
KASPlex | KRC-20 | HODL
Joined July 2022
- Tweets 185
- Following 85
- Followers 1,483
- Likes 488
9 Photos and videos
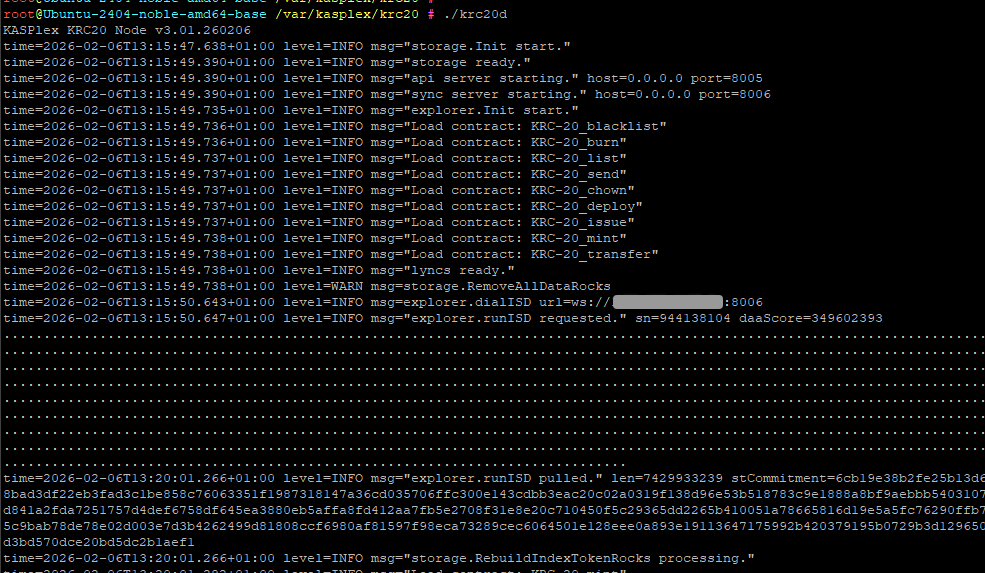







github.com/5bb55b/go-kaspabo…
go-kaspabook is a lightweight indexed kaspa REST-API system suitable for integration with dApps/CEXs/organizations (but not suitable as a data source for browsers).
It is an early version, just about 10 days of work. I need a few more days to test it, then I will use it in several projects and observe how it performs.
The API doc is currently generated by AI, I will optimize it later.
Key features:
Data fetching via Kaspad vspc2 (only focuses on the chain-blocks and the accepted-txns data.);
Using the local RocksDB with support for daascore-to-live pruning;
Using protobuf data format to save disk space;
An aggressive data item storage strategy (more index-params will be added later to support additional data);
Reorg processing mechanism for index-keys.
book-API:
GET - /book/status
GET - /book/vspcs/daascore/:score[?count=10&prev=1]
GET - /book/vspcs/bluescore/:score[?count=10&prev=1]
GET - /book/blocks/:hash
GET - /book/transactions/:txId
GET - /book/addresses/:address/transactions[?daascore|bluescore=12345&count=10&prev=1]
kaspad-API:
GET - /kaspad/addresses/:address/balance
GET - /kaspad/addresses/:address/utxos
POST - /kaspad/transactions
POST - /kaspad/transactions/rbf
2
15
55
1,298

🚀 KRC-20 Mainnet Launch Announcement 🎉
We are thrilled to announce that Kasplex KRC-20 will be launching on the MAINNET on the 15th of this month at 12:00 PM UTC! 🌐
After over a month of internal testing and two months of stress testing, we've processed over 90M KRC-20 transactions, and everything is running smoothly.
We're also seeing a growing community of developers building amazing applications on Kasplex. You can now complete KRC-20 transactions through various wallets, and integrating KRC-20 into your own applications has become even easier.
Thank you for being part of this journey. Let's build, innovate, and grow together!
@KaspaCurrency @Kaspa_KEF

249
780
2,135
280,328
5bb55b retweeted

28 Aug 2024
The Release Candidate with RBF, Dynamic Fees, Optimized mempool and much more is here!
github.com/kaspanet/rusty-ka…
Wallets can now respond to dynamic and evolving fee markets with the new RBF and FeeEstimate APIs empowering end user to control their transaction inclusion speed. If you are a wallet developer, please be aware of these changes and integrate them into your wallet.
#RustyKaspa #10bps #KRC20

