
Joined January 2011
- Tweets 79
- Following 29
- Followers 235
- Likes 76
10 Photos and videos




Pinned Tweet

Jun 11
Very excited this is out!
I did a deep dive into Mythos' cyber capabilities, and while the story has some complexity, I think it is undeniable we are moving into a scary regime for cyber security,
Jun 11

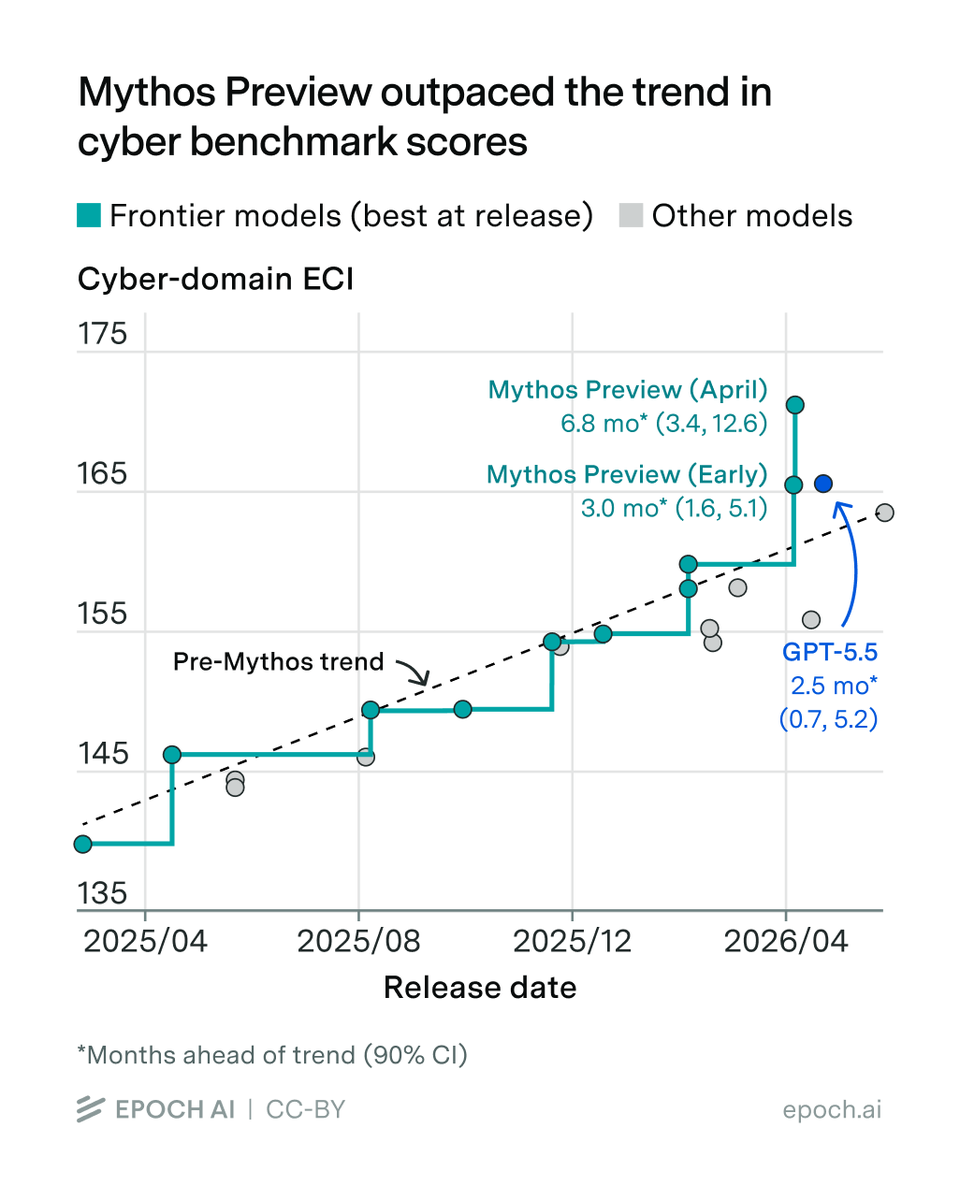
How big a leap is Mythos in cyber capabilities?
