
Tackling the boldest computer vision problems @allen_ai
Joined November 2024
- Tweets 175
- Following 29
- Followers 250
- Likes 558
Photos and videos
Prior @ AI2 retweeted

May 29
Seeing more and more people deploy MolmoAct2 zero-shot on off-the-shelf robots is really rewarding (no fine-tuning, no aligning camera, just work)!
We're obviously not there yet, but as a community we're making real strides toward the goal of robots that can simply be deployed right out of the box!
May 29

Ran molmoact2 zero shot on SO101! And it is my first policy on the robot.
I added support on Lerobot to spin up molmoact2 on a VM since I did not have the capability to run the model on my client machine.
github.com/sashenkagamage/le…
@allen_ai @DJiafei @hq_fang
4
35
2,385

Prior @ AI2 retweeted

May 28
MolmoAct2 is now officially available in the LeRobot package 🤩 Try out training MolmoAct2 on your own LeRobot datasets, and deploy it in the real world!
May 28

MolmoAct2 is landing in LeRobot!
Ai2's open Action Reasoning Model combines a Molmo2-ER vision-language backbone with a flow-matching continuous action expert to predict robot action chunks from images, language instructions, and proprioceptive state.
An open robot foundation model built for real-world control, with strong out-of-the-box performance and easy fine-tuning in LeRobot.
Pick-and-place inference running on NVIDIA DGX Spark!
Blog: allenai.org/blog/molmoact2
Paper: arxiv.org/abs/2605.02881
Thanks to
@allen_ai @DJiafei @hq_fang
2
5
25
1,713
Prior @ AI2 retweeted
May 28
Really blows me away how many people are seeing the power and impact of open-science models like MolmoAct2 being deployed out of the box, without any fine-tuning. That’s exactly the future I envision for robotics foundation models.

MolmoAct2 zero-shot on LeRobot SO101 arms even in a cluttered real-world setup, it nails the grasp → drop into bowl task with only a front and side camera!!
No fine-tuning, fully open-source action model going straight from reasoning to manipulation.
This is the future of open source robotic models!!!
@DJiafei @hq_fang @allen_ai
7
27
2,898
Prior @ AI2 retweeted

MolmoAct2 zero-shot on LeRobot SO101 arms even in a cluttered real-world setup, it nails the grasp → drop into bowl task with only a front and side camera!!
No fine-tuning, fully open-source action model going straight from reasoning to manipulation.
This is the future of open source robotic models!!!
@DJiafei @hq_fang @allen_ai
4
10
58
7,618
Prior @ AI2 retweeted
May 28
MolmoAct2 is also fully integrated into LeRobot! Have fun building, deploying and experiencing robotics generalist model being deployed out of the box!
May 28
MolmoAct2 is landing in LeRobot!
Ai2's open Action Reasoning Model combines a Molmo2-ER vision-language backbone with a flow-matching continuous action expert to predict robot action chunks from images, language instructions, and proprioceptive state.
An open robot foundation model built for real-world control, with strong out-of-the-box performance and easy fine-tuning in LeRobot.
Pick-and-place inference running on NVIDIA DGX Spark!
Blog: allenai.org/blog/molmoact2
Paper: arxiv.org/abs/2605.02881
Thanks to
@allen_ai @DJiafei @hq_fang
1
5
22
1,417
Prior @ AI2 retweeted

May 28
MolmoAct2 is landing in LeRobot!
Ai2's open Action Reasoning Model combines a Molmo2-ER vision-language backbone with a flow-matching continuous action expert to predict robot action chunks from images, language instructions, and proprioceptive state.
An open robot foundation model built for real-world control, with strong out-of-the-box performance and easy fine-tuning in LeRobot.
Pick-and-place inference running on NVIDIA DGX Spark!
Blog: allenai.org/blog/molmoact2
Paper: arxiv.org/abs/2605.02881
Thanks to
@allen_ai @DJiafei @hq_fang
8
36
206
24,028
Prior @ AI2 retweeted
May 22
MolmoAct2 is most ideal for post training RL! Excited to see more building on it
May 22

Molmoact2 fine tuned on 35 examples running inference with RTC. Trained the expert head for 20k steps, batch size 8. Very happy with this result and it looks like a great place to build on for experimenting with RECAP, RLT and other methods
1
4
24
3,006
Prior @ AI2 retweeted