26
201
730
94,882
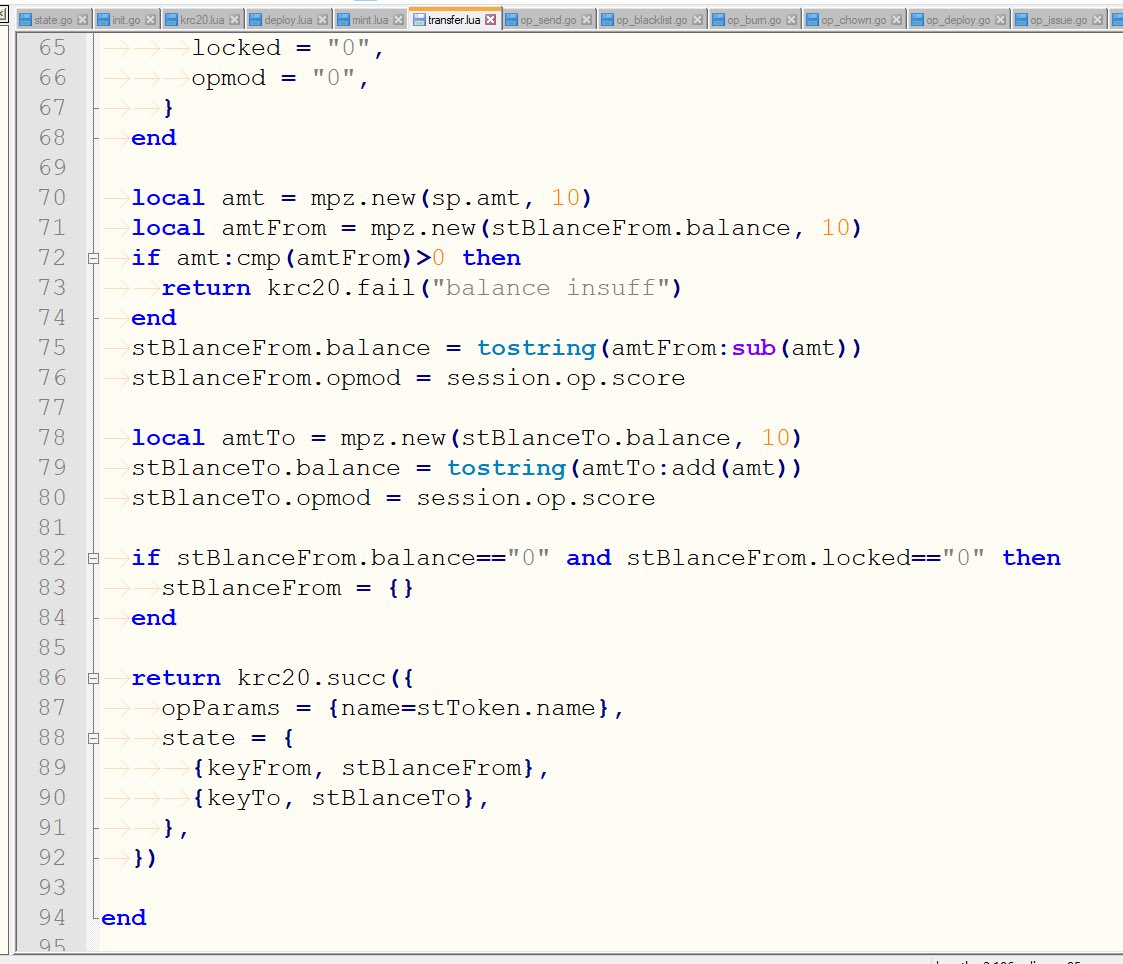
In the past 50 days, we have completed many important improvements, and the Kasplex indexer will soon be open source. Before that, I would like to briefly share the technical points of the new system architecture, and btw, let my tense nerves relax a little😆.
Splitting of indexers (modularization).
The initial version had a single system responsible for all tasks, which obviously increased the complexity of the code and the difficulty of debugging/testing. In the new architecture, the system is split into multiple independent components: Node-Syncer, OP-Executor, OP-Stats/API.
Node-Syncer.
The Syncer communicates with the node in real-time, archives the original data to the NoSQL cluster and handles block-reorg events. The data is include three parts: block data, transaction data, and sorted data (VSPC).
OP-Executor.
The Executor scans the VSPC sorting table in the archive-db in real time, retrieves and processes transaction data that complies with the protocol spec, and updates both the local db and the cluster db for the state data generated after executing each OP. In addition, due to the existence of block reorg-events, a real-time state rollback mechanism is necessary.
OP-Stats/API.
We need to provide a public api service that includes real-time query of state data (such as asset balance) and query of statistics or historical OPs. Considering the efficiency of OP execution, the latter should be separated from the core execution logic. OP-Stats scans the OP list, generates the indexes required for each query, and completes several statistics at the same time. When querying state data, the API gateway directly uses the real-time data provided by the executor, and uses the data generated by the OP-Stats in other cases.
Database.
The consideration for this part is that RocksDB provides high-speed read/write and transaction capabilities of local disks; at the same time, it writes to the Cassandra cluster to allow a distributed system with high throughput. Although the latter reduces the performance of the OP-Executor, it is not necessary for future Light-Indexers.
Necessity of archive db.
The current indexer system does not have a distributed P2P sync mechanism. The executor needs to build complete state data from the initial OP. It will become increasingly difficult for the archive node to provide a large amount of historical data (transaction and sorting data) while maintaining operation (especially at 10BPS). Another reason is that the indexer needs to calculate the transaction fee by querying the spent-TXO. In the initial version, we solved this by caching UTXO in advance, but it was not reliable enough.
Performance optimization measures.
In the new architecture, we replaced the db with NoSQL, and used multi-threaded concurrency and batch operations as much as possible in terms of reading/writing. The batch state pre-reading mechanism is implemented in the OP executor to greatly reduce the db reading/writing. For block reorg-events, a state set list will be maintained to implement batch rollback processing. In addition, we can also configure aggressive/conservative policies for real-time scanning. The former keeps the latest block sync as much as possible, but there will be more block-reorg and state rollbacks, and the latter allows a lag of 2-3 blocks to avoid most rollbacks.
OP checkpoints and trust model.
As the basis for implementing the data trust model in the future, each successfully executed OP will generate a checkpoint, which includes the OP header, state changed, and the previous checkpoint. We will deploy multiple independent and complete indexer systems with multiple partners (project parties, ecosystem builders, or individuals) to discover possible problems (system bugs or malicious attackers) through OP checkpoints.
TODO, Archive-API and OP-Syncer initialization.
A newly deployed indexer system needs to at least initialize the OP-Syncer, which includes reading the historical data (starting from a certain chain block). We will provide this part of the data in the public api service, then the Syncer will auto complete it.
R&D, Light-Indexer.
For the future high-throughput big data scenarios of 10BPS or 3000TPS, we need to complete the Light-Indexer. Ideally, it only needs to connect to a regular node (non-archival node) and maintain only a necessary global state db, verify and correct errors with other indexers through the P2P mechanism. Several problems need to be solved here. The first is the data trust model, how to verify the authenticity of data, trace and repair; how to quickly calculate the transaction fee without relying on the archive db; how to directly sync the state data when the node lacks historical data (is pruned), etc.
R&D, Decentralization and Layer-2 construction.
How to decentralize means that there are more things to consider. We see that KASPA will implement off-chain data verification through native support for ZK opcodes, which I think will be the basis for all second layers. In addition, as a Kasplex protocol, how to support general computing layers (such as smart contracts), which consensus mechanisms can be implemented, or what incentives can be used to encourage more people (or institutions) to run, these are all still under consideration.
26
101
318
57,286
5bb55b retweeted

