
Building @lamatic_ai | Deploying Agents for Every Knowledge Worker
Joined August 2012
- Tweets 1,486
- Following 615
- Followers 973
- Likes 1,432
261 Photos and videos














Apr 11
Tired of guessing which LLM is up and whats its latency
Introducing LLM Ops Toolkit → free, open‑source dashboard for uptime, cost, routing & diversity audits
- Real Time Monitoring & Latency for 18 Providers
- Browser Notifications
- LLM cost Sim
🌐 tools.lamatic.ai
1
2
144
Apr 11
Check it out on github, open-source, light weight and self hosted
github.com/Lamatic/llm-ops-t…
1
103
Mar 25
Spoke at FAU about Agentic AI - how we got here, where we’re heading, and what it takes to build reliable agents. Excited to see such bright minds shaping the future of AI. Thanks Dr. Koch for having me!
2
6
53
Mar 25
Last month @aicollectiveco hosted @make_hq build event in Miami — recap video now out! 🎥
Hands-on automation at @thelabmiami : live demos, real workflow building w/ experts, prizes for best creations. Pure maker energy from Miami's builders! 🔥
1
1
2
336
Mar 24
🎥 @AICollectiveCo Demo Night at Mana Tech was one for the books.
Huge congrats again to our Hall of Fame winners NextHello and Reader and thank you to everyone who showed up, supported, and helped make the event unforgettable. 🚀
1
1
47
Aman Sharma ♦️ retweeted

Feb 10
Introducing... our BRAND NEW global events page!! 📆🌍
Much more coming to the @AICollectiveCo site in the coming weeks... we've been absolutely COOKING! 🧑🍳
3
2
8
358
Jan 30
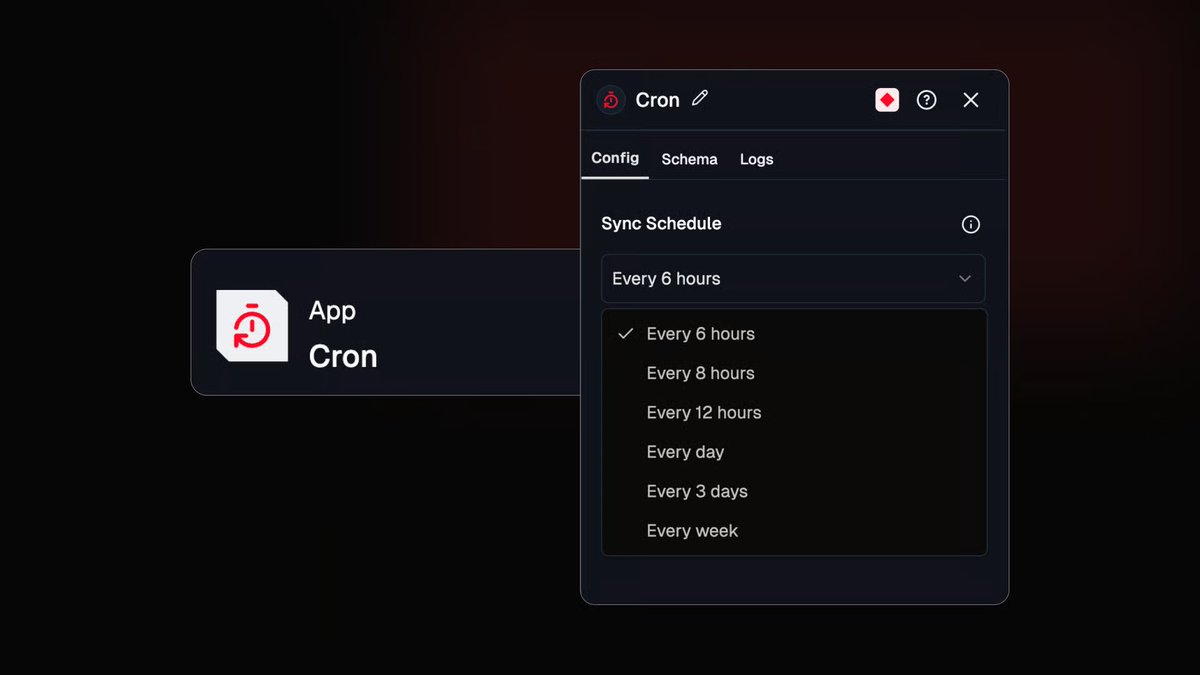
Introducing CRON Trigger
Run millions of agentic requests
with zero configuration and setup
- all running instantly at serverless scale.
Try it out today in studio.lamatic.ai
1
146
Jan 28
🔓 Open Responses is trying to solve a real pain in agentic systems: vendor lock-in.
It defines a common standard for messages, tools, and structured outputs so the same agent can run across different LLM providers without rewriting everything.
1
1
58
Jan 28
biggest realization
Dev engagement is your untapped GTM. You don't need to hunt new customer, you need to farm the existing one.
1
1
67
Jan 27
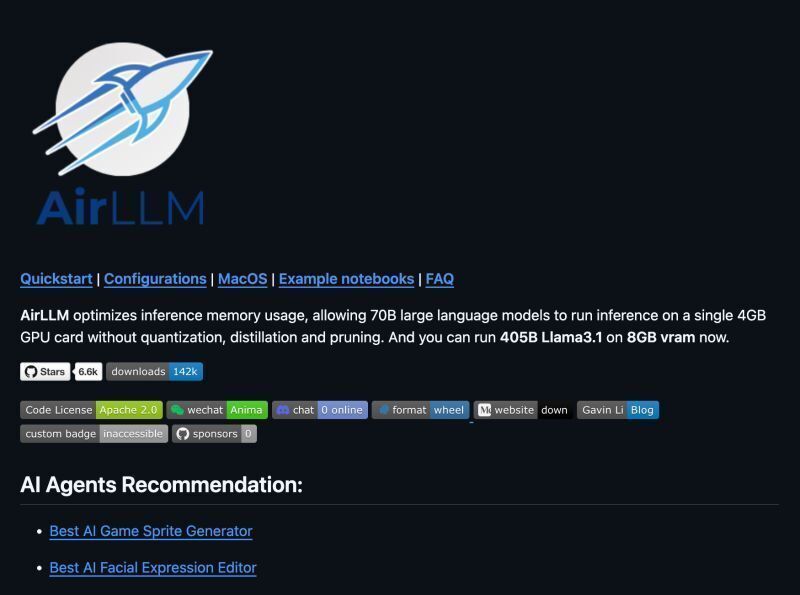
AirLLM is a lightweight open source framework for building autonomous, tool-using LLM agents.
Minimal, modular, plugin based, and no heavy dependencies.
Run Llama, Qwen, Mistral locally. No cloud GPUs. No expensive hardware.
1
189
Jan 27
Building with other founders once again reminded me of the importance of getting out of the building.
40
Jan 22
Using multiple models together beats relying on just one.
Some models are better at reasoning, others at retrieval or long context. Route simple tasks to small models, heavy reasoning to big ones. Chain and specialize them.
The future is multi-model systems, not one best model
1
826
Jan 22
Got my Home-lab setup with
Nvidia RTX 5070 Ti
Whats the first [AI] thing I should do with it?
3
242
Jan 21
🚀 Google AI Studio is pushing file and context limits way higher.
Bigger uploads longer context means models can reason over full documents without heavy chunking. Fewer preprocessing steps, more end to end reasoning.
74