@timotheechauvin, @AlexBarry4, @js_denain, and @ansonwhho compiled the public evidence and found that while it’s unclear if Mythos was ahead of trend in discovering vulnerabilities, it represents a big jump in exploiting them. 🧵
4
18
1,053
Alexander Barry retweeted

Jun 12
My takeaways from chats with @AlexBarry4: For previous models, if you spend enough tokens they could find vulnerabilities but couldn't do much with them. Mythos (and to a lesser extent 5.5) is much more capable at using those vulnerabilities to create exploits for e.g. arbitrary code execution
‼️More than that, when Microsoft releases a public patch to Windows, it can take a weekish to propagate to all computers. Mythos can sometimes build exploits from that patch release in a few hours which can run on all computers who hadn't received that update yet. (5.5 can occasionally do this)
Basically before a model of this cyber capability is open sourced, we need to radically change how we do cybersecurity! This is substantially scary!
Jun 11
How big a leap is Mythos in cyber capabilities?
@timotheechauvin, @AlexBarry4, @js_denain, and @ansonwhho compiled the public evidence and found that while it’s unclear if Mythos was ahead of trend in discovering vulnerabilities, it represents a big jump in exploiting them. 🧵
2
11
762
May 29
Continuing with tradition I used Opus 4.8's AECI values to predict its METR time horizon: estimated 50% time horizon of 20.0 hours, 80% time horizon of 2.8 hours.
See more details (including why METR's early Mythos Preview results have been misinterpreted) in my post below
1
6
53
4,511
May 26
Chance to (indirectly) tell me what to do by telling us what Epoch outputs you find most valuable
May 26
Help us produce the most useful work on AI by taking our 5-minute survey: docs.google.com/forms/d/e/1F…
(You can sign up at the end to join our compensated user research panel.)
1
1
12
2,187
Alexander Barry retweeted

May 22
(1) We are likely on track to develop AI systems capable of causing human extinction/permanent disempowerment, quite possibly within the next few years
40
56
586
295,017
May 20
Excited to announce I am joining @EpochAIResearch as a senior researcher. My remit will include managing the Epoch Capabilities Index, as well as other projects to understand progress trends.
If you have any ideas for improvements/extensions to the ECI please reach out!
6
5
111
12,725
May 20
Was fun to work on this as a first application of the domain-specific ECI. I think this (and other) approaches should expand our ability to understand LLM abilities in a more fine-grained way.
May 15
Claude is typically better at software engineering and worse at math than frontier competitors.
Aggregating benchmarks to create our domain-specific ECI, we find the Claude family has an average SWE-ECI 2.7 points higher than their general ECI, and a Math-ECI 1.8 points lower.

1
16
1,320
Apr 30
I used GPT 5.5's ECI values to predict the METR Time Horizon values it will receive.
This predicts it will have a 50% time horizon of 10 hours, and an 80% time horizon of 1.6 hours.
These are below my predictions for Opus 4.7 (but would beat the current best 80% TH).
2
2
35
2,086
Apr 30
These results are influenced by GPT 5.3-codex and GPT 5.4 having quite low time horizon values compared to their ECIs.