19 Aug 2024
Revealing Kaspa's 10BPS hardfork roadmap — the “Crescendo” Hard-Fork 👇
medium.com/@michaelsuttonil/…

47
256
824
121,258
5bb55b retweeted

11 Jul 2024
Had a nice morning meeting with the @kasplex team where they updated me on their progress on several fronts and we had some back-and-forth. $kas
On the agenda was:
1. Some changes to the KRC protocol (proposed by myself and others) that should streamline the process, make for an easier developer and user experience, and eliminate all the mass issues we have seen in the first open beta
2. A new and improved trust model that will allow new indexers to sync to the KRC network from arbitrary peers without relying on a single source of truth
3. An application of the new partially signed Kaspa transaction (PSKT) functionality introduced into rusty-kaspa to implement atomic swap of tokens, a functionality that will allow e.g. implementing KRC dexes without relying on a third party
4. The conditions for a healthy launch for the next open beta. We agreed that the launch should not be rushed, since it's smooth operation relies on things that are outside of Kasplex's hands. In particular: 1. the rusty-Kaspa team would like to see that most wallets implemented RBF (the mechanism that allows increasing fees for already posted transactions), and that it is working as advertised, 2. infra work to make sure there are sufficiently many public nodes that provide wRPC services.
I tentatively suggested mid August as a realistic goal for relaunch, but also recommended against committing to a launch date at this point. Better to do it right than to do it fast.
We also discussed how the node operation and sync could be made much lighter after KIP6 and txn payloads will be introduced in the 10BPS hard-fork, but that will only be relevant further down the line.
It is exciting to see the Kaspa ecosystem growing and the symbiosis between different teams working on different aspects thereof. In particular, it was very pleased to see PSKT implemented and applied almost simultaneously. It comes to show how the ecosystem helps improve the core, and the attentiveness of the core developers to the community, and it is really beautiful to behold.
(Friendly reminder: I am not a part of the Kasplex team, or the ongoing development process. I'm just always glad to help by proposing ideas, participating in discussions, and relying what I learn to the community)
47
169
748
103,786
🚨 Exciting news, Kaspa enthusiasts! 🚨
Kasplex Open Beta is just around the corner! 🕒
Mark your calendars! On June 30th, explore the power of Kasplex and experience l the innovative features firsthand! 🌟
Be among the first to explore Kasplex and contribute to the growth of the Kaspa ecosystem! Your feedback and participation will play a vital role in shaping the future of KRC-20. 🎯
#Kasplex #KRC20 #KEF #Kaspa

