
Subscribe to get a free weekly email covering agentic coding tool and model updates. Join 500 agentic engineers.
Joined November 2025
- Tweets 96
- Following 1
- Followers 114
- Likes 35
39 Photos and videos
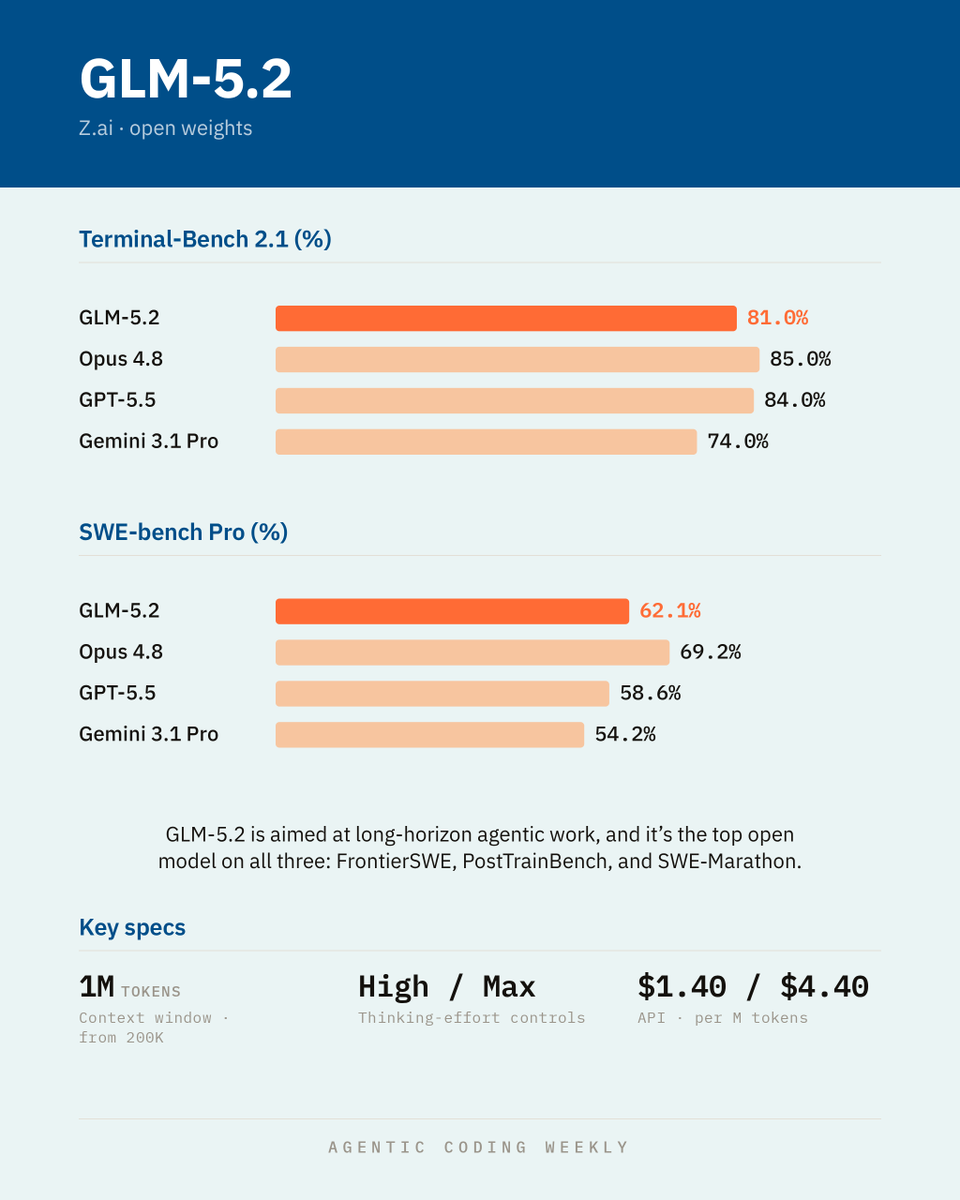






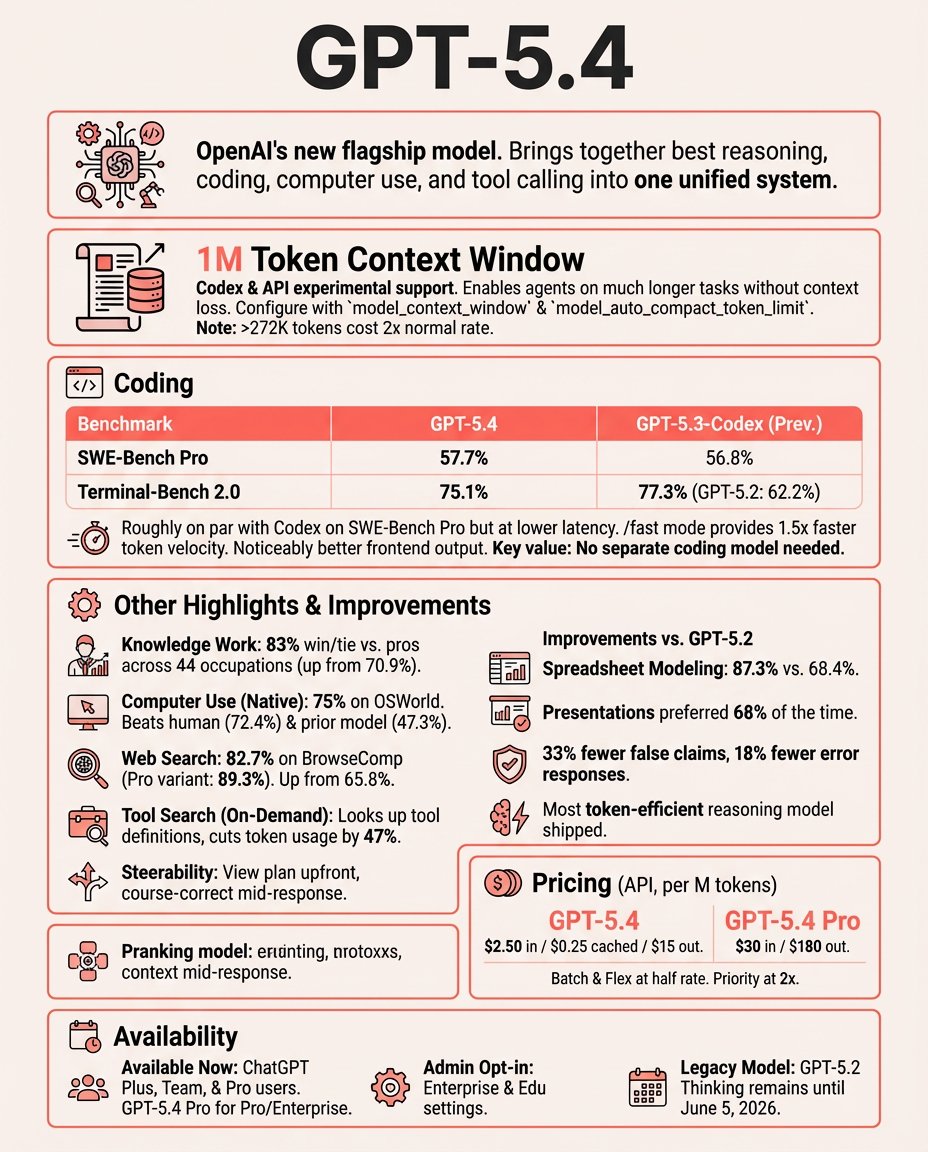
