
ななよん、Atsushi Morimoto。休日は電子工作ばかりしてるITエンジニア。📕VS Code実践ガイド執筆。自作⌨、電子工作キット、技術同人誌販売中→ 74th.booth.pm。VS Code Meetupオーガナイザ。最近の活動→ github.com/74th
Joined July 2009
- Tweets 21,589
- Following 669
- Followers 2,504
- Likes 13,389
2,836 Photos and videos












『改訂新版Visual Studio Code実践ガイド』本日発売です!
改訂ポイントはブログにまとめています。
↓
『改訂新版Visual Studio Code実践ガイド』を上梓しました! - @74thの制作ログ 74th.hateblo.jp/entry/practi…
1
18
87
20,442
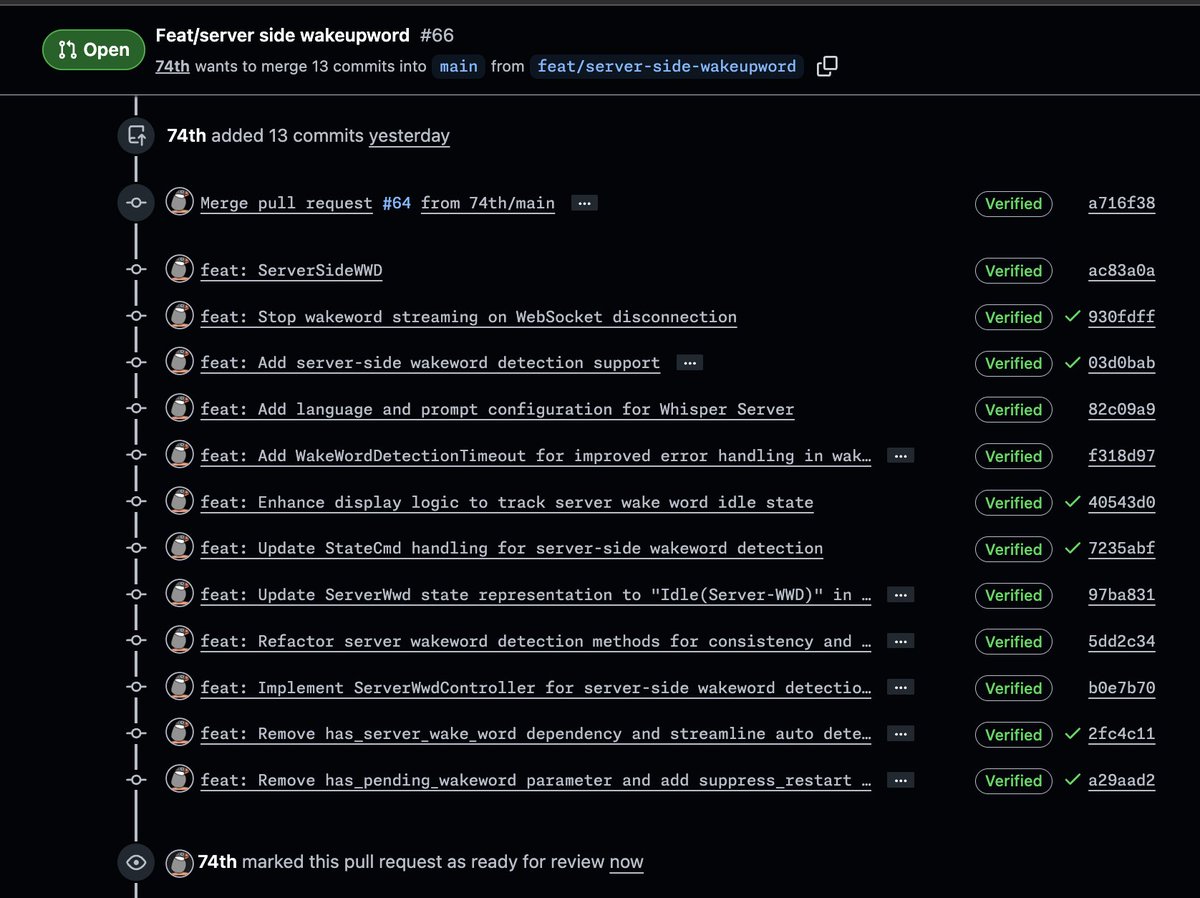
KiCad Basics for 10.0購入者に、付録として無料提供ありがたい! GitHubに慣れていないKiCadユーザに届いて欲しい!
GitHubTokenをKiCadに登録して、gitコマンドの認証通さなくてもいけるんだ。KiCadにブランチ切り替えとか機能がメニューからあるのを知りませんでした。
Jun 13

