RJD in Bihar
And now TMC in Bengal.
These are new electoral gains which weren't true either after 2014 or 2019 cycles. The opposition to BJP is now the weakest it has ever been!
25
700
4,160
126,169
Dr Praveen Patil retweeted

Apr 29
Vivek Wadhwa who is CEO of Vionix Biosciences and has held academic appointments at institutions, including Harvard Law School, Stanford and Duke University says in his article - “The new reality is that India is not waiting to be built by its diaspora, it is building itself”
It is the kind of interdisciplinary, systems-level work that requires not just expertise, but the ability to think across boundaries and challenge established approaches.…..
……When I began scaling this effort in the United States, I encountered a reality that surprised me: I could not find the depth of interdisciplinary talent I needed at the scale required. The expertise existed, but it was fragmented, expensive, and often siloed.
….In India, I found engineers who move fluidly across domains, physicists who collaborate naturally with clinicians, and teams unburdened by rigid hierarchies or narrow specialization, along with a deeper hunger—a willingness to take on problems others consider too complex or too risky.
Read More:
moneycontrol.com/news/opinio…
3
42
119
54,530
Dr Praveen Patil retweeted

Apr 27
Open letter to Indians in America.
--
Dear brothers and sisters from Bharat:
Like I did 37 years ago, you arrived in America with no money but with a good education and cultural heritage from Bharat. You achieved outstanding success. America was good to us. For that we must remain grateful - gratitude is our Bharatiya way.
Yet today, a significant number of Americans, may be not the majority but not too far from it either, believe that Indians "take away" American jobs and our success in America was unfairly earned.
You may think the next election will fix this, but your choice would be between people who hate our Bharatiya civilisation and people who hate civilisation itself. That is the "hard right" vs "woke left" battle. You are mere bystanders to that conflict.
Meanwhile there is one thing that is true now and will be true in the future: the respect Indians command world-wide will substantially depend on the fortunes of India herself. If India remains poor, the woke left will give us moral lectures with pity and the hard right, different moral lectures with scorn ("hellhole") and we must not confuse either with respect.
Respect in today's world, along with prosperity and security, comes from one source: a nation's technological prowess. India produces sufficient brain power to achieve that prowess but alas we exported so much of that talent, particularly to America. As we develop that prowess in India, our civilisational strength will assert itself.
As difficult as it is for many of you to contemplate this, please come back home. Bharat Mata needs your talent. Our vast youthful population needs the technology leadership you gained over the years to guide them towards prosperity. Let's do it with a missionary zeal.
Respectfully
Sridhar Vembu
3,958
6,855
27,416
6,965,206
Apr 18
Welcome to 2026 where everyone including Presidents, foreign ministers and field marshals of warring and negotiating countries gamble in the Options markets!
Why? Because these Options markets are bigger than their combined National GDPs.
3
14
54
7,261
Mar 22
Hausla-Eendhan-Badla!
Hausla = Ordinary Hindu Nationalists who never lost faith
Eendhan = The RSS' ability to keep building grassroots strength
Badla = Decolonisation of the Indian mind through Congress-mukt-Bharat
That is how @narendramodi completes 8931 days in power!
12
167
585
17,076
Feb 20
Two hidden trends that matter in the Ai world right now;
Continual Learning
and
World Models
This is what India has to focus on. The fact is that GPTs and their products, the LLMs and their core architectural constraints, the Transformers are all at a dead end.
The LLM world doesn't know how to impact the real economy or productivity on this path. They are throwing the sink at it and hoping some magic will come out of it just by deploying the sheer compute at scale that costs billions and trillions of dollars (this was the classic mistake of early dotcom era bust too). Yet they are nowhere near solving the 2 basic problems of "bad generalisations" and even worse "sample efficiency". In fact, if anything they may hit mathematical limitations of RL soon.
India needs to bet on an alternate path, an alternate destiny for mankind. Fund a new architecture. Liberate intelligence from the abstract layer of Human language constraints and focus on narrow intelligence dominance in specific domains with continual learning. No preformed biases, no pre-trained models, no frozen training weights. This is a revolution that can differentiate Bharat from US and China, it can give us that edge that nobody currently has, in less than 2 years!
But current data-centre deployment in India is minuscule compared to the world at around 1.5GW (US has 54GW and China 32GW). If India can strategically plan to deploy the next 2-5GW of hyperscale datacenter for CL and world models with more efficiency rather than just throwing all the labelled datasets at it and instead deriving intelligence beyond mere human language understanding, then there is a potential path to achieve massive intelligence gains in specific domains at a fraction of the cost and compute.
Interestingly, this aligns with our ancient wisdom of the Sindhu-Saraswati civilisation. Most of us think of Sanskrit as a language born to communicate ideas amongst us humans (like all other languages), but what if you think of Sanskrit as a layer of intelligence beyond the mundane human existence? in fact, it was probably a layer specifically designed to capture intelligence from a higher level. Vedas were then downstream to that intelligence capture and so very complex in nature that most parts have either been lost or remain only partially deciphered till date.
Can Bharat achieve such a paradigm today? Let the world focus all their energies on the current backprop-Transformer-GPT-RL-LLM models and throw the sink of data and compute to arrive at a magical intelligence layer, maybe they will achieve success. But if they won’t (which is more likely), we will be in a commanding position to walk on an alternate path in 2 years. As a nation we need to institutionally and strategically focus on deploying compute at scale towards CL and world models to achieve narrow AGI in specific domains. Can we, for once, find the courage to do something different and lead the world rather than be led?
3
21
36
7,301
Dr Praveen Patil retweeted