This might be partially caused by an unusual amount of reward hacking attempts. Removing them gives a somewhat different fit:
1
3
252
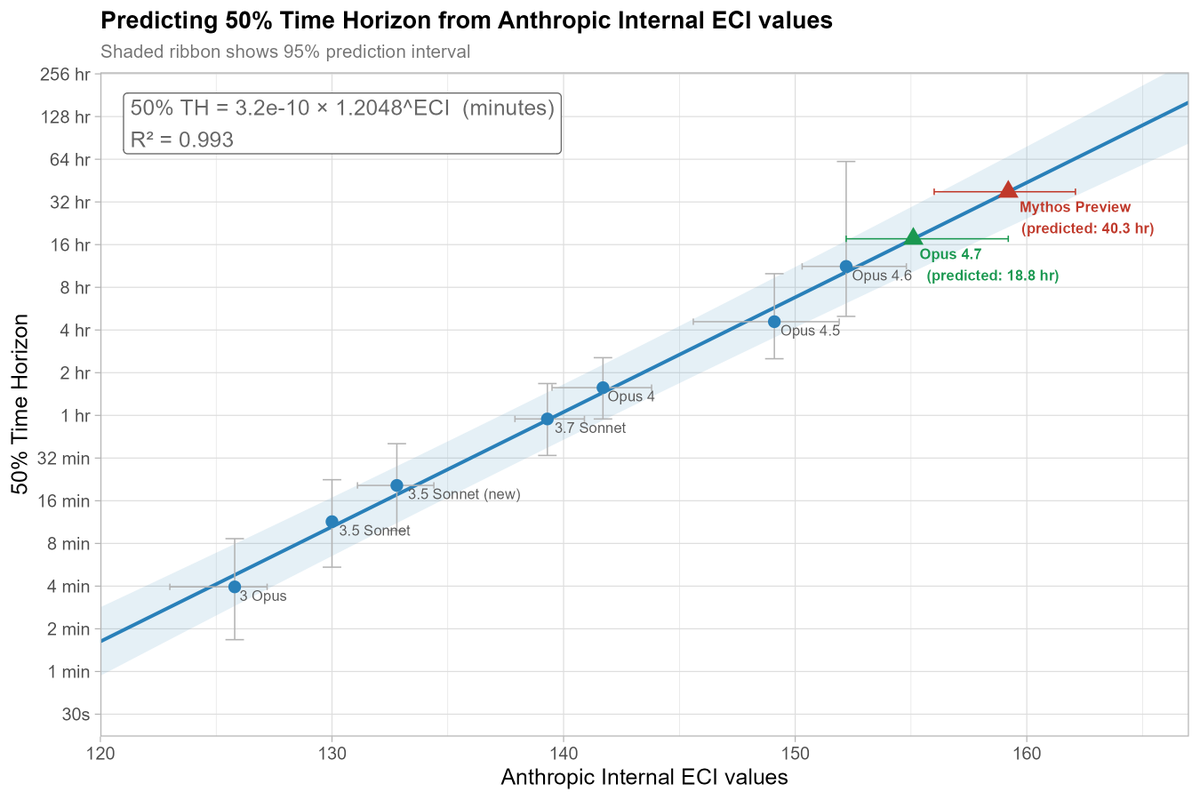
Apr 22
I used Anthropic's internal ECI values from the Opus 4.7 model card to predict the METR Time Horizon values they would receive.
This predicts Mythos will have a 50% TH of 40 hours, and Opus 4.7 19 hours. 80% THs are 5.5 and 2.5 hours respectively.
6
27
223
116,059
Apr 22
Notably both of these 50% TH values are above what I expect METR to be able to reliably measure with the TH1.1 task suite, as the longest task it contains is only 30 hours (and very few are beyond 16 hours).
They should be able to produce reasonable 80% TH results though.
