
CS prof at Penn. Amazon Scholar at AWS. Author of The Ethical Algorithm (w/ Michael Kearns). I study machine learning, privacy, game theory, and uncertainty.
Joined May 2007
- Tweets 3,855
- Following 658
- Followers 11,792
- Likes 7,884
272 Photos and videos







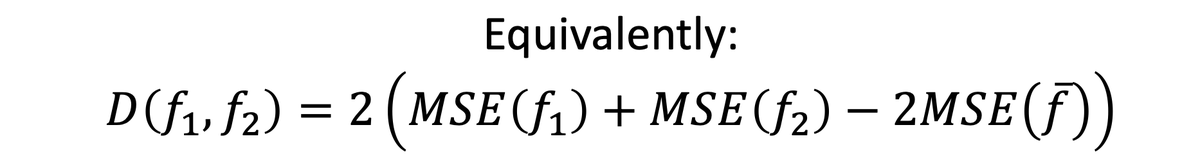
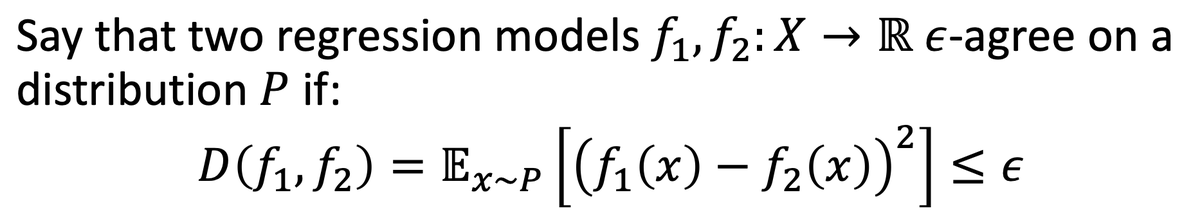



Pinned Tweet

Apr 24
How many samples do you need from an unknown distribution in order to train a model with multicalibration error at most epsilon?
Answer: 1/epsilon^3 samples is both necessary and sufficient.
1
10
81
6,057
Aaron Roth retweeted
Jun 10
Modern LLMs are incredibly good compression algorithms, which can shed light on why autonomous data science agents don't overfit as much as you might think.
Jun 10

Reusing a held-out set adaptively should invite overfitting. Yet in ML we reuse benchmarks for years and they stay informative. Why so little overfitting?
By using LLM agents as extreme compression engines, we get new understanding of why. 🧵
Joint work w/ Martin Bertran and @Aaroth

5
23
4,056
Aaron Roth retweeted

Jun 10
Reusing a held-out set adaptively should invite overfitting. Yet in ML we reuse benchmarks for years and they stay informative. Why so little overfitting?
By using LLM agents as extreme compression engines, we get new understanding of why. 🧵
Joint work w/ Martin Bertran and @Aaroth
3
2
35
7,036
Aaron Roth retweeted

In the last 48h:
- Jr researcher asked me wheter to use AI in making talks
- Saw two talks, with AI {slop, enhanced} slides
Collected my thoughts and wrote a post. Tl;dr: don't steal your own thinking, don't remove *you* from your talks. Also, give a &#@% about your talks.
8
28
258
44,322
Aaron Roth retweeted

May 20
72
238
1,774
564,184
Aaron Roth retweeted

AI has now solved a major open problem -- one of the best known Erdos problems called the unit distance problem, one of Erdos's favourite questions and one that many mathematicians had tried.
openai.com/index/model-dispr…
75
614
3,561
1,489,690
May 20
A clearly hallucinated citation! NeurIPS 2026 decisions aren't out yet. But wait --- the hallucination is also present in the bibtex entries from openreview openreview.net/forum?id=fAjb… and Google Scholar scholar.googleusercontent.co…
7
1
69
22,234
May 12
Recently we showed that the minimax optimal rate for multicalibration is T^{2/3}. But that doesn't mean you have to do that badly on all instances. We give an algorithm that can adapt to easy instances and get better rates while still being minimax optimal in the worst case.
1
4
39
4,372
May 12
The paper is here: arxiv.org/abs/2605.09273 --- this is joint work with Zhiming Huang, Jamie Morgenstern, and Claire Jie Zhang.