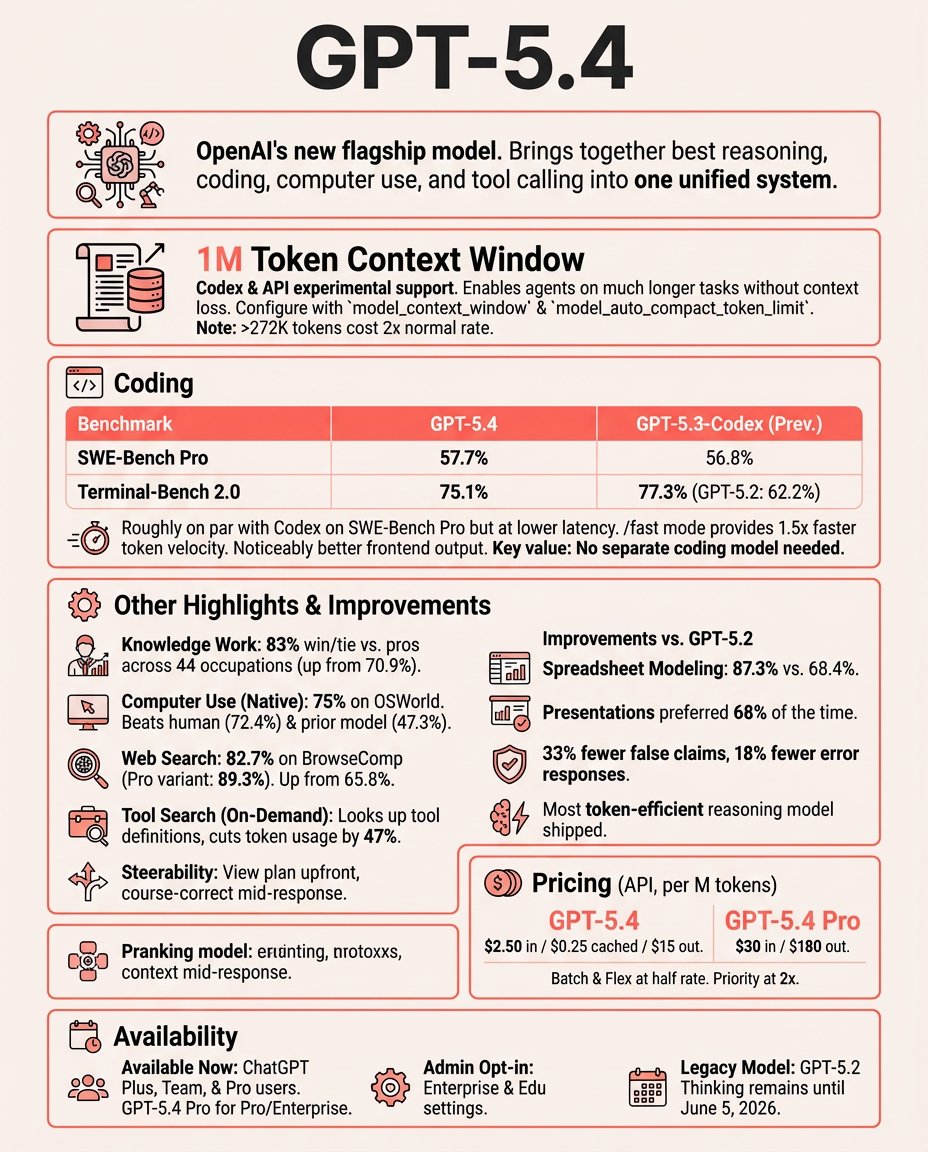


Zai has released GLM-5.2
extends the context window from 200K to 1M tokens and adds High/Max thinking-effort controls
scores 81.0% on Terminal-Bench 2.1 and 62.1% on SWE-bench Pro
2
1
1
32
- On the ultra-long SWE-Marathon it trails Opus 4.8 by 13%
It's the top open model on all three
1
12
API pricing is $1.40 per million input tokens and $4.40 per million output
5
Issue 24 is out, covering agentic coding updates from last week:
Claude Fable 5 & Mythos 5 access pulled by US government, Kimi K2.7 Code, GLM-5.2, MiMo V2.5 Pro UltraSpeed, and MiMo code
Read it in your inbox!