May 22
Molmoact2 fine tuned on 35 examples running inference with RTC. Trained the expert head for 20k steps, batch size 8. Very happy with this result and it looks like a great place to build on for experimenting with RECAP, RLT and other methods
10
12
60
7,590

May 22
Happy to see MolmoAct2 being deployed so easily!
May 22

Got the i2RT YAM bot running with MolmoAct2 today.
Off-the-shelf capabilities continue to impress, even in terrible 2am lighting.
Prompt: "place all objects in container"
Waiting on leader arm parts to try fine-tuning
@allen_ai @DJiafei @i2rt_robotics
1
11
637
Prior @ AI2 retweeted

May 22
happy to show what @livekit can help bring to life
over the next few months, we’ll stronghold our position further as the go-to for real-time robot deployment and interaction
this is just a glimpse of what we can do
btw, the thread on the implementation of this demo is here x.com/pham_blnh/status/20577…

@pham_blnh, @chenosaurus and Jacob’s Desktop Robot Assistant looks simple, but the architecture is wild. To move a candy bar, it orchestrates: Voice Agents, VLMs for spatial awareness, ACT policies, and Momo Act 2.
The models are distributed across laptops in the room and an H200 server in Finland, executing physical tasks over the internet with real-time, ultra-low latency.
5
2
17
3,765
Prior @ AI2 retweeted

May 22
Got the i2RT YAM bot running with MolmoAct2 today.
Off-the-shelf capabilities continue to impress, even in terrible 2am lighting.
Prompt: "place all objects in container"
Waiting on leader arm parts to try fine-tuning
@allen_ai @DJiafei @i2rt_robotics
4
14
67
9,959
Prior @ AI2 retweeted
May 22
One week since we released MolmoAct2 and @irenekarrot already had it running on her brand new YAMs out of the box.
Robotics is supposed to be hard. Models that just work feel like magic. 🤖
May 22
Got the i2RT YAM bot running with MolmoAct2 today.
Off-the-shelf capabilities continue to impress, even in terrible 2am lighting.
Prompt: "place all objects in container"
Waiting on leader arm parts to try fine-tuning
@allen_ai @DJiafei @i2rt_robotics
3
7
24
3,869
Prior @ AI2 retweeted
May 22
A week since MolmoAct2 (@allen_ai) launched, and the community response has been incredible — deployments, builds, and out-of-the-box rollouts all over the place. 🤖
We've now released the fine-tuning code, with @LeRobotHF support coming soon.
github.com/allenai/molmoact2
Below: a 2x rollout fine-tuned on just 50 demos 👇
3
14
110
5,773
Prior @ AI2 retweeted

May 20
A side quest I've been doing in my unemployment era is DMing authors of recent robotics papers and asking them to open-source their evaluation episodes onto HuggingFace. Thanks to @DJiafei for open-sourcing the evals that went into Molmoact2, this is a great contribution to the field. If you are robotics person and want your evals shared data to be signal-boosted on X, let me know
huggingface.co/collections/J…
12
13
211
21,693
Prior @ AI2 retweeted
May 20
Open science is in our DNA @allen_ai and i believe openness is key to moving the field forward as a whole.
May 20

A side quest I've been doing in my unemployment era is DMing authors of recent robotics papers and asking them to open-source their evaluation episodes onto HuggingFace. Thanks to @DJiafei for open-sourcing the evals that went into Molmoact2, this is a great contribution to the field. If you are robotics person and want your evals shared data to be signal-boosted on X, let me know
huggingface.co/collections/J…
3
16
3,196
Prior @ AI2 retweeted
May 18
Had a chance to fully read the MolmoACT2 paper today.
Imo, the ablation results are the most exciting part. So many ideas popping.
May 5