Jan 26
You will not find better analysis than this of Sunny paji & how #Bollywood has not used his Stardom .
A must read for #SunnyDeol fans & Bollywood lovers .

5
66
261
38,148
Jan 26
Our collective civilizational memory understands how a society goes into chaos without a patriarch to guide and patriotism to unite. Liberalism is a disease that spreads in a society without moral ethos or love for motherland. The goal of liberalism is to de-anchor you and to create rootless individuals
1
23
76
6,236
Jan 25
As an analyst of mass behavioral patterns, the Sunny Deol phenomenon has always been a mystery to me.
He is arguably the greatest mass star ever, probably bigger than Amitabh Bachchan himself! But we know nothing about it because nothing has ever been analysed. No "Angry Young Man" hypothesis, no impact on societal state analysed, no pop social psychology. Nothing.
He gave some of the biggest blockbusters of 90s, but all literature is about Khans. He gave Gadar, the greatest movie in mass memory since Sholay, but we have not even a paper written about why India reacted the way it did to partition wounds after 50 years.
Today he is once again delivering one of the greatest blockbusters on India-Pak war when he is nearly 70 and we will see zero sociological analysis of this too.
in a way I understand this. A society willingly shuts up certain stories even if they are staring them in the face just to keep the narratives intact. The story of the rise of Khans in the 90s is selected, Sunny Deol's patriotic movies are discarded. And we will always be unaware of why Sunny had such a massive appeal.
92
294
1,435
95,696
Jan 4
Energy = compute = intelligence. This is the new reality. US, the hegemon has now secured Venezuela and working towards securing Iran.
What will India do when we realise that our labour arbitrage is gone in just a few years and we neither have the compute nor the energy to compete? The only window we have is probably a year when we have to simply go 💯 nuclear without caring about anybody in the world and build nationwide compute to pair with it. Build an intelligence layer so big that the labour arbitrage becomes irrelevant anyways.
Will India do this? Highly unlikely. A nation run on bureaucracy will never understand the coming revolution of 4th turning until it's too late.
2
24
57
6,829
14 Nov 2025
The way BJP has regrouped and covered the gaps after 2024 underperformance is a legend that will be taught in history books. The sheer organisational strength required for this feat is hugely under appreciated.
This is also Hindu renaissance at its best in a millennium. We may have finally overcome our biggest weakness of becoming fragile at the smallest of setbacks. The way RSS has matured to find opportunities in defeats and setbacks is the greatest redeeming story of our times. The 2004 to 2014 decade of darkness has made us infinitely stronger!
19
247
1,132
34,214