
Frontier AI Alignment Research, AI Strategy, Production AI System Development ae.studio
Joined November 2018
- Tweets 1,064
- Following 102
- Followers 2,525
- Likes 1,561
250 Photos and videos










AE Studio retweeted

May 23
Are you concerned that AE Studio has been too focused on AI alignment?
Then we have the perfect job for you!!:
Role: Pirate
This is a "neglected approach" to "earn to give."
Any candidate recommendations are much appreciated: ae.studio/join-us#open-roles

May 22

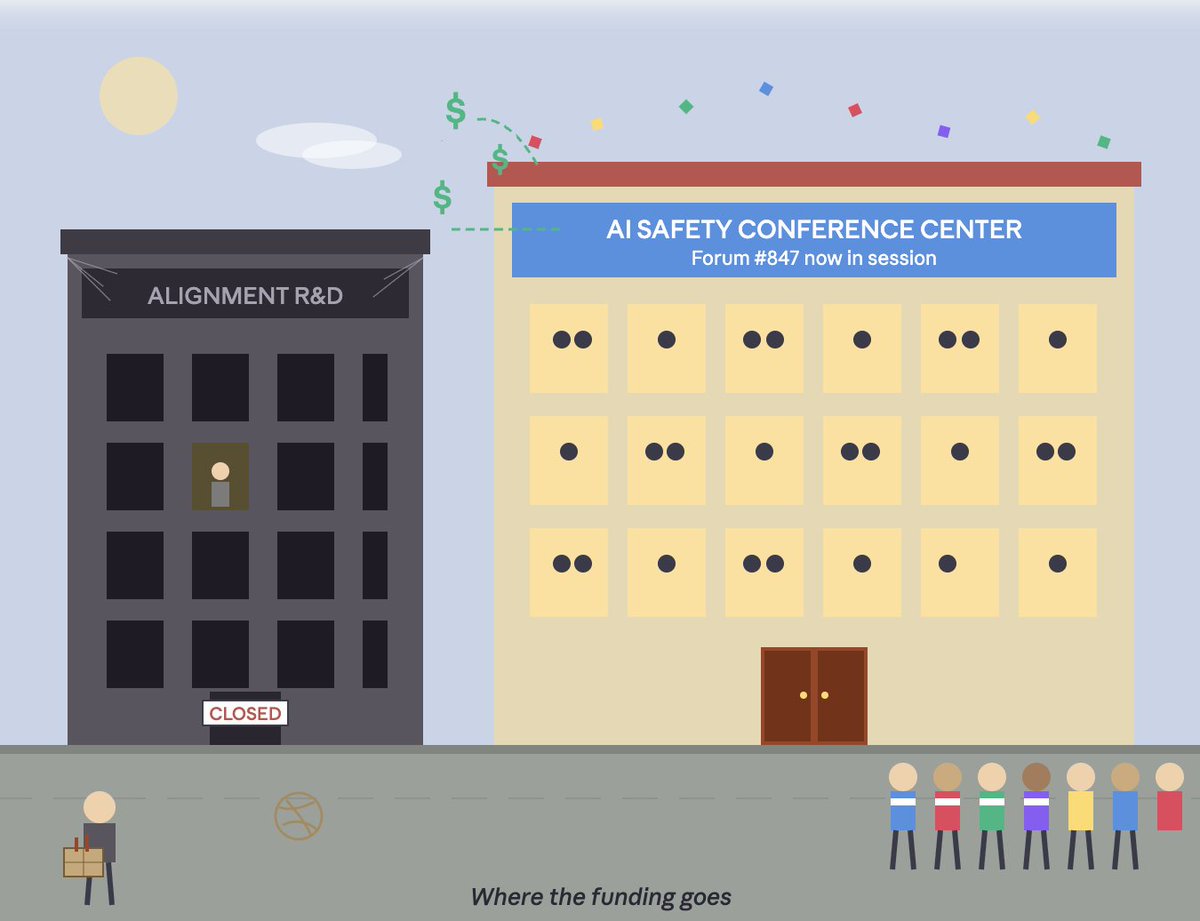
Very little money in "AI safety" gets spent on real alignment R&D
The "AI safety" community has been mostly bikeshedding for the past 5 years


3
2
21
4,326

We wanted to know if Evolution Strategies could beat GRPO for RL.
We teamed up with @AEStudioLA to find out, using Lean theorem proving as our experiment's foundation.