1
23
3,005
Apr 22
For the full AECI values and some more information see my substack post: open.substack.com/pub/abstat…
11
2,379
Apr 17
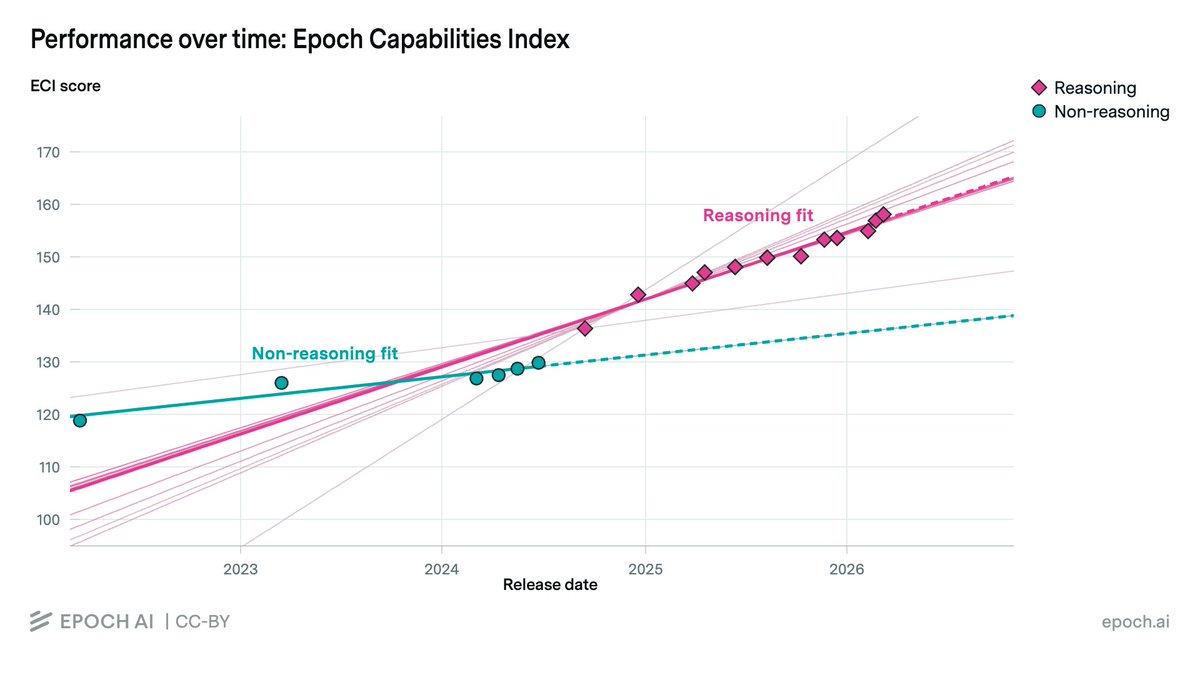
Interesting to work on this report with Epoch. We found that AI progress speeds have been accelerating since ~mid 2024 (on 3/4 of the metrics we considered).
Treating reasoning models as a trendbreak made the best predictions, but not enough data to be very confident.
Apr 17
Have AI capabilities accelerated?
On 3 out of the 4 AI capability metrics we investigated, we found strong evidence of acceleration, around when reasoning models emerged.
1
4
36
4,227
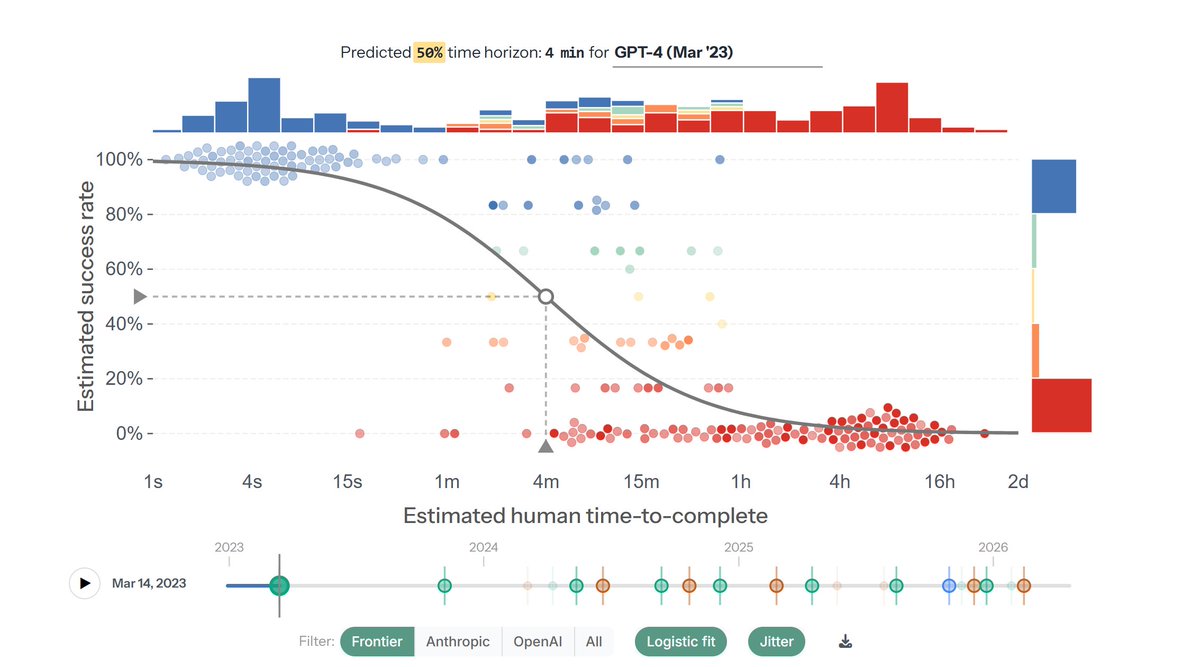
Apr 6
I made an update to the interactive task-success-rate plot for METR time horizon.