「KiCad-GitHub Basics」を「KiCad Basics for 10.0」に別冊付録として同梱した。
kosakalab.booth.pm/items/815…
3
445
74th retweeted

Jun 13
「KiCad-GitHub Basics」を「KiCad Basics for 10.0」に別冊付録として同梱した。
kosakalab.booth.pm/items/815…
3
6
776


ATX電源を引き出して、電子工作で使う電源にポートを引き出す制作を開設されている。確かに使えそう、動画の制作過程がしっかりしていて面白い。
↓
古いパソコンを捨てる前に…この部品を抜き取れ! youtu.be/iFABNlbl7n8?si=OOsl…
1
431

llama.cppのバイナリはreleaseページから llama-b9616-bin-ubuntu-rocm-7.2-x64.tar.gz をダウンロードした github.com/ggml-org/llama.cp…
237
同じ感想です。そこまで真剣にではないですが自作に向き合って、🖱️🖲️の補助の域を越えられませんでした(SparrowDial制作)。
KiCad操作やスライド作成もMagicTrackpadで苦じゃなくないくらい慣れ親しめるものです。
Jun 9

トラックパッドはこれがあるのと、MacBookのトラックパッド操作に慣れ親しんでいることもあり、自作で同じ体験を目指すのはなかなか壁が高いのではないかと思います⛰️
Apple
Magic Trackpad (USB-C) - ホワイト(Multi-Touch対応)
amzn.to/4eaEW53
2
415
この後21時から、VS Code Meetupで1ヶ月分の亜プレートを振り返るVS Code Monthly Update April 2026の配信を開始します! #vscodejp
youtube.com/watch?v=erOLZ9P3…
337
llama.cpp の Gemma 4 MTP のPRが昨晩マージされてる
github.com/ggml-org/llama.cp…
243
昨晩からゲーム「ナノアポスル」始めた
ボスオンリーの見下ろし型2Dアクション。ボスの激しい攻撃をパターン見抜いて、パリィとロールでいなして、攻撃を加えていく。ボス戦の楽しい所だけを凝縮してて、アドレナリン出まくって楽しい store.steampowered.com/app/2…
246
74th retweeted

Jun 4
クローゼットの30個のArduinoから始まったスイッチサイエンス@ssci
電子部品をどこでも買える時代に変えた創業者にインタビューしました
fabscene.com/new/interview/s…
34
89
21,325
74th retweeted

