
231 Photos and videos









Let's meet in another livestream on Wednesday.
Topic: How to authenticate between AWS & GitHub Actions using OpenID Connect.
Time: 8am EAT.
Link: youtube.com/live/KnWqM2b55sk…
1
153
Before I start my day job tomorrow morning, I'll be live on YouTube improving the codebase of a real business that has been generating revenue for over a year.
If you're interested in software engineering, system design, and seeing how production systems evolve, come join the livestream.
Link: youtube.com/live/5_xco0Rth2w…
1
155
PROD SECRETS
Tomorrow’s livestream:
Doppler Docker FastAPI in production.
See you tomorrow!
youtube.com/watch?v=9zZuscZU…
135
Software engineering is very easy. All you need is a $20 subscription.

We are investigating unauthorized access to GitHub’s internal repositories. While we currently have no evidence of impact to customer information stored outside of GitHub’s internal repositories (such as our customers’ enterprises, organizations, and repositories), we are closely monitoring our infrastructure for follow-on activity.
1
328
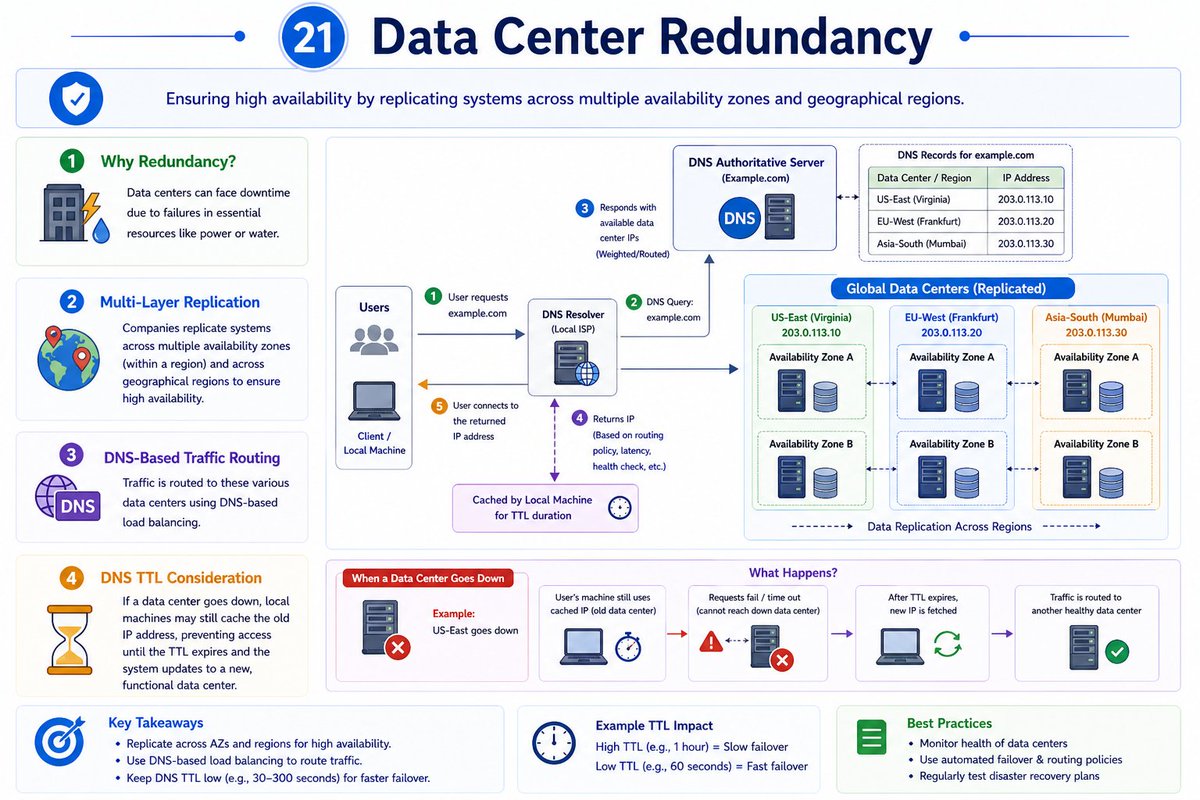
🔵 25. High Availability Patterns In System Design 🔵
➤ Active-Passive Failover
One server handles all traffic while another server stays on standby in case of failure.
The passive server monitors the active server using heartbeat checks and takes over if the primary server fails.
✓ Simple to implement
✓ Lower cost
✓ Automatic failover
✗ Unused standby capacity
✗ Failover takes some time
Goal: Minimize downtime during server failures.