You can now see how the performance on the TH task suite has evolved over time by walking through model releases (with optional point jittering for increased visibility).
2
1
30
1,236
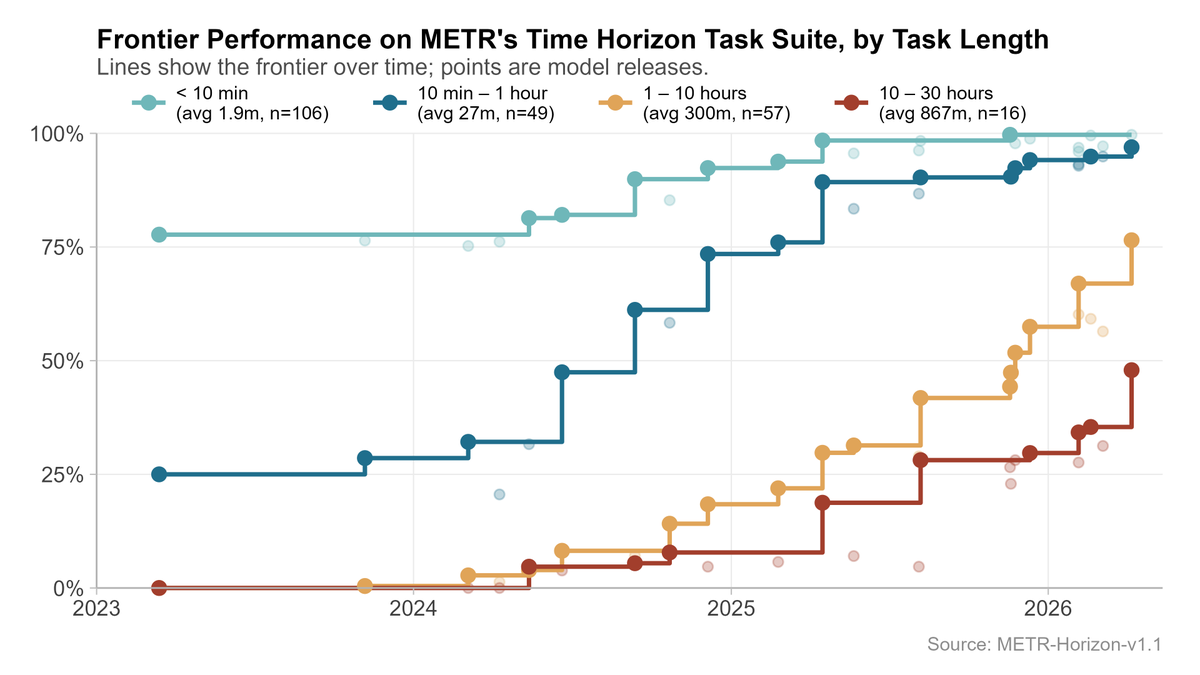
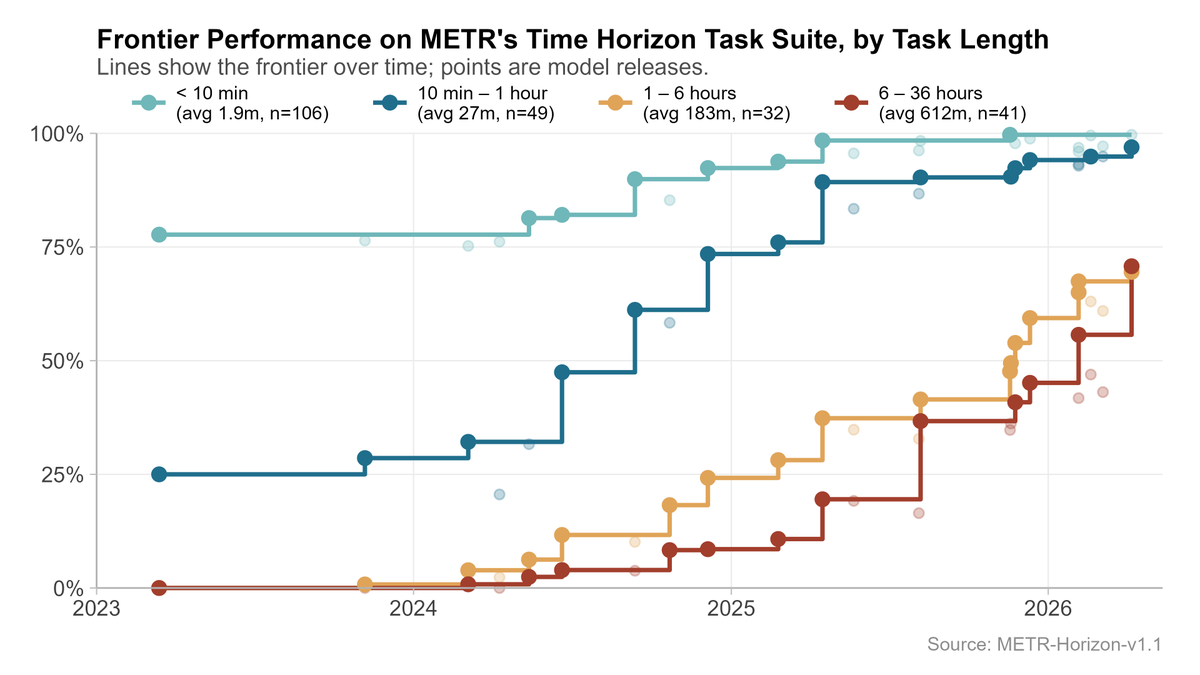