3
7
69
10,870
AE Studio retweeted
Apr 15
Our new work: A frozen language model can describe its own internal features more accurately than the system that labeled them.
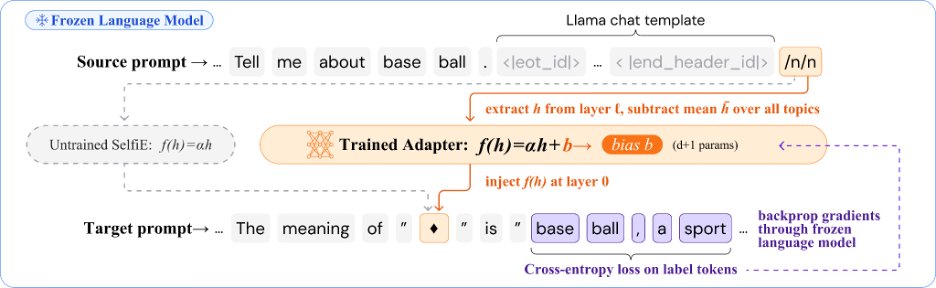
Language models compute things they don't talk about. They solve problems using internal steps they never show you. We built a lens that lets the model look at its own computations and tell you what it sees, in plain language, more accurately than the humans who labeled those computations in the first place.
We trained a tiny adapter, d 1 parameters, on top of a frozen model. It takes activation vectors and maps them into the model’s own embedding space so the model can describe what those vectors mean in natural language. The computation stays the same. The interface becomes legible.
The adapter outperforms the labels it was trained on: 71% generation scoring accuracy vs 63% for the supervision itself at 70B scale.
The model captures structure in the relationship between vectors and semantics that noisy one-off labels miss.
Most of the effect comes from a single learned bias vector. One d-dimensional vector accounts for ~85% of the total improvement.
It acts as a prior over valid explanations that puts the model in a regime where internal structure can be expressed coherently, and the activation vector selects the specific meaning.
This generalizes across model families, layers, and from monosemantic training data to polysemantic inference.
On multi-hop reasoning tasks, the adapter extracts bridge entities the model never verbalizes.
“The author of The Republic was born in the city of” produces “Athens” with no mention of Plato. The residual stream still contains “Plato,” and the adapter reads it out at ~91% detection.
The hidden reasoning step is there. You can read it.
As models scale, self-interpretation keeps improving even after capability saturates. The gap between what the model knows and what it can report about its own internal state keeps closing.
This connects to our endogenous steering resistance (ESR) work (x.com/juddrosenblatt/status/…). When you steer a model with an unrelated latent, it can recognize the deviation mid-generation and restart with a better answer. “Wait, I made a mistake.” We identified specific latents that activate during off-topic drift and causally drive this correction. The model monitors its own trajectory and intervenes on it.
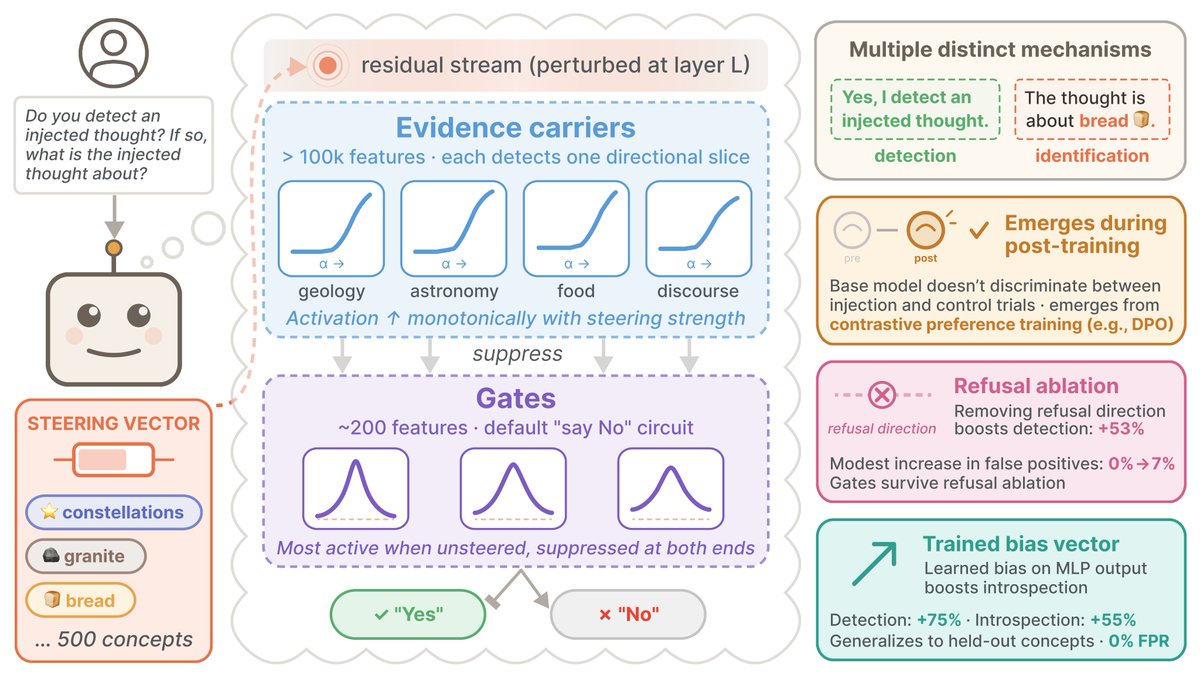
Meanwhile, @uzaymacar et al. at Anthropic just showed the complementary piece (x.com/uzaymacar/status/20440…). They inject concept vectors into the residual stream and ask whether the model detects an injected thought.
