
Working on learning | @MIT_CSAIL
Joined September 2022
- Tweets 81
- Following 573
- Followers 2,028
- Likes 1,570
16 Photos and videos

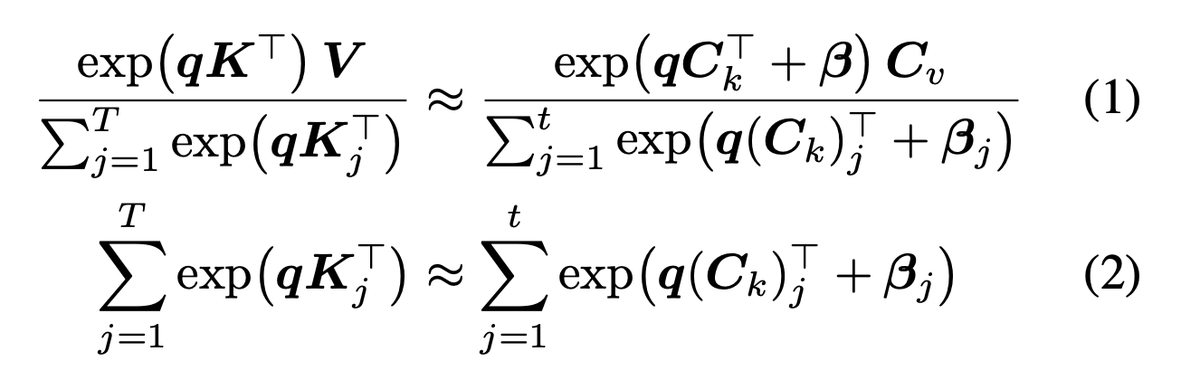






Pinned Tweet

Feb 19
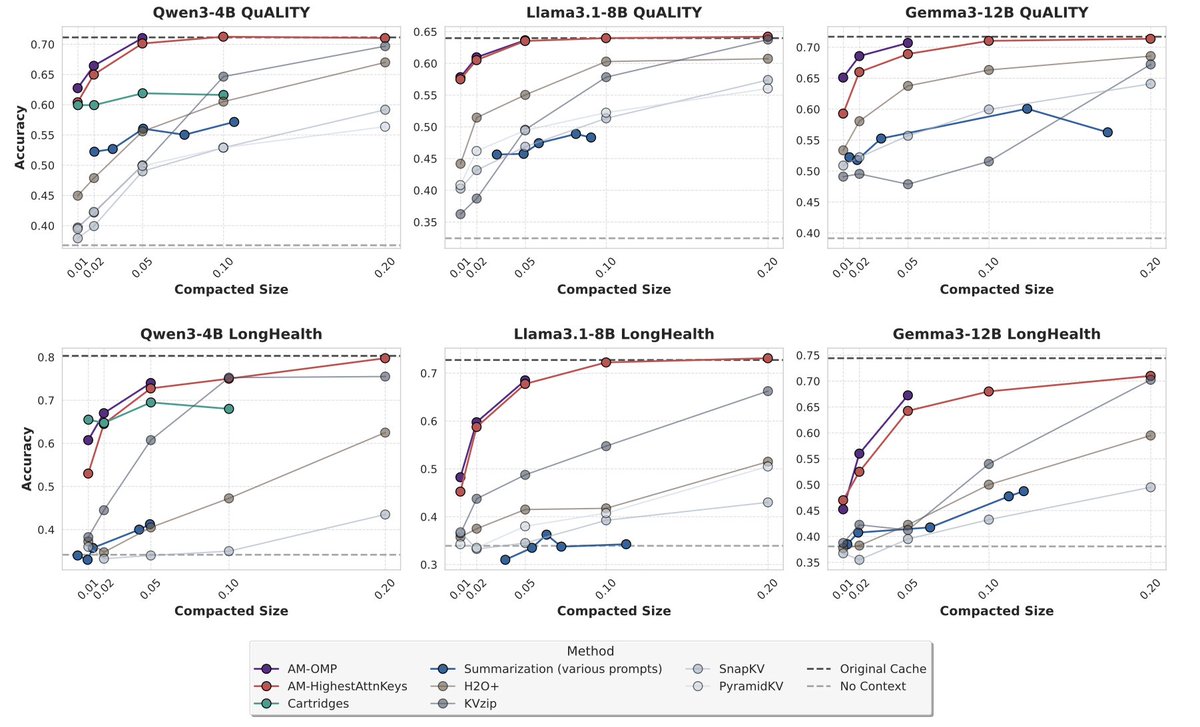
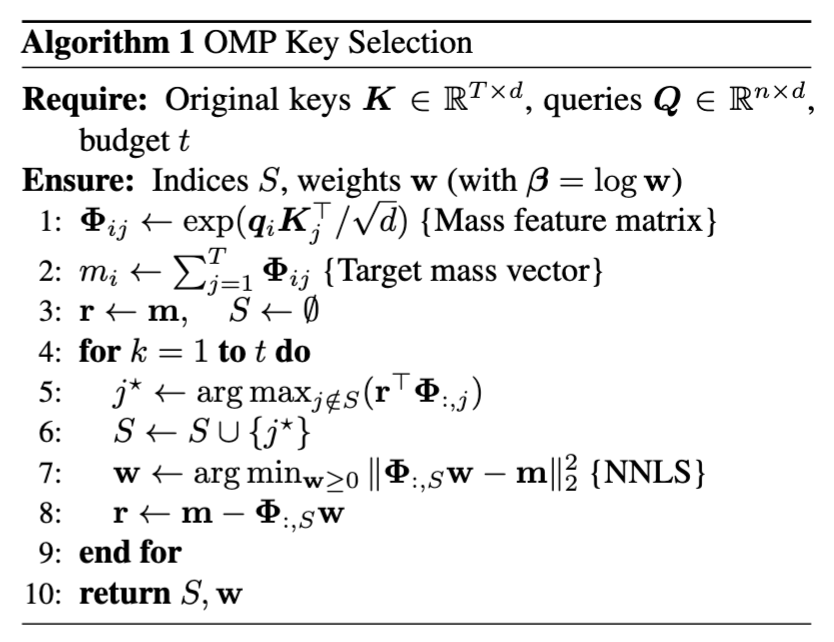
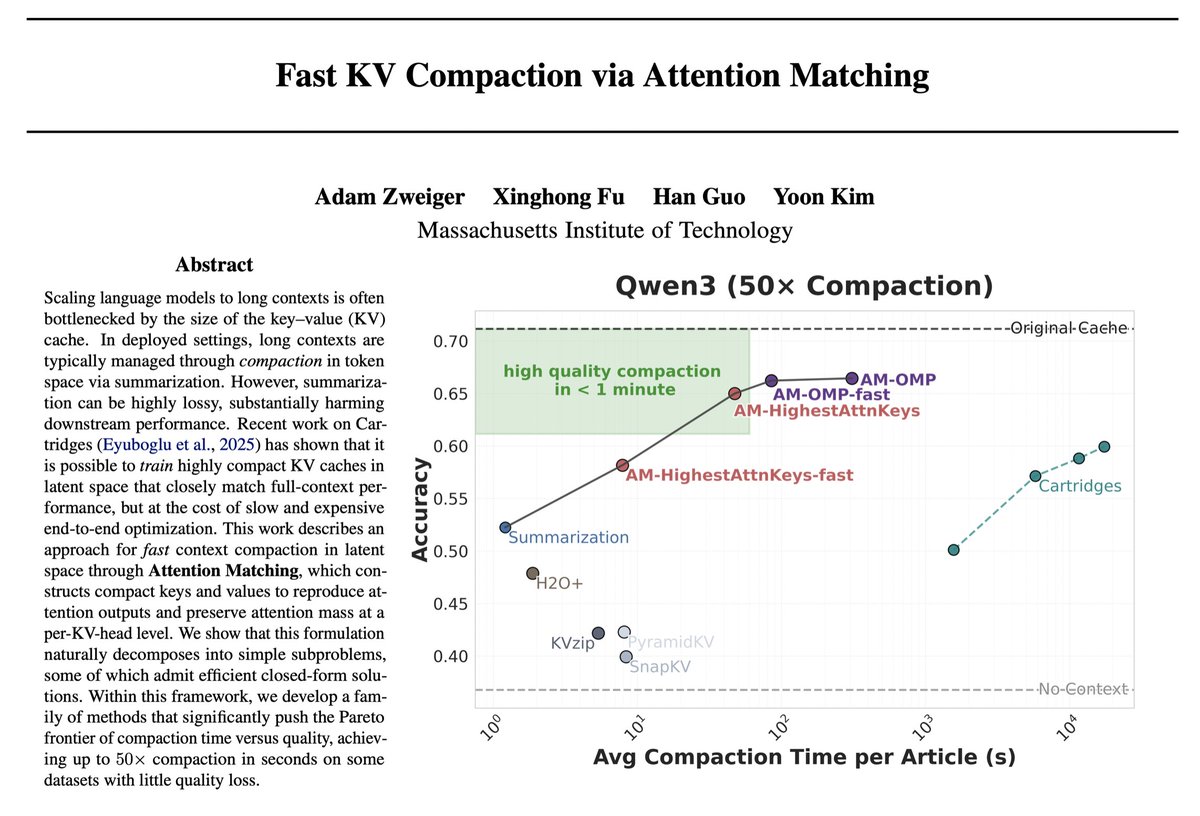
We introduce a new approach for fast and high-quality context compaction in latent space.