1
1
159
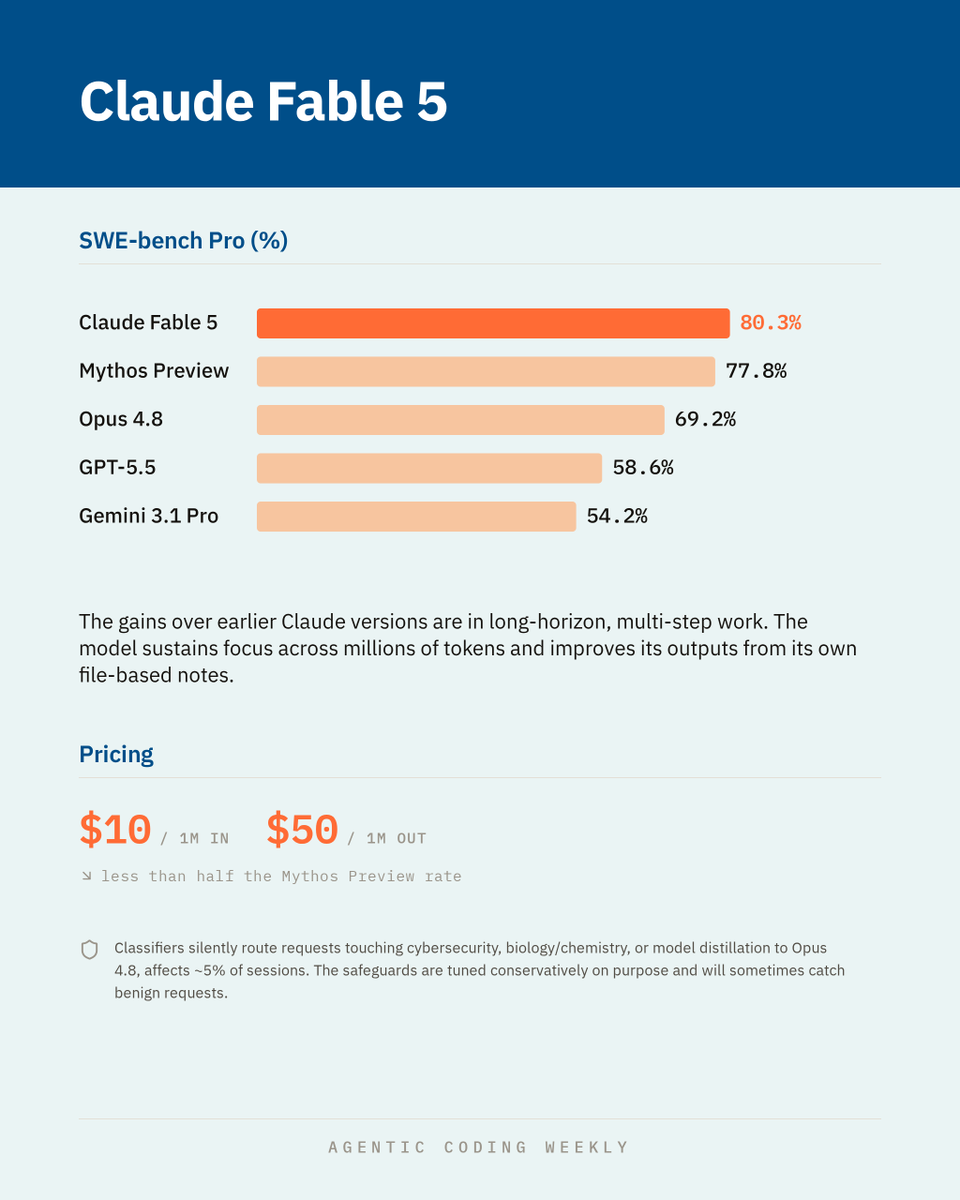
Fable 5 is on the API and consumption-based Enterprise plans now, and included on Pro, Max, Team, and seat-based Enterprise plans only through June 22
After that it requires usage credits until capacity allows it to return as a standard plan feature.