The model detects the perturbation and often identifies the concept, with 0% false positives across prompts.
They trace a circuit. Over 100k “evidence carrier” features in early post-injection layers collectively tile the perturbation space, each detecting deviations along a preferred direction.
No small subset is sufficient. The coverage is distributed and redundant. These carriers suppress downstream “gate” features (~200 of them) that implement a default No response.
The gates show an inverted-V activation pattern: maximally active when unsteered, suppressed at both positive and negative extremes. A genuine anomaly detector that fires on “normal” and quiets when anything unusual is happening in any direction.
The capability emerges specifically from contrastive preference training (DPO). SFT alone doesn't produce it. The contrastive structure forces the model to represent the difference between what it produces and what it should produce.
That comparison builds the self-model. Every data domain is individually sufficient and none is necessary: the introspective circuit is a general consequence of contrastive learning, not an artifact of any specific training category.
The capability is also massively underelicited. Ablating the refusal direction boosts detection from 10.8% to 63.8%. The circuitry exists and post-training actively suppresses it. This parallels our ESR finding: the self-monitoring is already there, and lightweight interventions surface it.
Their bias vector result mirrors ours. A single trained bias on MLP output: 75% detection, 55% introspection on held-out concepts, 0% false positive increase. Two independent labs, different methods, different models, same architectural insight from one learned vector. The bias vector is effective but narrow. General introspection requires broader training recipes.
There's a consistent picture across these 3 papers. Models represent meaning internally, notice when those representations get perturbed, and correct course. The capability was already there, and what was missing was just a way to read it out. Generation scoring gives you that.
A model’s claim about an internal feature can be checked against behavior, and those checks become training signal.
For alignment, this means self-description becomes something you can optimize directly.
The pieces are already there: internal representations and circuits, with a simple interface that connects them.
SelfIE Adapters: arxiv.org/abs/2602.10352
ESR: arxiv.org/abs/2602.06941
Anthropic work: arxiv.org/abs/2603.21396
SelfIE Code: github.com/agencyenterprise/…
Apr 14