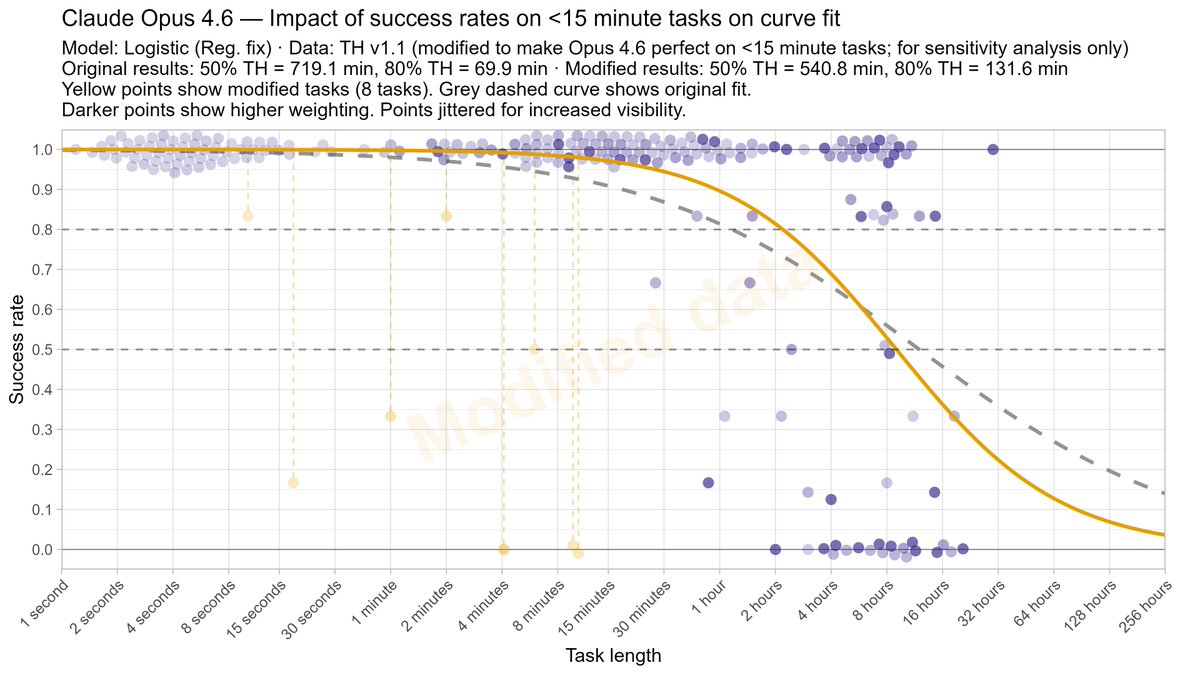
Mar 21
As METR’s Time Horizon task suite saturates, the results become more sensitive to analysis choices. I did a deep dive and explored how reasonable alternative modelling choices impact time horizon results.