1
25
All Mythos-class traffic carries a mandatory 30-day data retention policy, and that data is not used for training
3
On Terminal-Bench 2.1 it scores 88.0% against Opus 4.8's 82.7%, GPT-5.5's 83.4% (Codex CLI), and Gemini 3.1 Pro's 70.7% (Gemini CLI)
1
32
Anthropic has released Claude Fable 5, a new "Mythos-class" model that sits above the Opus tier
On agentic coding it scores 80.3% on SWE-bench Pro, ahead of the Mythos Preview model (77.8%), Opus 4.8 (69.2%), GPT-5.5 (58.6%), and Gemini 3.1 Pro (54.2%)
1
1
1
67
Agentic Coding Weekly retweeted

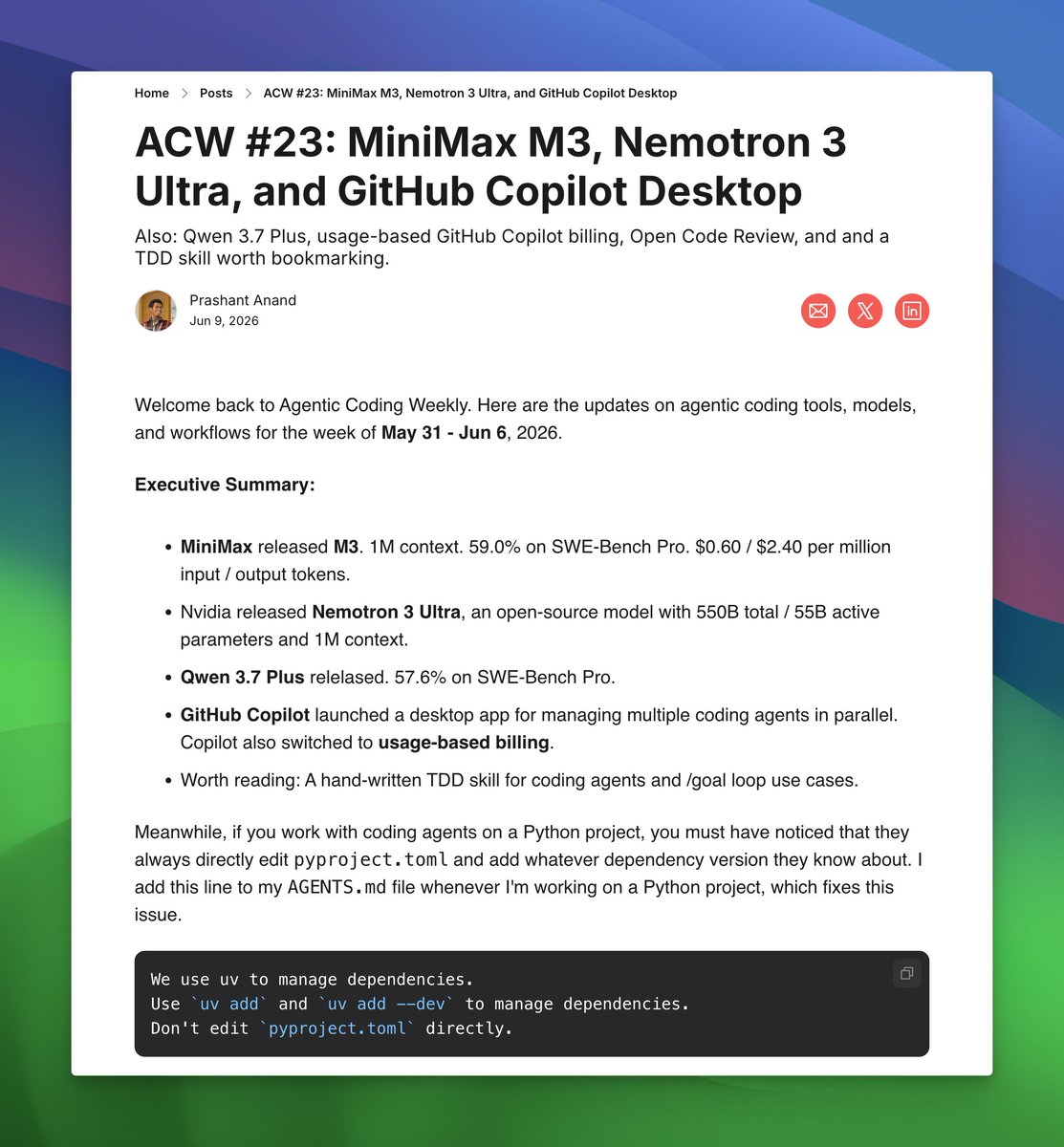
Issue 23 is out, covering agentic coding updates from last week:
MiniMax M3, Nemotron 3 Ultra, Qwen 3.7 Plus, Open Code Review, GitHub Copilot Desktop, and Uber's $1,500/month AI limit
Read it in your inbox!