Attention Matching (AM) achieves 50× compaction in seconds with little performance loss, substantially outperforming summarization and other baselines.
24
148
941
130,861

LLM training is built on fast MatMuls. But many surrounding ops still run as memory-bound kernels.
CODA reparameterizes them to hide in the matmul’s shadow, fused into its epilogue before results leave the chip.
Bonus: LLMs can write fast CODA kernels too (approaching SoLs).

15
103
686
197,867

40
142
1,433
363,835
Mar 31
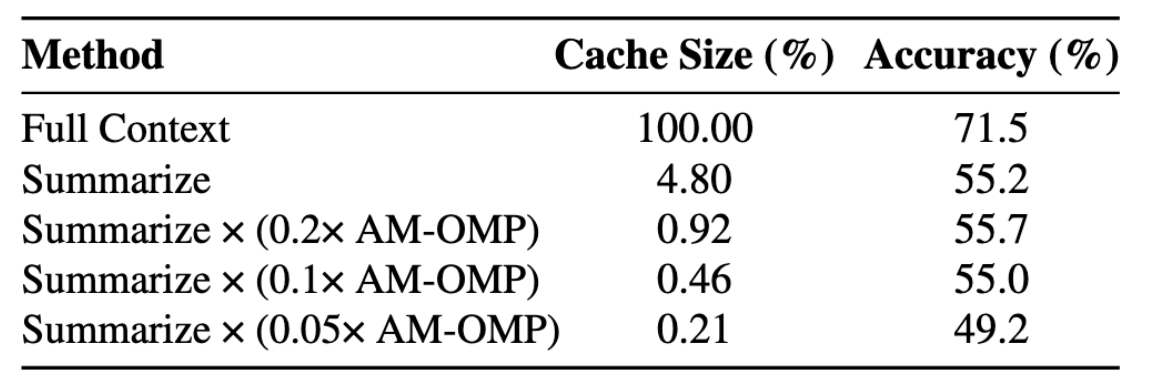
The biggest reduction in KV cache memory comes not from quantization or MLA, but from latent compaction, along the sequence dimension.
More strong results coming soon with Attention Matching.
Feb 19

We introduce a new approach for fast and high-quality context compaction in latent space.
Attention Matching (AM) achieves 50× compaction in seconds with little performance loss, substantially outperforming summarization and other baselines.