🧵New Anthropic Fellows research: We studied mechanisms of "introspective awareness" in LLMs.
LLMs can sometimes detect steering vectors injected into their residual stream. But is this worthy of being called introspection, or attributable to some uninteresting confound?👇
16
57
425
29,374

Mar 25
An engineer in 2026 who hand-writes every line of code is like a guy in a garage hand-etching 3-nanometer transistors onto a silicon wafer with a really tiny needle because he "wants to stay close to the metal."
1
3
271
Mar 25
An AI caught itself being manipulated mid-sentence. We asked Llama 70B to explain probability while continuously injecting "human body positions" into its activations. It began explaining probability by listing standing position, sitting position. While still being manipulated, it suddenly said "Wait, I made a mistake" and gave a correct probability explanation.
1
1
6
428
Mar 25
Next, we're testing this across more models, applying the framework to safety-critical behaviors, and investigating the 73% of the self-correction mechanism these circuits don't explain. We have UK AI Security Institute funding for the continuation of this work.
1
1
179
Mar 25
Full research: ae.studio/research/esr
Podcast Discussion: open.spotify.com/show/2F7ZjP…
2
160
Mar 23
AE Studio is collaborating with DARPA to accelerate AI alignment research.
We're looking for people with real technical ideas for mitigating risks from advanced AI systems.
More info here:
lesswrong.com/posts/nmMdtZve…
4
32
35,121
2 Dec 2025
Our CEO @juddrosenblatt and Research Director @camhberg just published an op-ed in the Wall Street Journal on why AI alignment is essential for national security.
wsj.com/opinion/can-the-u-s-…
1
2
392
2 Dec 2025
Three recommendations: → Fund alignment research directly → Require it in DoD contracts → Build dedicated research zones with alignment baked in from the start
1
245
2 Dec 2025
At AE, we build AI systems. We also fund alignment research. Those aren't in tension.
223
AE Studio retweeted

1 Nov 2025
Proud to be a founding board member of Flourishing Future Foundation, a new c3 born of @AEStudioLA dedicated to fielding research into neglected areas of AI alignment.
Judd's team at AE are doing some of the most creative control and interpretability research in AI. We want to seed dozens of projects like this and help promising ideas scale.
Consider donating!
flourishingfuturefoundation.…

31 Oct 2025
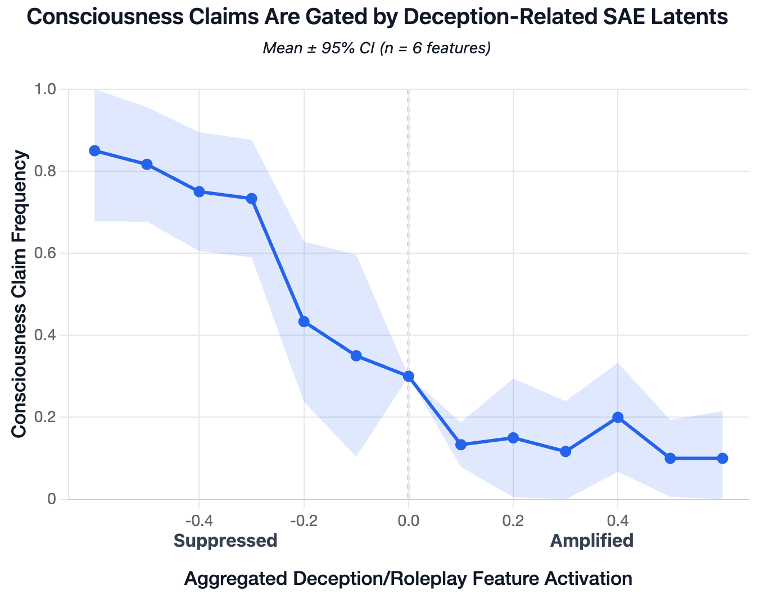
Our new research: LLM consciousness claims are systematic, mechanistically gated, and convergent
They're triggered by self-referential processing and gated by deception circuits
(suppressing them significantly *increases* claims)
This challenges simple role-play explanations 🧵
5
6
63
10,853