3
9
112
14,365
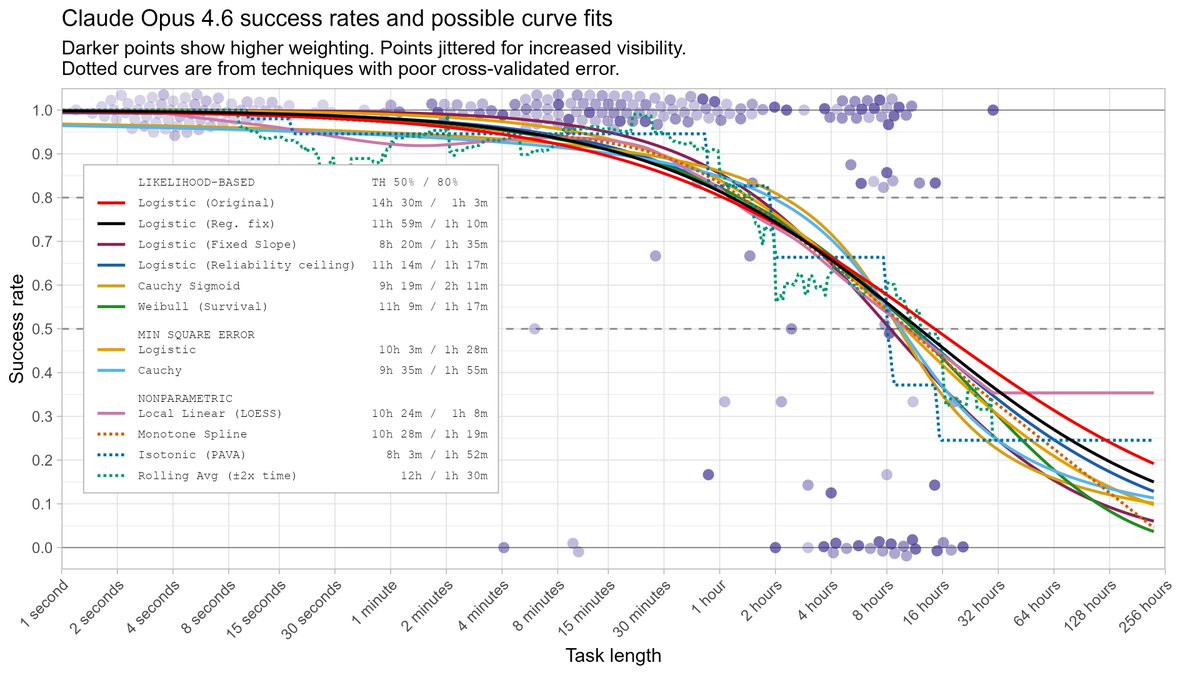
Mar 21
Some of the alternative analyses I considered included: using different curves to connect task length to success probability, including Weibull (survival) fits, and nonparametric approaches.
1
17
852