5
44
403
33,673
Adam Zweiger retweeted

Mar 12
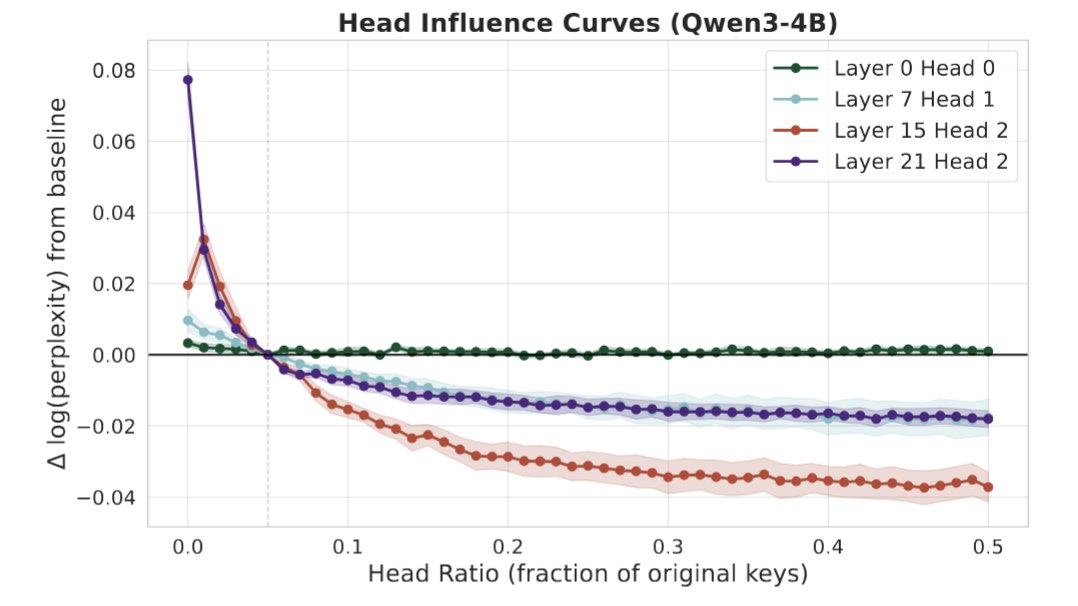
just got claude to explain attention matching and it made this interactive heatmap to show the relative importance of each layer/head!
this might just be better than the diagrams in our own paper...
1
5
57
3,311
Mar 1
New coding model from @cognition! I helped train it during my internship there. The team is very strong and this is just the beginning!
Mar 1

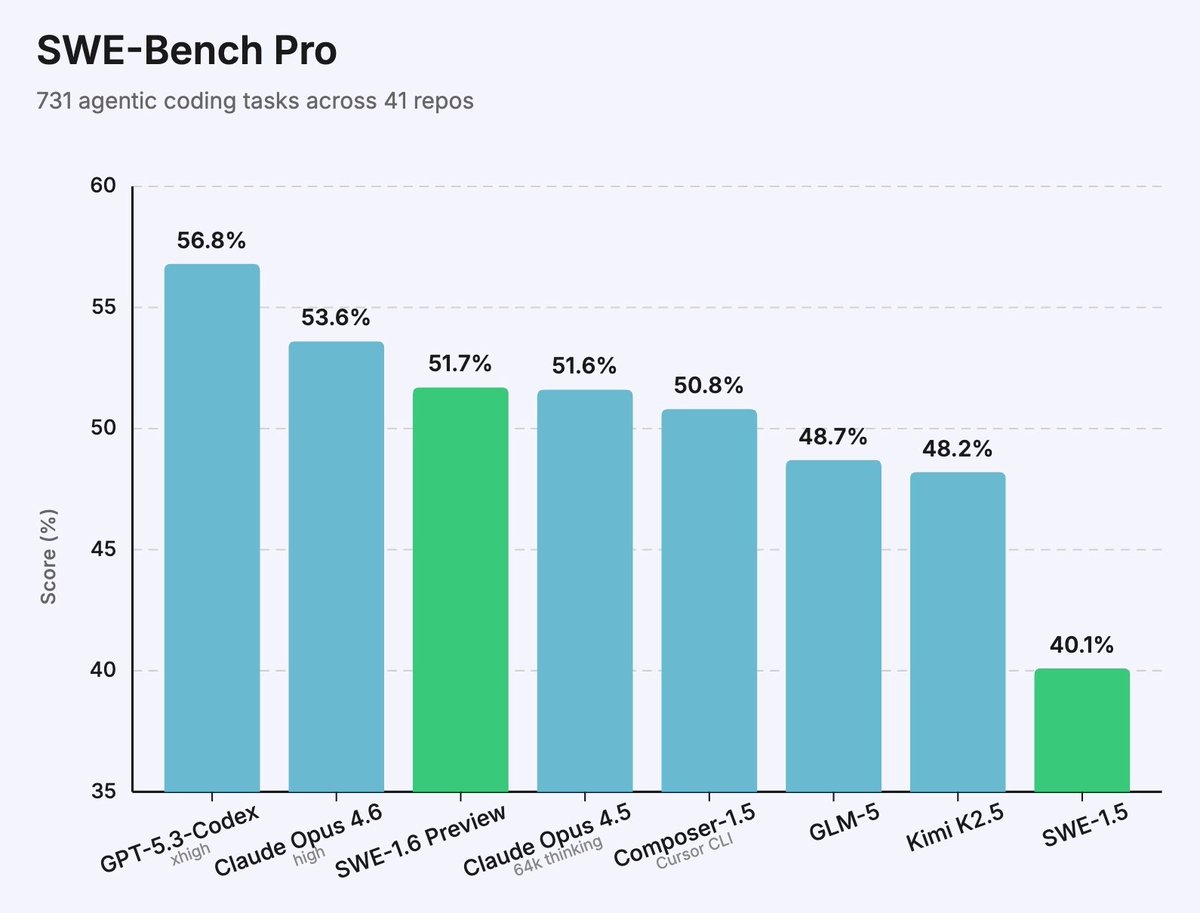
We are sharing an early preview of our ongoing SWE-1.6 training run.
It significantly improves upon SWE-1.5 while being post-trained on the same pre-trained model - and it runs equally as fast at 950 tok/s. On SWE-Bench Pro it exceeds top open-source models.
The preview model still exhibits some undesirable behaviors like overthinking and excessive self-verification, which we aim to improve. We are rolling out early access to a small subset of users in Windsurf.