➤ Active-Active Failover
Multiple servers handle traffic simultaneously.
If one server fails, the other continues serving requests without downtime.
✓ High availability
✓ Better scalability
✓ No single point of failure
✗ More complex to implement
✗ Requires session management or shared storage
Goal: Keep the system available even if one or more servers fail.
➤ Master-Slave Replication
One master database handles writes while slave databases handle read operations.
Replication happens asynchronously from the master to replicas.
✓ Improves read performance
✓ Reduces load on master
✓ Easy to scale reads
✗ Master is single point of failure.
✗ Data loss possible if replication lag exists
Goal: Scale read operations and reduce database load.
➤ Master-Master Replication
Multiple database nodes can both read and write data.
Data is replicated between all nodes.
✓ High availability
✓ No single point of failure
✓ Better write scalability
✗ Complex conflict resolution
✗ Higher network and synchronization overhead
Goal: Provide high availability with write scalability.
➤ Availability In Numbers
Availability is measured in “nines.”
- 99% → ~3.65 days downtime/year
- 99.9% → ~8.76 hours downtime/year
- 99.99% → ~52.6 minutes downtime/year
- 99.999% → ~5.26 minutes downtime/year
- 99.9999% → ~31.5 seconds downtime/year
Higher availability requires more infrastructure, monitoring, automation, and cost.
This overview is part of a broader series on system design fundamentals.
Link: youtube.com/watch?v=bb9C_BeS…

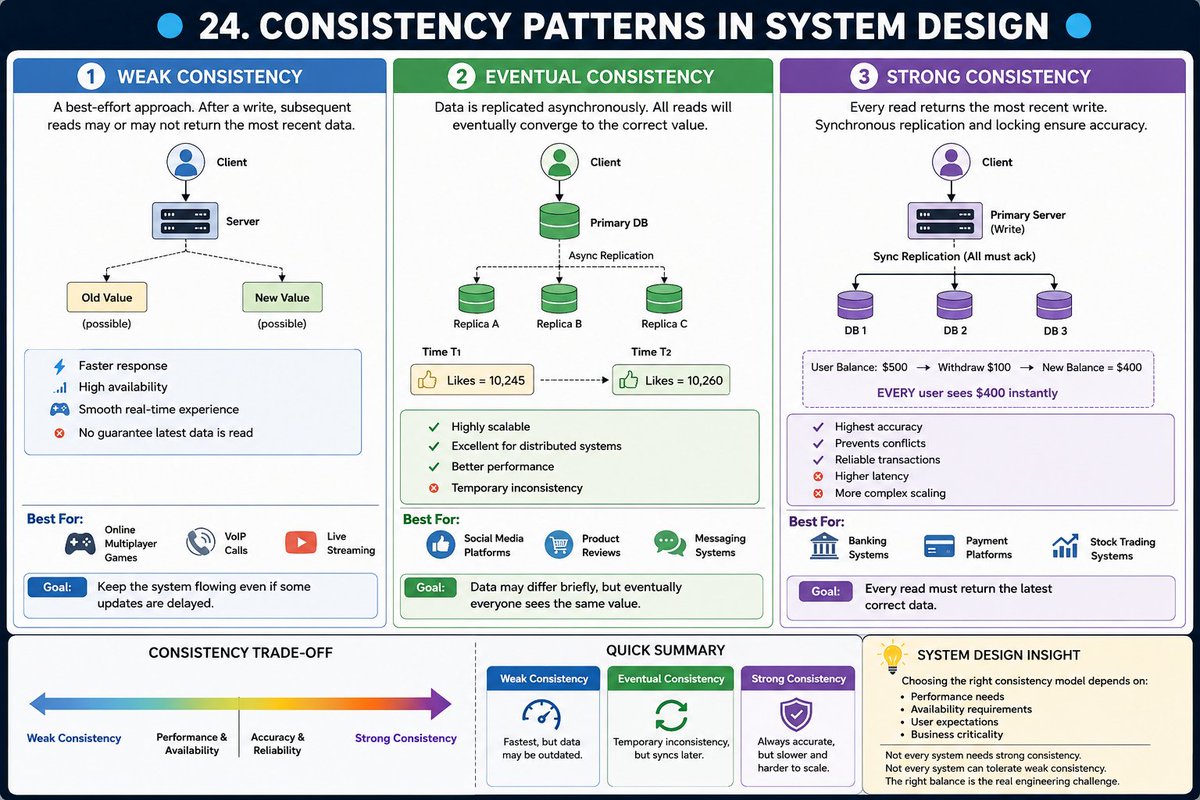
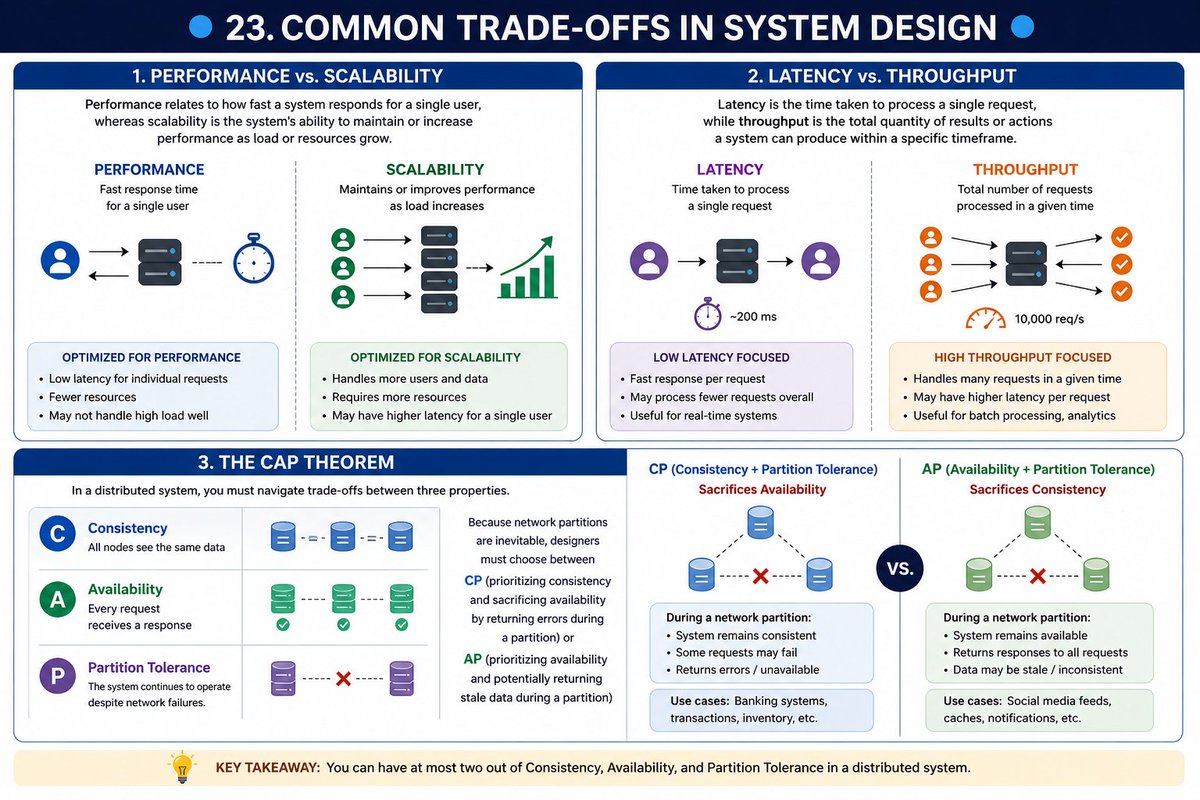
🔵 24. Consistency patterns In System Design 🔵
Three patterns you need to understand to ensure your system behaves as expected under load.
➤ Weak Consistency
In this pattern, a system adopts a "best-effort" approach.
After a write operation, subsequent reads may or may not return the most recent data.
This model is ideal for real-time systems such as VoIP calls or online multiplayer games where maintaining a continuous, fluid connection is more important than ensuring every single data packet arrives perfectly in order.
➤ Eventual Consistency
Eventual consistency is a common choice for high-traffic social platforms.
Here, data is replicated asynchronously, meaning while a write might not be reflected for all users instantly, the system guarantees that all reads will eventually converge on the correct value, usually within milliseconds.
A perfect example is the "like" count on a viral video; while the number might fluctuate or lag slightly for some users, it will normalize shortly.
➤ Strong Consistency
For applications where accuracy is non-negotiable such as banking system, strong consistency is the gold standard .
This pattern ensures that every read operation returns the absolute most recent write.
To achieve this, the system often uses synchronous replication and locks data resources (like account balances) during transactions to prevent any discrepancies.
This overview is part of a broader series on system design fundamentals. Choosing the right consistency model is essential for balancing system performance, availability, and reliability.
1
1
3
414