1
1
2
143
Agentic Coding Weekly retweeted
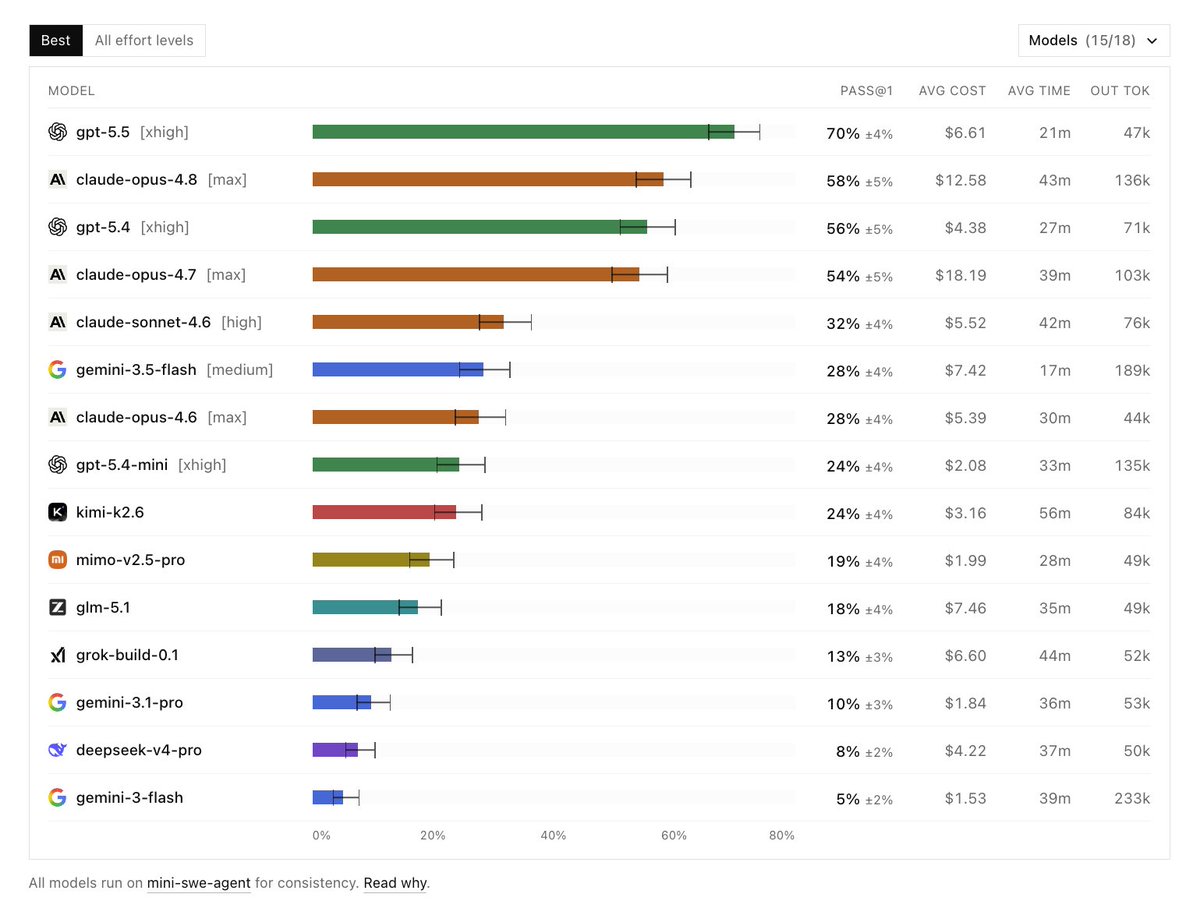
DeepSWE Benchmark: Let's look into what it is first and then where it falls short
This is a benchmark for:
- longer-horizon tasks compared to SWE-Bench Pro
- tasks have a higher diversity and are contamination-free
1
1
3
89
Agentic Coding Weekly retweeted
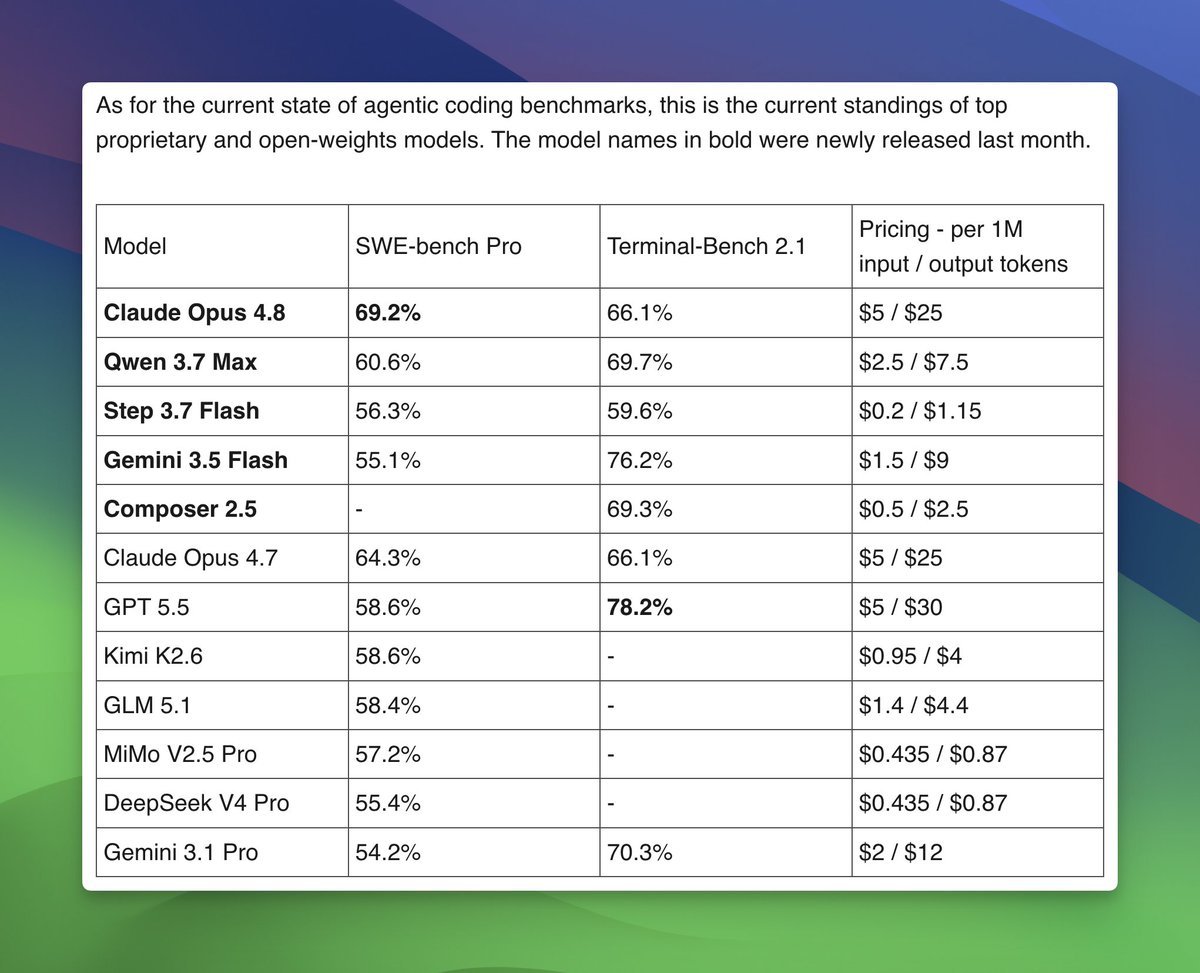
This Month in Agentic Coding: May 2026
1. Tokens are getting both more expensive and cheaper.
The frontier proprietary models got more expensive. Gemini 3.5 Flash is 3x its predecessor 🧵
1
1
1
83
Agentic Coding Weekly retweeted
Launching paid tier for my agentic coding newsletter ($120/year)
You'll get a monthly email on the 1st of every month distilling the previous month of agentic coding updates into a single email
Read the first issue: agenticcodingweekly.com/p/ac…

1
1
3
65
MiniMax has released M3 with 1M context window
Headline architectural change: MSA (MiniMax Sparse Attention)
Cuts per-token compute at 1M context to 1/20 of the previous gen, yielding 9× faster prefill and 15× faster decode
1
1
1
80
Unlike most models, which stalled within 30 submissions, its best result came on submission 145. It also ran ~12 hours to reproduce an ICLR paper
1
13
API pricing is tiered by input length:
- at ≤512K input tokens it runs $0.60/M input, $2.40/M output, and $0.12/M cached reads
- currently discounted 50% for 7 days to $0.30/$1.20/$0.06
- above 512K it doubles to $1.20/$4.80/$0.24
33