2
1
3
1,701
May 13
I just learned about this closely related concurrent paper by Liu, Luo, and Ratliff that went up on arxiv yesterday: arxiv.org/abs/2605.11490 --- it also looks very interesting, check it out!
412
May 5
I'm giving this talk at the MIT CS theory seminar tomorrow. Stop by if you are around!
Apr 16

I've recently been getting invitations to talk about how to use AI tools to assist with TCS research. Its something I've been doing a lot, but don't have structured thoughts about how to explain process. But I'm going to try -- first such talk is tomorrow: cics.umass.edu/events/resear…
1
6
56
8,311
Apr 27
We updated our paper --- and solved the open problem highlighted in the old version. Now our lower bound construction has only polylog(1/eps) many groups instead of poly(1/eps) many groups. The construction is also simplified.
Jan 9
Excited about a new paper! Multicalibration turns out to be strictly harder than marginal calibration. We prove tight Omega(T^{2/3}) lower bounds for online multicalibration, separating it from online marginal calibration for which better rates were recently discovered.
1
12
45
7,155
Apr 24
How many samples do you need from an unknown distribution in order to train a model with multicalibration error at most epsilon?
Answer: 1/epsilon^3 samples is both necessary and sufficient.
1
10
81
6,057
Apr 24
Some interesting things:
- Multicalibration requires substantially more samples than marginal calibration.
- Unlike marginal calibration, multicalibration is just as hard to obtain in the batch setting as the online setting.
1
2
8
984
Apr 24
--There is a phase change. If the group family |G| is of constant size, Theta(1/eps^2) samples are necessary and sufficient. But when |G| > polylog(1/eps), Omega(1/eps^3) samples are necessary and remain sufficient for any |G| = poly(1/eps).
- The upper bounds are randomized.
1
6
429
Aaron Roth retweeted

April is #AIMonthAtPenn! On 4/24, @WarrenCntrPenn faculty affiliate @Aaroth will give the George H. Heilmeier Faculty Award Lecture in Amy Gutmann Hall.
More information and registration here: ai.upenn.edu/heilmeier-award…

1
7
819
Aaron Roth retweeted

FORC 2026 has an excellent set of accepted papers, topics ranging from privacy, fairness, and calibration, to mechanism design, reasoning, and watermarking.
Check 'em out at the conference on June 3 - 5 at Harvard. Registration is open (and free!). Travel support deadline: 4/24


1
3
11
2,705
Apr 16
I've recently been getting invitations to talk about how to use AI tools to assist with TCS research. Its something I've been doing a lot, but don't have structured thoughts about how to explain process. But I'm going to try -- first such talk is tomorrow: cics.umass.edu/events/resear…
1
10
71
14,736
Apr 15
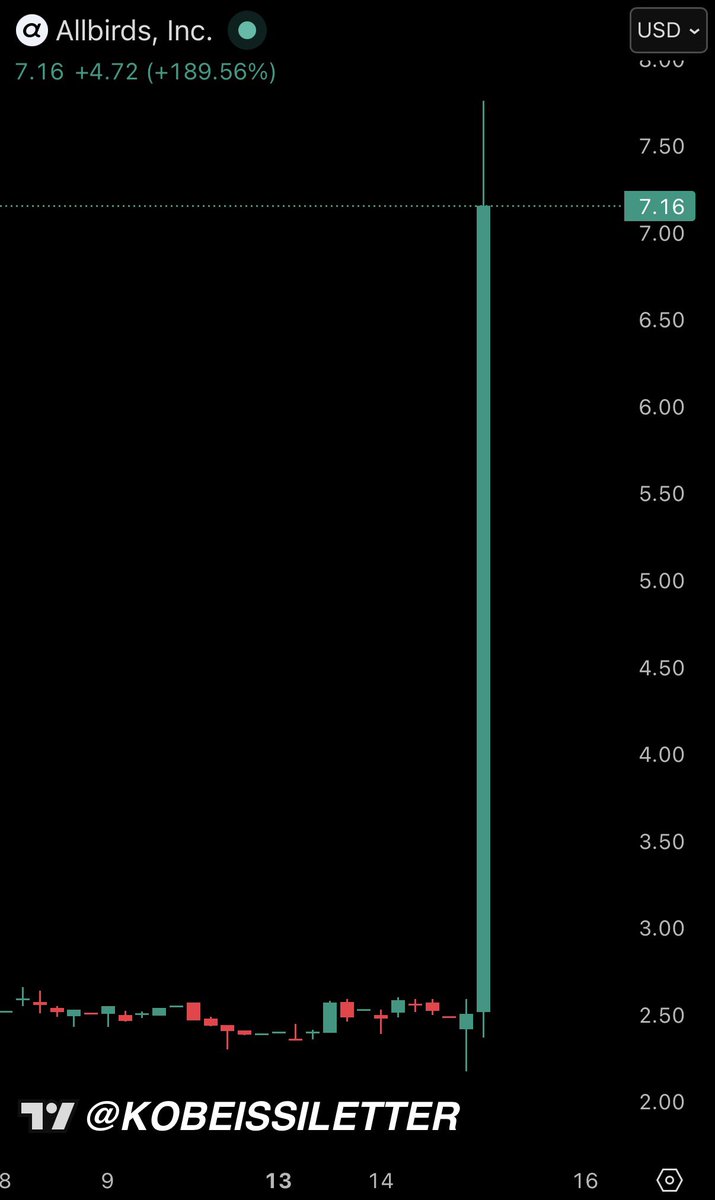
Every theoretical computer science researcher

BREAKING: Allbirds stock, $BIRD, surges over 200% after announcing they are pivoting from shoes to AI.
2
4
97
12,007