Most capable generalist robotics models today are closed or at best, open weights. But robotics won’t reach its ChatGPT moment without real openness.
That GPT moment was built on years of open tools and datasets such as Python, PyTorch, ImageNet and more, that let researchers inspect, reproduce, and build.
Today, we’re introducing MolmoAct 2: a fully open-source action reasoning model for real-world robotics.
We rethought and reshaped everything!
🧵👇
2
31
6,416
Prior @ AI2 retweeted
May 19
I keep getting asked: why are we still evaluating VLAs on LIBERO?
My take: it's adoption. So many people benchmark on LIBERO that the community follows suit. Yes, 98.2% vs 98.7% is hard to distinguish, but it still tells us something about policy efficiency, at least for quick fine-tuning on that domain and those embodiments.
Better benchmarks have emerged since. MolmoSpace, for instance, evaluates more than just VLAs. And even though MolmoAct2 currently tops it among VLAs, there's still plenty of headroom for other approaches like TipTOP (Open-world FM TAMP) to push past it. The ceiling is nowhere near saturated, which makes it great for evaluating at scale in simulation.
Robotics evaluation is far from solved, and no evaluation is perfect yet. But that's exactly what makes the field exciting with so many open questions still on the table.
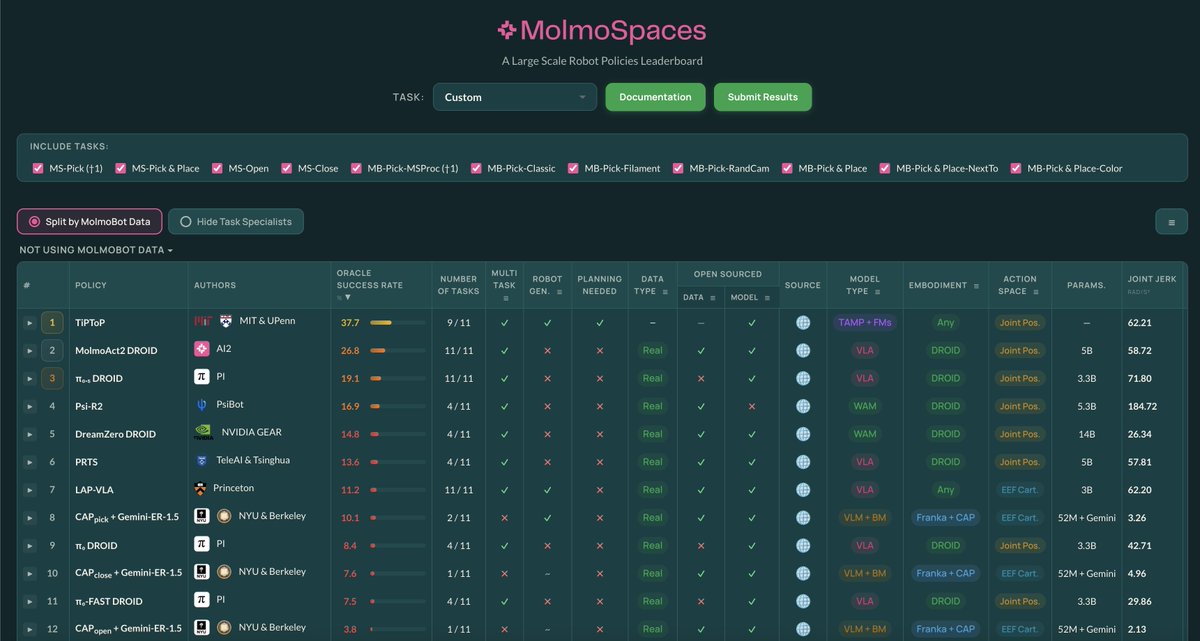
4
9
61
3,807
Prior @ AI2 retweeted
May 18
Just a few days left to enter our Embodied Reasoning in Action workshop challenge @CVPR !
Submit your entry by May 23, 2026 to be considered. You can take part in either challenge or both for a chance at winning cash prizes up to $6,000 USD, sponsored by @BitRobotNetwork, @NVIDIARobotics, and @cortexairobot.
Winners also get the opportunity to present their solution in person at the conference. 🤖

2
5
29
5,986
Prior @ AI2 retweeted

May 17
🎙️The AI Talks
Building Open Science Robotics Foundation Models - by Jiafei Duan @DJiafei & Haoquan Fang @hq_fang
What is critical for real-world robotics? 🤖 Explore MolmoAct & MolmoAct2 - reliable deployment via Action Reasoning, adaptive-depth control, and open datasets. ⬇️

2
6
15
13,055