112
454
1,270
188,807
We've just released a new update for Kasplex:
03 June 2024 Version 1.02
1、Change allowed ticker length
- Now you can have tickers from 4 to 6 bytes characters long
- Added more tickers to Reserved List
2、Support multisig addresses as KRC-20 receiving addresses
3、Deprecate "daas"&"daae" parameters
4、Optimize script parsing module
24
134
485
58,966
5bb55b retweeted
29 May 2024
#Kaspa 10-BPS testnet #TN11 is looking quite a beauty now
I think this DAG structure is a better reflection of how 10-BPS will look on mainnet. The TN11 node I'm maintaining has 25 peers now and only ~5% hashrate which is a better approximation to mainnet P2P network
46
288
981
145,378
🎉Kasplex is now live on Kaspa TN11! 🎉
Get ready to test and integrate Kasplex into your applications on the lightning-fast 10 BPS Testnet. Don't miss this opportunity to be a part of the Closed Beta. Let the testing begin! 🔬💻
Visit our website at kasplex.org/ to find all the information and documentation you need to get started.
Remember, this beta phase is all about finding those bugs and making sure everything runs smoothly for our developer friends. Your feedback is invaluable, so don't hesitate to share your thoughts and suggestions with us.
Let's make Kasplex the best it can be together! 🚀
#Kaspa #KRC20 #KEF
46
221
663
126,263
📣Calling all developers! 📣
We're excited to announce that the Kasplex beta launch is just around the corner! This Friday, we're kicking off the Closed Beta, and we want YOU to be a part of it! Don't miss this opportunity to test and integrate Kasplex into your applications.
🔗 Join our Telegram : t.me/kasplex_official
In the meantime, we're also in close communication with the Kaspa community to establish a Discord channel. We're working hard to create a space where developers can build, collaborate, and share their experiences with Kasplex on the Kaspa ecosystem.
Let's build the future of Kaspa together! 🌐🚀
#Kasplex #KRC20 #KEF
33
214
543
86,433
Yes the reorganization mechanism of DAG - parallel blocks makes a little complexity, but only a little😎.
19 May 2024

So I was sent this video by @QuaiNetwork (a project I know nothing about) that alleges to compare Quai with $kas. I don't have time to watch a 45 minutes "comparison" video, so I decided I would just watch it up to the first major mistake which arrived (surprisingly?) about 5 minutes in.
The guy who calls himself "Dr K" claims that GHOSTDAG reorgs are easy "because Kaspa is a UTXO chain" and that it would be much more difficult for "smart contracts or an account system", he then assesses that for that reason "Kaspa will never have programmability".
We've heard this kind rubbish since Kaspa launched. Any layer that works above the consensus level (be it UTXO, AAM, EVM, etc.) is agnostic to how the chain is obtained. Any computations that are made, are made with respect to the chain returned by GHOSTDAG. If there is some reorg that changes say the last 10 blocks in the chain, the complexity of recomputing is exactly the same as it would have been in a depth 10 reorg in a regular chain.
The (proven and peer reviewed) security of GHOSTDAG assures that only a small suffix of the chain (that is, the ordering of the entire DAG output by the consensus layer) is ever changed. This is exactly the same as the security properties of say Bitcoin or pre-merge Eth. assuring only shallow reorgs. Beyond that point, the complexity of recomputing is exactly the same.
Arguing that recomputing is more difficult than DAGs is, essentially, not understanding the blockDAG paradigm at all.
I didn't watch the rest of the video, so if a point that's actually salient is made feel free to bring it to my attention. But always remember that the "DAGs can't support smart-contracts" attack vector is futile, and people who use it are either misleading or just haven't properly done their research.
When it comes to Kaspa its the same story every time: 1. people tell us what we are aiming for can't be done (often not as an honest observation but in attempt to step over us to promote their own project),
2. we do it anyway.
Smart contracts and other forms of programmability will be no different.

1
21
1,679