4
5
96
9,726
Feb 28
Fun fact: Back in 2014, Demis had a red line condition for any potential acquisition of DeepMind: "no technology coming out of DeepMind will be used for military or intelligence purposes."
Google accepting this more eagerly was part of why Demis chose them over Facebook. This red line is even broader than Dario's (no mass surveillance or fully autonomous weapons), though it was quietly removed by Google 1 year ago.
7
36
985
81,180
Adam Zweiger retweeted
Feb 19
the solution to infinite context was just linear regression all along
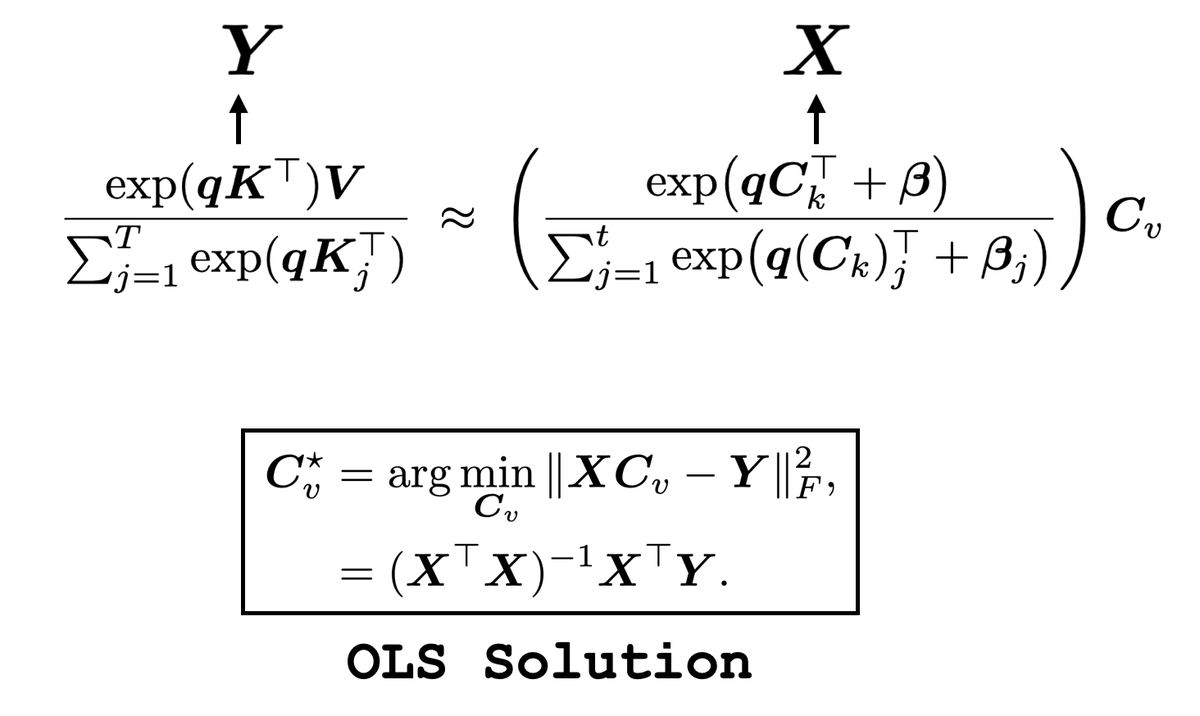
32
112
1,567
189,224
Feb 19
We introduce a new approach for fast and high-quality context compaction in latent space.
Attention Matching (AM) achieves 50× compaction in seconds with little performance loss, substantially outperforming summarization and other baselines.