Jun 3
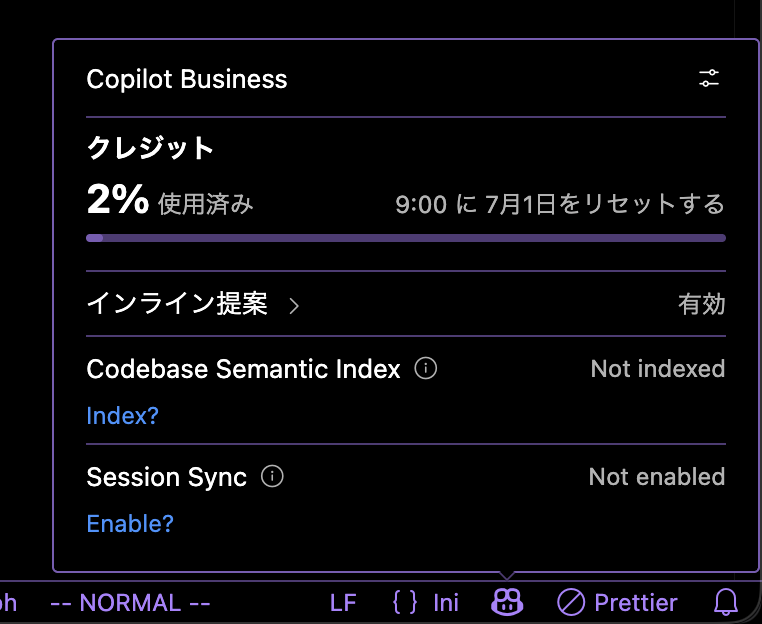
6月1日からGitHub Copilotが従量課金制になり、「今までのプランのままではGitHub AIクレジットが足りず、十分に使えない」といった声をたびたびXで目にします。
編集部としては、弊誌6月号のGitHub Copilot特集の内容も実際に試してみてほしいのですが、多額の費用がかかるかもしれないことを考えると、積極的にお勧めできないのが残念です。
AIの開発・運用には膨大な計算リソースと電力が必要だが、それに比べてこれまでのAIサービスの利用料金は安すぎる。いずれは値上げされるだろう。――そのような指摘はすでに各方面からありました。とはいえ、現実にそうなると辛いものがありますね。他のAIコーディングツールに乗り換える動きもありますが、それで根本解決になるのかどうか……。
GitHub Copilotの料金体系変更についてはWeb記事(以下のURL参照)で補足したものの、「ユーザーは新しい料金体系のもとで、どう利用していくのが効率的か」というところまではフォローできていません。そのようなノウハウはこれから現場で試行錯誤されていくのでしょう。編集部もAIのコスト面に着目した記事を企画していく必要がありそうです。
前述のような金銭面の課題があるとはいえ、GitHub Copilotは、ITエンジニアが使い慣れたGitHubが提供しているものであり、多くの人が使っているVS Codeからも手軽に使えるということで、引き続き利用する方も多いのではないかと思っています(「普段使いのツールの延長線上の機能として使える」というのは、技術選定の大事な要素の一つなのではないかと)。とくに企業からは「GitHub Copilotは組織で導入しやすい」という声が多いと聞きます。
本誌6月号の特集は現時点のGitHub Copilotの全体像を把握できる内容になっています。他のAIコーディングツールとの比較資料としても役立てると思います。引き続き、本特集にご注目ください。
以下に、本特集の誌面の一部や、本特集の追録記事、特定の章の全記事を公開しています。購読を検討する際に、参考になさってください。
▼本特集のすべての章の冒頭の誌面
x.com/gihyosd/status/2057664…
▼本特集の追録記事
(誌面に盛り込めなかった直近の料金体系などの変更についてまとめています)
gihyo.jp/article/2026/05/sd-…
▼第3章の全文無料公開
(Copilot cloud agentなどGitHubと親和性の高い機能の解説が読めます。GitHub Copilotが使えるのはエディタだけだけじゃない!)
gihyo.jp/article/2026/06/mas…
May 22

GitHubというと、同社の内部リポジトリへの不正アクセスの動向のほうが気になっている方々が多いだろうと思われる中、恐縮ですが、弊誌2026年6月号の「GitHub Copilot特集」の宣伝をさせてください。まだ本誌を手に取っていない方のために、恒例の特集誌面の一部紹介です。
今回の特集では、GitHub CopilotがVS Codeなどのエディタで使えることはもちろんのこと、それ以外の多様な環境で使えることと、その可能性をお伝えしています。ご存じない機能や使い方に出会えるかもしれません。ぜひご一読ください。
第1章:GitHub Copilot入門
―特徴、機能、プランの全体像を理解しよう
第2章:VS Codeで始めるGitHub Copilot
―多彩な機能を使い分けて、エージェントを賢く働かせよう
第3章:github. comでCopilotを使いこなす
―コードの調査、AIレビュー、自律実装をWebブラウザで完結
(続きの章の誌面は、リプライへ)




9
454
1,260
404,633
RT @nukonuko: OpenAI の GPT-5.5、GPT-5.4、Codex が Amazon Bedrock で使えるように!
OpenAI API と同価格。学習に利用されない。Codex App や Codex CLI、VS Code などからも。OpenA…
23