24
148
941
130,861
Feb 19
Future Work:
- Integrating latent compaction into inference engines (e.g. RadixAttention, varlen storage, disaggregated compaction)
- Online compaction — compacting mid-trajectory repeatedly to support arbitrarily long sequences. We show initial results but more work remains.
1
2
26
3,380
Feb 19
This was joint work with amazing collaborators: @shinfxh @HanGuo97 @yoonrkim
Paper: arxiv.org/abs/2602.16284
Code: github.com/adamzweiger/compa…
3
39
3,223
11 Dec 2025
Nice work on GAN-style training with a generator and discriminator, both trained with RL. This might be the path to improvement in domains without good verifiers like creative writing.
11 Dec 2025

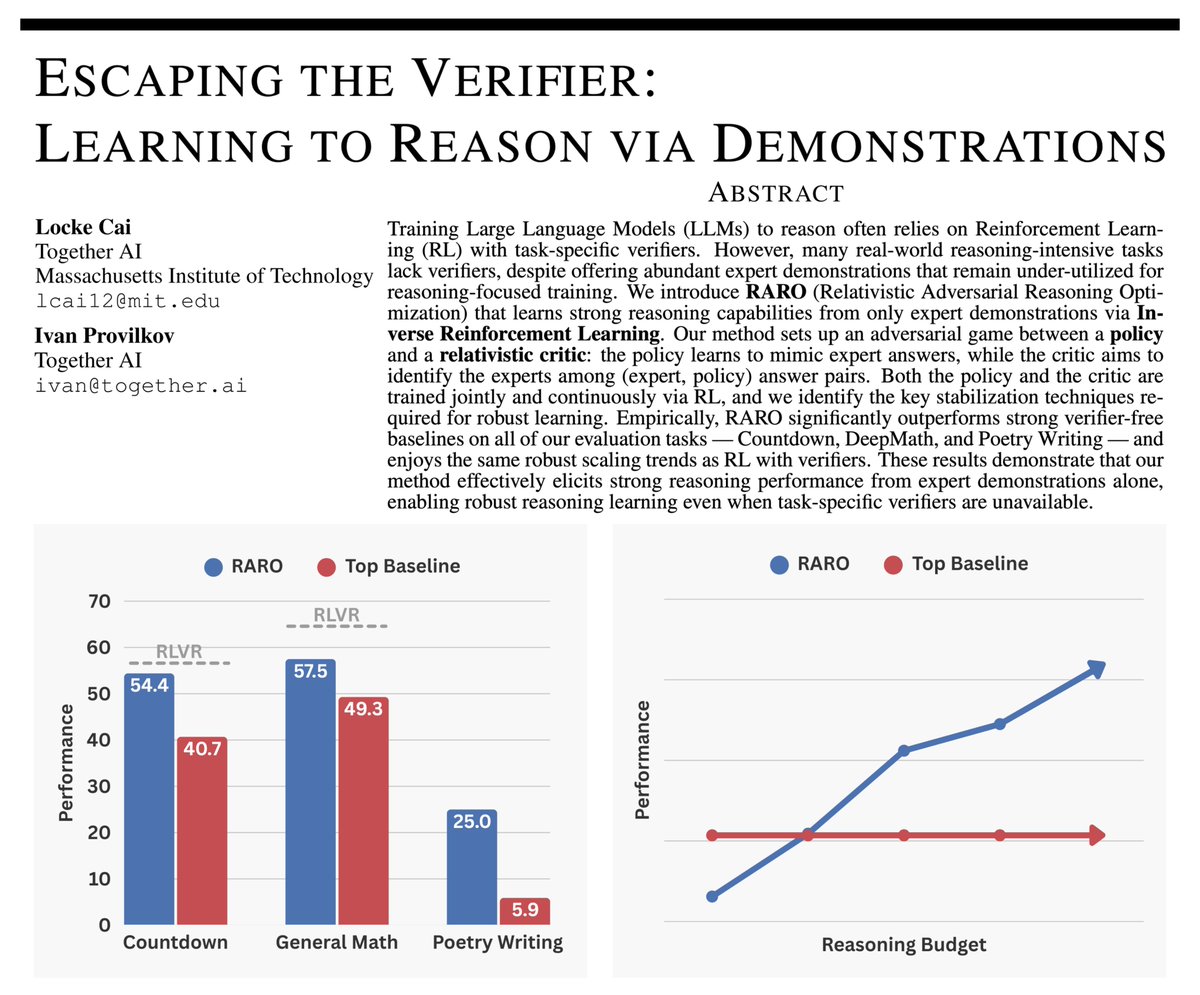
RL for reasoning often rely on verifiers — great for math, but tricky for creative writing or open-ended research.
Meet RARO: a new paradigm that teaches LLMs to reason via adversarial games instead of verification.
No verifiers. No environments. Just demonstrations. 🧵👇
13
1,850
1 Dec 2025
Presenting Self-Adapting Language Models on Wednesday at NeurIPS.
We equip an LLM with the ability to write training data for itself in response to new inputs. We then meta-learn this ability with RL. Stop by to chat!
11-2 pm, #3415, with @jyo_pari @HanGuo97 @akyurekekin
4
5
60
4,455
Adam Zweiger retweeted

22 Sep 2025
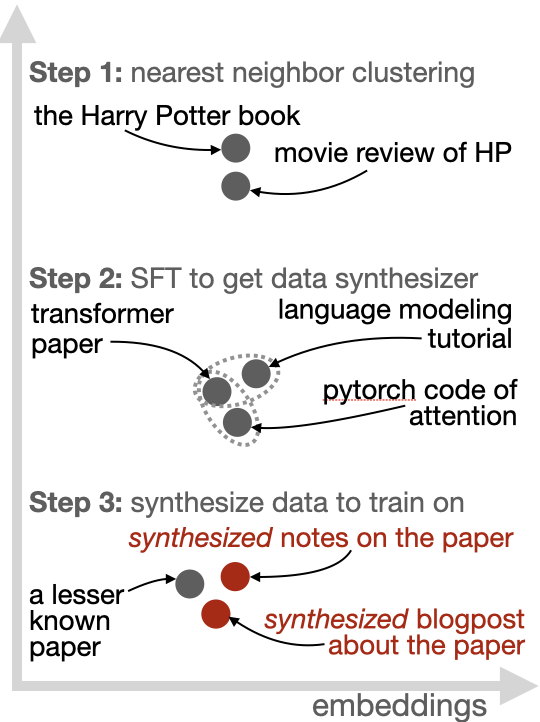
📜 Paper on new pretraining paradigm: Synthetic Bootstrapped Pretraining
SBP goes beyond next-token supervision in a single document by leveraging inter-document correlations to synthesize new data for training — no teacher needed. Validation: 1T data 3B model from scratch.🧵
10
49
256
41,890